

NVIDIA Tesla P40 Graphic Card - 24 GB GDDR5 - Full-height - Dual Slot - 900-2G610-0000-000
Experience Maximum Inference Throughput
In the new era of AI and intelligent machines, deep learning is shaping our world like no other computing model in history. GPUs powered by the revolutionary NVIDIA Pascal™ architecture provide the computational engine for the new era of artificial intelligence, enabling amazing user experiences by accelerating deep learning applications at scale.
The NVIDIA Tesla P40 is purpose-built to deliver maximum throughput for deep learning deployment. With 47 TOPS (Tera-Operations Per Second) of inference performance and INT8 operations per GPU, a single server with 8 Tesla P40s delivers the performance of over 140 CPU servers.
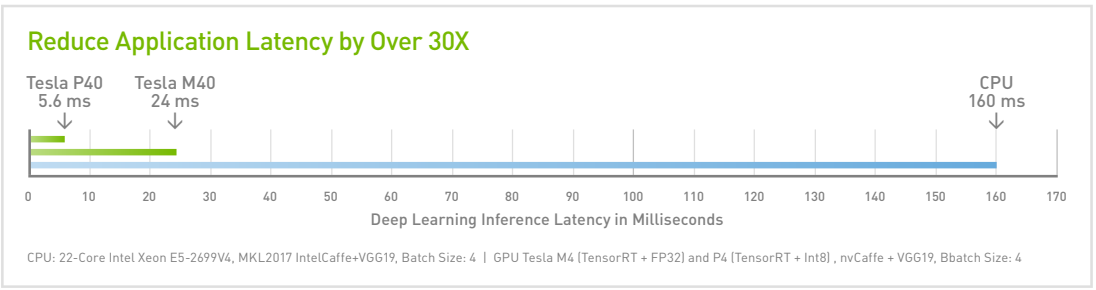
As models increase in accuracy and complexity, CPUs are no longer capable of delivering interactive user experience. The Tesla P40 delivers over 30X lower latency than a CPU for real-time responsiveness in even the most complex models.
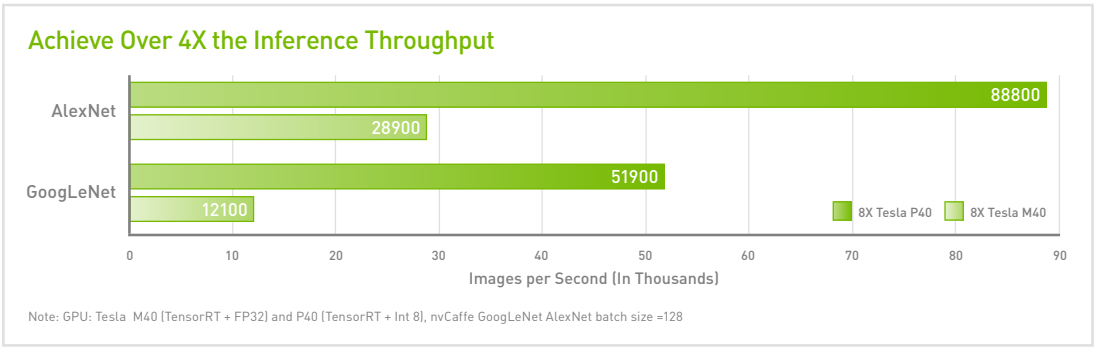
140X Higher Throughput To Keep Up With Exploding Data
The Tesla P40 is powered by the new Pascal architecture and delivers over 47 TOPS ofdeep learning inference performance. A single server with 8 Tesla P40s can replace up to 140 CPU-only servers for deep learning workloads,resulting in substantially higher throughput with lower acquisition cost.
Real-Time Inference
The Tesla P40 delivers up to 30X faster inference performance with INT8 operations for real-time responsiveness for even the most complex deep learning models.
Simplified Operations With A Single Training And Inference Platform
Today, deep learning models are trained on GPU servers but deployed in CPU servers for inference. The Tesla P40 offers a drastically simplified workflow, so organizations can use the same servers to iterate and deploy.
Faster Deployment With NVIDIA Deep Learning SDK
TensorRT included with NVIDIA Deep LearningSDK and Deep Stream SDK help customersseamlessly leverage inference capabilities like the new INT8 operations and video trans-coding.
» Click here to learn more about NVIDIA Tesla GPUsAbout
Experience Maximum Inference Throughput
In the new era of AI and intelligent machines, deep learning is shaping our world like no other computing model in history. GPUs powered by the revolutionary NVIDIA Pascal™ architecture provide the computational engine for the new era of artificial intelligence, enabling amazing user experiences by accelerating deep learning applications at scale.
The NVIDIA Tesla P40 is purpose-built to deliver maximum throughput for deep learning deployment. With 47 TOPS (Tera-Operations Per Second) of inference performance and INT8 operations per GPU, a single server with 8 Tesla P40s delivers the performance of over 140 CPU servers.
As models increase in accuracy and complexity, CPUs are no longer capable of delivering interactive user experience. The Tesla P40 delivers over 30X lower latency than a CPU for real-time responsiveness in even the most complex models.
140X Higher Throughput To Keep Up With Exploding Data
The Tesla P40 is powered by the new Pascal architecture and delivers over 47 TOPS ofdeep learning inference performance. A single server with 8 Tesla P40s can replace up to 140 CPU-only servers for deep learning workloads,resulting in substantially higher throughput with lower acquisition cost.
Real-Time Inference
The Tesla P40 delivers up to 30X faster inference performance with INT8 operations for real-time responsiveness for even the most complex deep learning models.
Simplified Operations With A Single Training And Inference Platform
Today, deep learning models are trained on GPU servers but deployed in CPU servers for inference. The Tesla P40 offers a drastically simplified workflow, so organizations can use the same servers to iterate and deploy.
Faster Deployment With NVIDIA Deep Learning SDK
TensorRT included with NVIDIA Deep LearningSDK and Deep Stream SDK help customersseamlessly leverage inference capabilities like the new INT8 operations and video trans-coding.
» Click here to learn more about NVIDIA Tesla GPUs