HPC
What is a Traditional HPC/AI Cluster?
February 10, 2021
6 min read

Let us define first what is not a cluster: It is not a single computer with multiple GPUs or CPU sockets.
The general classification of such a single server / system would be considered a compute node, more specifically, a GPU compute node, discussed later on.
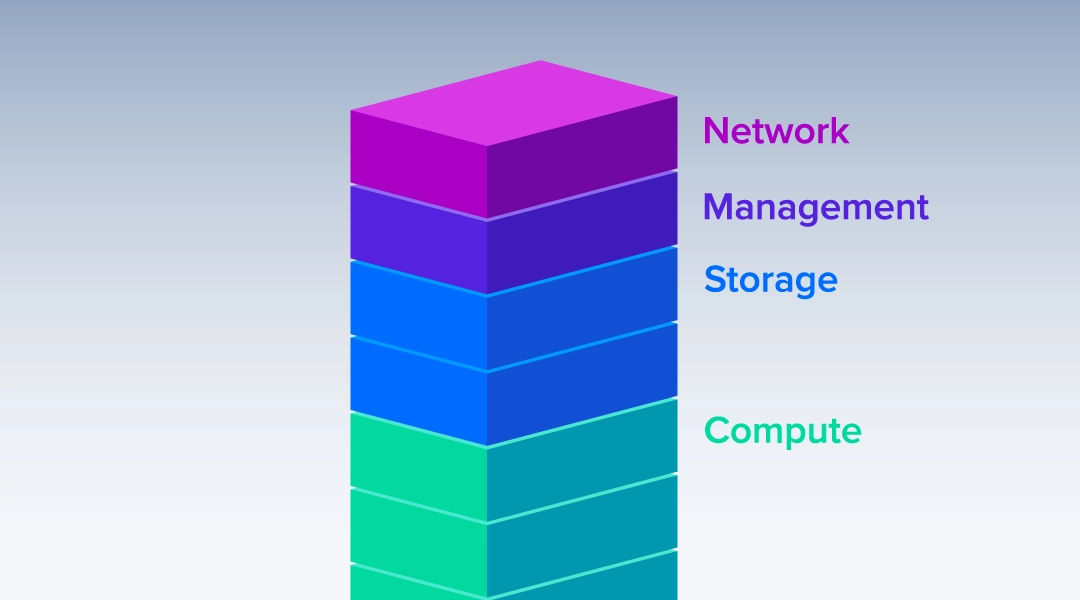
So, what is a cluster? A cluster is essentially a collection of computer systems interconnected together to provide an advanced and powerful turn-key solution to allow for the parallel processing of compute jobs like deep learning training, AMBER molecular dynamics simulation, or even some older CPU compute software like LAMMPS used in supercomputers and national labs. However, we can break down the cluster into five components:
1) Rack
2) Management Node
3) Compute Nodes
4) Storage
5) Network Switching
Interested in an HPC cluster?
A rack (short for rack enclosure) is the outer container/chassis/cabinet which houses the rackmount servers, switches, PDUs, cabling organized within. Racks can be half-sized like 24U, to 48U (a “U” or often referred to as “RU” is the unit of measure to define the “height” of a server which can fit into an enclosure.)

Exxact generally recommends a 42U rack, as the footprint is the same as a half-rack and allows for future scale up of additional systems to be added to the cluster.

A management node, often referred to as a login node, or head node, is the main orchestrator of the cluster. This is the highly-available system providing a single system to log into so a student, researcher can login, run and or schedule a job for their project.
A great portion of how the management node functions is based on the cluster management software installed like Bright Cluster Management Software or often simply referred to as "Bright". Bright helps keep track of nodes, allows for the commissioning/imaging of new nodes added, and above all else, essentially ties all the systems together.
An example management node scenario:
Say a subordinate node (compute node) is powered on within the cluster. This subordinate node would boot via PXE boot within the management network to the management node, and the management node would recognize, via MAC address, the compute node's respective role. The management node would deploy or image the respective saved boot image back to the the subordinate node; the subordinate node would then boot, setup software and networking per the specific boot image, and be ready to accept incoming jobs to run compute on.
Compute nodes are the “worker” systems which, by nature, are the systems doing the heavy lifting compute.
These can be broken down into two main types:
1) CPU Nodes, and;
2) GPU compute nodes.
CPU nodes generally use large amounts of CPU cores like AMD EPYC CPUs, high frequency (fast) compute cores, or a combination of both.
GPU nodes can be equipped with GPUs, FPGAs or other parallel accelerators, and rely on the massively parallel compute power and memory these enterprise-class devices.
Many research groups will have a rack populated with both CPU and GPU compute nodes where the total cluster can be flexible and accommodating to specific use-cases. This way the cluster can be flexible and service multiple users and multiple applications that require a wider variety of hardware. For example: CPU-accelerated applications can have high-performance CPU nodes to run on, while GPU accelerated applications have GPU nodes to run on.

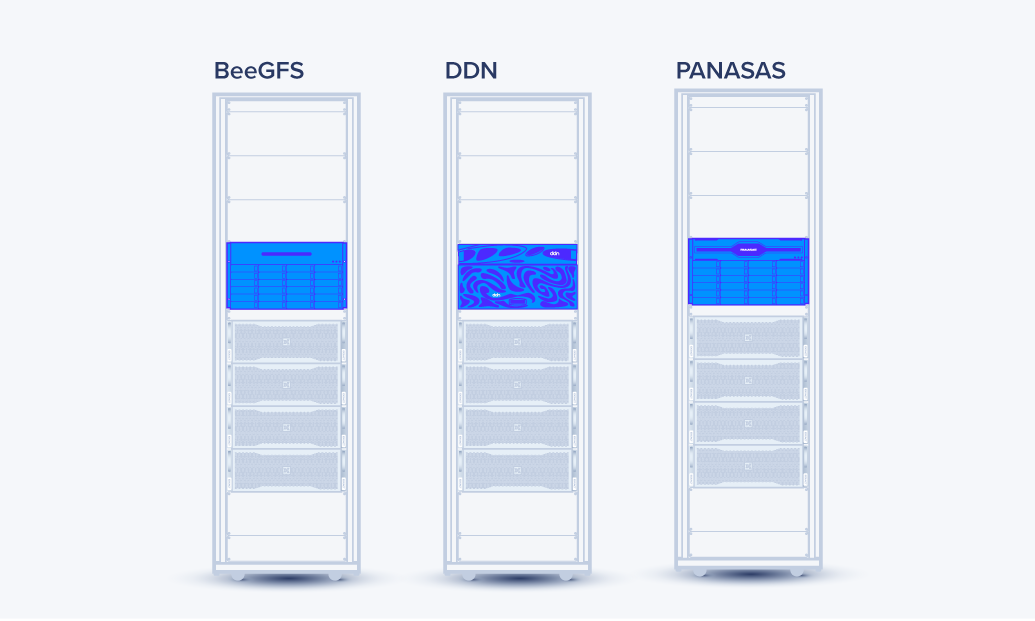
As the name implies, storage is the general shared storage pool which can house results data, images, code, or anything else particular to a research group. Storage can be either simple NAS (Networked Attached Storage) mounts, or more complex high-speed, highly-available parallel storage components like those solutions of DDN, Panasas, or even an Exxact-customized BeeGFS parallel storage cluster.
Each of these components can be explained and dissected further in their own rights. Typically, Exxact recommends a single shared storage repository / mount which can be even combined within the management node and is often the simplest implementation to ensure a central shared storage space.
Server Solutions for Longer Term Storage Applications
Networking within an cluster generally takes two forms:
1) management network, and;
2) internal network, and optionally an hsnetwork (highspeed) (10/25/40/100/200GBE, IB, etc).
The management networking and infrastructure is generally low-cost and inexpensive Gigabit networking used within the Cluster Management software to allow the systems to boot, provision, and internal management (think IPMI) of all the management node and compute nodes.
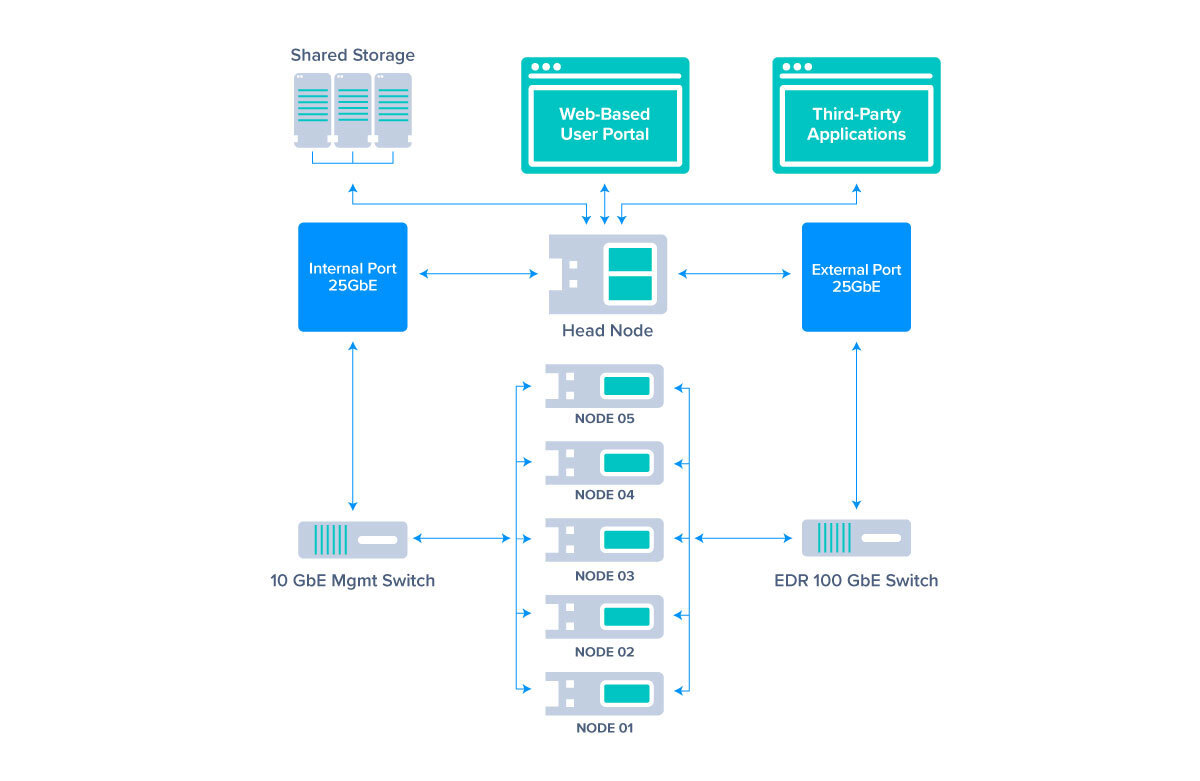
Internal networking is generally the networking which interconnects the management node with the compute nodes and is the main network for data being transferred in-between compute nodes and the management node during running jobs. Typically, this can be 10GBase-T (or minimally 1GbE for AMBER clusters) to high speed interconnect and fabric like 100GbE or InfiniBand. With this high-speed network, this usually has the entry point (or uplink) from an external network so researchers and students to log in remotely to the cluster to run or otherwise schedule their jobs.
In all, clusters are highly customizable and are generally tailored to research groups or institutions.
Feel free to contact Exxact today to learn how our engineers can work to optimize and architect the best cluster solution to fit your needs.

Let us define first what is not a cluster: It is not a single computer with multiple GPUs or CPU sockets.
The general classification of such a single server / system would be considered a compute node, more specifically, a GPU compute node, discussed later on.
So, what is a cluster? A cluster is essentially a collection of computer systems interconnected together to provide an advanced and powerful turn-key solution to allow for the parallel processing of compute jobs like deep learning training, AMBER molecular dynamics simulation, or even some older CPU compute software like LAMMPS used in supercomputers and national labs. However, we can break down the cluster into five components:
1) Rack
2) Management Node
3) Compute Nodes
4) Storage
5) Network Switching
Interested in an HPC cluster?
A rack (short for rack enclosure) is the outer container/chassis/cabinet which houses the rackmount servers, switches, PDUs, cabling organized within. Racks can be half-sized like 24U, to 48U (a “U” or often referred to as “RU” is the unit of measure to define the “height” of a server which can fit into an enclosure.)
Exxact generally recommends a 42U rack, as the footprint is the same as a half-rack and allows for future scale up of additional systems to be added to the cluster.
A management node, often referred to as a login node, or head node, is the main orchestrator of the cluster. This is the highly-available system providing a single system to log into so a student, researcher can login, run and or schedule a job for their project.
A great portion of how the management node functions is based on the cluster management software installed like Bright Cluster Management Software or often simply referred to as "Bright". Bright helps keep track of nodes, allows for the commissioning/imaging of new nodes added, and above all else, essentially ties all the systems together.
An example management node scenario:
Say a subordinate node (compute node) is powered on within the cluster. This subordinate node would boot via PXE boot within the management network to the management node, and the management node would recognize, via MAC address, the compute node's respective role. The management node would deploy or image the respective saved boot image back to the the subordinate node; the subordinate node would then boot, setup software and networking per the specific boot image, and be ready to accept incoming jobs to run compute on.
Compute nodes are the “worker” systems which, by nature, are the systems doing the heavy lifting compute.
These can be broken down into two main types:
1) CPU Nodes, and;
2) GPU compute nodes.
CPU nodes generally use large amounts of CPU cores like AMD EPYC CPUs, high frequency (fast) compute cores, or a combination of both.
GPU nodes can be equipped with GPUs, FPGAs or other parallel accelerators, and rely on the massively parallel compute power and memory these enterprise-class devices.
Many research groups will have a rack populated with both CPU and GPU compute nodes where the total cluster can be flexible and accommodating to specific use-cases. This way the cluster can be flexible and service multiple users and multiple applications that require a wider variety of hardware. For example: CPU-accelerated applications can have high-performance CPU nodes to run on, while GPU accelerated applications have GPU nodes to run on.
As the name implies, storage is the general shared storage pool which can house results data, images, code, or anything else particular to a research group. Storage can be either simple NAS (Networked Attached Storage) mounts, or more complex high-speed, highly-available parallel storage components like those solutions of DDN, Panasas, or even an Exxact-customized BeeGFS parallel storage cluster.
Each of these components can be explained and dissected further in their own rights. Typically, Exxact recommends a single shared storage repository / mount which can be even combined within the management node and is often the simplest implementation to ensure a central shared storage space.
Server Solutions for Longer Term Storage Applications
Networking within an cluster generally takes two forms:
1) management network, and;
2) internal network, and optionally an hsnetwork (highspeed) (10/25/40/100/200GBE, IB, etc).
The management networking and infrastructure is generally low-cost and inexpensive Gigabit networking used within the Cluster Management software to allow the systems to boot, provision, and internal management (think IPMI) of all the management node and compute nodes.
Internal networking is generally the networking which interconnects the management node with the compute nodes and is the main network for data being transferred in-between compute nodes and the management node during running jobs. Typically, this can be 10GBase-T (or minimally 1GbE for AMBER clusters) to high speed interconnect and fabric like 100GbE or InfiniBand. With this high-speed network, this usually has the entry point (or uplink) from an external network so researchers and students to log in remotely to the cluster to run or otherwise schedule their jobs.
In all, clusters are highly customizable and are generally tailored to research groups or institutions.
Feel free to contact Exxact today to learn how our engineers can work to optimize and architect the best cluster solution to fit your needs.
