Artificial Intelligence
Examining the Transformer Architecture – Part 2: A Brief Description of How Transformers Work
June 3, 2019
8 min read


This post was written by Nityesh Agarwal in collaboration with and sponsorship of Exxact (@Exxactcorp).
As we learned in Part 1, The GPT-2 is based on the Transformer, which is being hailed as the new NLP standard, replacing Recurrent Neural Networks. Some commentators believe that the Transformer will become the dominant NLP deep learning architecture of 2019. Let's now take a brief look under the hood to see what makes them tick.
This architecture was first proposed in the seminal paper — Attention is all you need from Google in the mid 2017.
Since that short amount of time, this architecture has been used in producing state-of-the-art results in 2 papers — One being GPT/GPT-2 and the other was BERT.
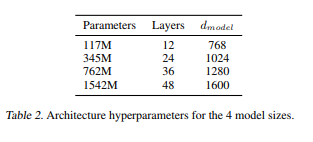
The smallest one corresponds to the GPT model; the second smallest one is equivalent to the largest model in BERT; the largest one, which is more than an order of magnitude larger, corresponds to the GPT-2 model
Now let’s look at the architecture:
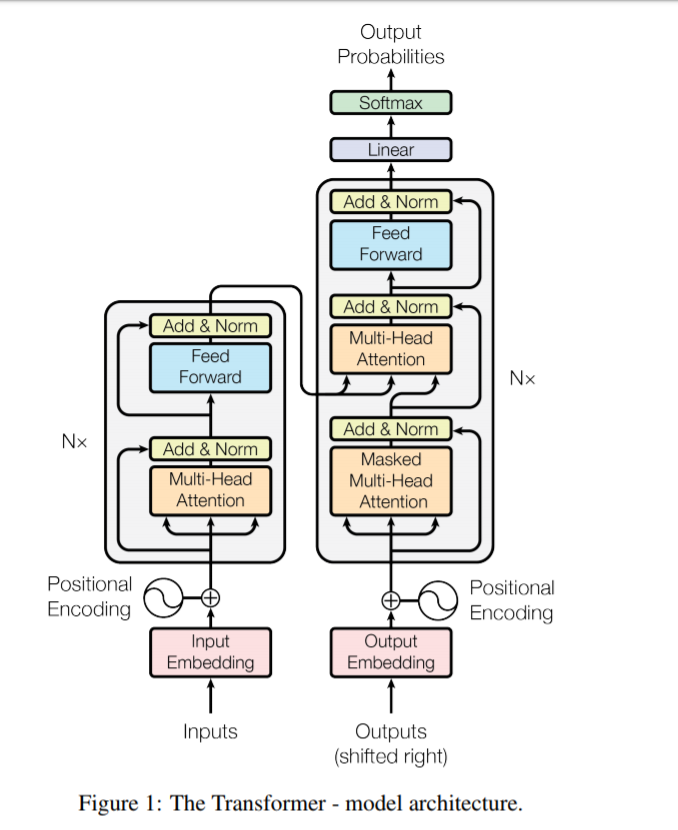
The Transformer architecture as present in the Attention is all you need paper by Google
The first thing that we can see is that it has a sequence-to-sequence encoder-decoder architecture. Much of the literature on Transformers that is present on the Internet uses this very architecture to explain Transformers. But this is not the one used in Open AI’s GPT model (or the GPT-2 model, which was just a larger version of its predecessor).
The GPT is a 12-layer decoder only transformer with 117M parameters.
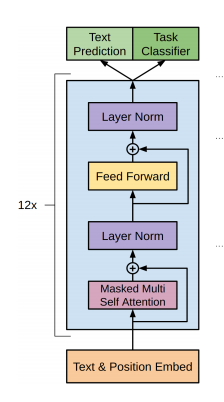
The Transformer architecture used in the GPT paper from Open AI
GPT (and the smaller released version of GPT-2) have 12 layers of transformers, each with 12 independent attention mechanisms, called “heads”; the result is 12 x 12 = 144 distinct attention patterns. Each of these attention patterns corresponds to a linguistic property captured by the model.
As we can see in the above transformer architectures, attention is an important part of the Transformer. In fact, that would be an understatement. Attention is what makes the transformer work. So, let’s get an brief introduction to attention.

RNN units would encode the input up until timestamp t into one hidden vector ht which would then be passed to the next timestamp (or to the decoder in case of a sequence-to-sequence model). With an attention mechanism we no longer try encode the full source sentence into a fixed-length vector. Rather, we allow the decoder to “attend” to different parts of the source sentence at each step of the output generation. Importantly, we let the model learn what to attend to based on the input sentence and what it has produced so far.
So let’s say we wanted to translate “L’ accord sur la zone économique européenne a été signé en aout 1992.” (French) to English which is “The agreement on the European Economic Area was signed in August 1992.”
The graph below shows what an Attention model learned to attend to for each word of translation that it generated.

Notice how it is mostly just linear except when translating “zone économique européenne” to “European economic zone”. It correctly attends in the reverse order in that case.
Such an ability allows attention to learn long range dependencies.
As mentioned before, some practitioners believe that we are now witnessing the fall of RNN/LSTM. Since their introduction in the year 2014, they have been the default go-to architecture for all the NLP tasks ranging from language modelling, machine translation, text summarization, image/video captioning, speech to text conversion and more.
But RNN and its variations had 2 major shortcomings:
One of the primary appeals of RNNs is that they are able to use their reasoning about previous events in the film to inform later ones. But this also turns out to be one of their major shortcomings.
The decoder is supposed to generate a translation solely based on the last hidden state (h3) from the encoder. This vector must encode everything we need to know about the source sentence. It must fully capture its meaning.
As the gap between 2 words grows, the RNN seems to “forget” the previous words.
Long Short Term Memory units (LSTMs) and Gated Recurrent Units (GRUs) provide a hackish solution to this problem by using memory unit(/s) controlled by gates which allow them to fetch information from an earlier past.
RNNs aren’t able to process inputs in parallel. They are networks with loops in them, allowing information to persist.
In the above diagram, a chunk of neural network, A, looks at some input xt and outputs a value ht. A loop allows information to be passed from one step of the network to the next. This means that they can only handle one input unit at a time.
That is why they can’t make use of the immensely powerful GPUs’ parallel computing ability. Such GPUs have allowed CNNs to train on a HUGE amount of data and grow to absolutely massive sizes. RNNS or
LSTMs or any of their variants are inherently inept at leveraging this means.
Transformers excel at both of these tasks.
Deep Learning Workstations from Exxact featuring Quadro RTX 8000’s are perfectly suited to train even large transformer models. Each Quadro RTX 8000 has 48 GB GPU memory, and a pair can be connected with NVLink to give 96 GB total GPU Memory to Fit massive transformer models.
The Transformer architecture allows the creation of NLP models trained on absolutely huge datasets as we saw in this article. Such models are not feasible to be trained by everyone, just as you wouldn’t expect to train a VGG Net from scratch on the ImageNet dataset. Hence, comes the era of pre-trained language models.
The weights learned by such massive pre-trained models can later be reused for specific tasks by fine-tuning them to the specific dataset. This would allow us to do transfer learning by capturing the lower-level intricacies of the language and simply “plugging” it to suit our specific task.
Transformers present the next front in NLP. In less than a couple of years since its introduction, this new architectural trend has surpassed the feats of RNN-based architectures. This exciting pace of invention is perhaps the best part of being early to a new field like Deep Learning!
Read more! Here is the Final Part of the Series.

This post was written by Nityesh Agarwal in collaboration with and sponsorship of Exxact (@Exxactcorp).
As we learned in Part 1, The GPT-2 is based on the Transformer, which is being hailed as the new NLP standard, replacing Recurrent Neural Networks. Some commentators believe that the Transformer will become the dominant NLP deep learning architecture of 2019. Let's now take a brief look under the hood to see what makes them tick.
This architecture was first proposed in the seminal paper — Attention is all you need from Google in the mid 2017.
Since that short amount of time, this architecture has been used in producing state-of-the-art results in 2 papers — One being GPT/GPT-2 and the other was BERT.
The smallest one corresponds to the GPT model; the second smallest one is equivalent to the largest model in BERT; the largest one, which is more than an order of magnitude larger, corresponds to the GPT-2 model
Now let’s look at the architecture:
The Transformer architecture as present in the Attention is all you need paper by Google
The first thing that we can see is that it has a sequence-to-sequence encoder-decoder architecture. Much of the literature on Transformers that is present on the Internet uses this very architecture to explain Transformers. But this is not the one used in Open AI’s GPT model (or the GPT-2 model, which was just a larger version of its predecessor).
The GPT is a 12-layer decoder only transformer with 117M parameters.
The Transformer architecture used in the GPT paper from Open AI
GPT (and the smaller released version of GPT-2) have 12 layers of transformers, each with 12 independent attention mechanisms, called “heads”; the result is 12 x 12 = 144 distinct attention patterns. Each of these attention patterns corresponds to a linguistic property captured by the model.
As we can see in the above transformer architectures, attention is an important part of the Transformer. In fact, that would be an understatement. Attention is what makes the transformer work. So, let’s get an brief introduction to attention.
RNN units would encode the input up until timestamp t into one hidden vector ht which would then be passed to the next timestamp (or to the decoder in case of a sequence-to-sequence model). With an attention mechanism we no longer try encode the full source sentence into a fixed-length vector. Rather, we allow the decoder to “attend” to different parts of the source sentence at each step of the output generation. Importantly, we let the model learn what to attend to based on the input sentence and what it has produced so far.
So let’s say we wanted to translate “L’ accord sur la zone économique européenne a été signé en aout 1992.” (French) to English which is “The agreement on the European Economic Area was signed in August 1992.”
The graph below shows what an Attention model learned to attend to for each word of translation that it generated.
Notice how it is mostly just linear except when translating “zone économique européenne” to “European economic zone”. It correctly attends in the reverse order in that case.
Such an ability allows attention to learn long range dependencies.
As mentioned before, some practitioners believe that we are now witnessing the fall of RNN/LSTM. Since their introduction in the year 2014, they have been the default go-to architecture for all the NLP tasks ranging from language modelling, machine translation, text summarization, image/video captioning, speech to text conversion and more.
But RNN and its variations had 2 major shortcomings:
One of the primary appeals of RNNs is that they are able to use their reasoning about previous events in the film to inform later ones. But this also turns out to be one of their major shortcomings.
The decoder is supposed to generate a translation solely based on the last hidden state (h3) from the encoder. This vector must encode everything we need to know about the source sentence. It must fully capture its meaning.
As the gap between 2 words grows, the RNN seems to “forget” the previous words.
Long Short Term Memory units (LSTMs) and Gated Recurrent Units (GRUs) provide a hackish solution to this problem by using memory unit(/s) controlled by gates which allow them to fetch information from an earlier past.
RNNs aren’t able to process inputs in parallel. They are networks with loops in them, allowing information to persist.
In the above diagram, a chunk of neural network, A, looks at some input xt and outputs a value ht. A loop allows information to be passed from one step of the network to the next. This means that they can only handle one input unit at a time.
That is why they can’t make use of the immensely powerful GPUs’ parallel computing ability. Such GPUs have allowed CNNs to train on a HUGE amount of data and grow to absolutely massive sizes. RNNS or
LSTMs or any of their variants are inherently inept at leveraging this means.
Transformers excel at both of these tasks.
Deep Learning Workstations from Exxact featuring Quadro RTX 8000’s are perfectly suited to train even large transformer models. Each Quadro RTX 8000 has 48 GB GPU memory, and a pair can be connected with NVLink to give 96 GB total GPU Memory to Fit massive transformer models.
The Transformer architecture allows the creation of NLP models trained on absolutely huge datasets as we saw in this article. Such models are not feasible to be trained by everyone, just as you wouldn’t expect to train a VGG Net from scratch on the ImageNet dataset. Hence, comes the era of pre-trained language models.
The weights learned by such massive pre-trained models can later be reused for specific tasks by fine-tuning them to the specific dataset. This would allow us to do transfer learning by capturing the lower-level intricacies of the language and simply “plugging” it to suit our specific task.
Transformers present the next front in NLP. In less than a couple of years since its introduction, this new architectural trend has surpassed the feats of RNN-based architectures. This exciting pace of invention is perhaps the best part of being early to a new field like Deep Learning!
Read more! Here is the Final Part of the Series.
