Benchmarks
NVIDIA RTX A4500 BERT Large Fine Tuning Benchmarks in TensorFlow
February 17, 2022
13 min read


For this post, we measured fine-tuning performance (training and inference) for the BERT implementation of TensorFlow on NVIDIA RTX A4500 GPUs. For testing we used an Exxact Valence Workstation fitted with 8x RTX A4500 GPUs with 20GB GPU memory per GPU.
Benchmark scripts we used for evaluation were the finetune_train_benchmark.sh and finetune_inference_benchmark.sh from NVIDIA NGC Repository BERT for TensorFlow. We made slight modifications to the training benchmark script to get the larger batch size numbers.
The script runs multiple tests on the SQuAD v1.1 dataset using batch sizes 1, 2, 4, and 8. Inferencing tests were conducted using a 1x GPU configurations on BERT Large. In addition, we ran all benchmarks using TensorFlow's XLA across the board.
Interested in getting faster results?
Learn more about Exxact AI workstations to do NLP training on starting around $5,500
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.4 |
| BERT Dataset | squad v1 |
| TensorFlow | 2.40 |
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
Raw Data
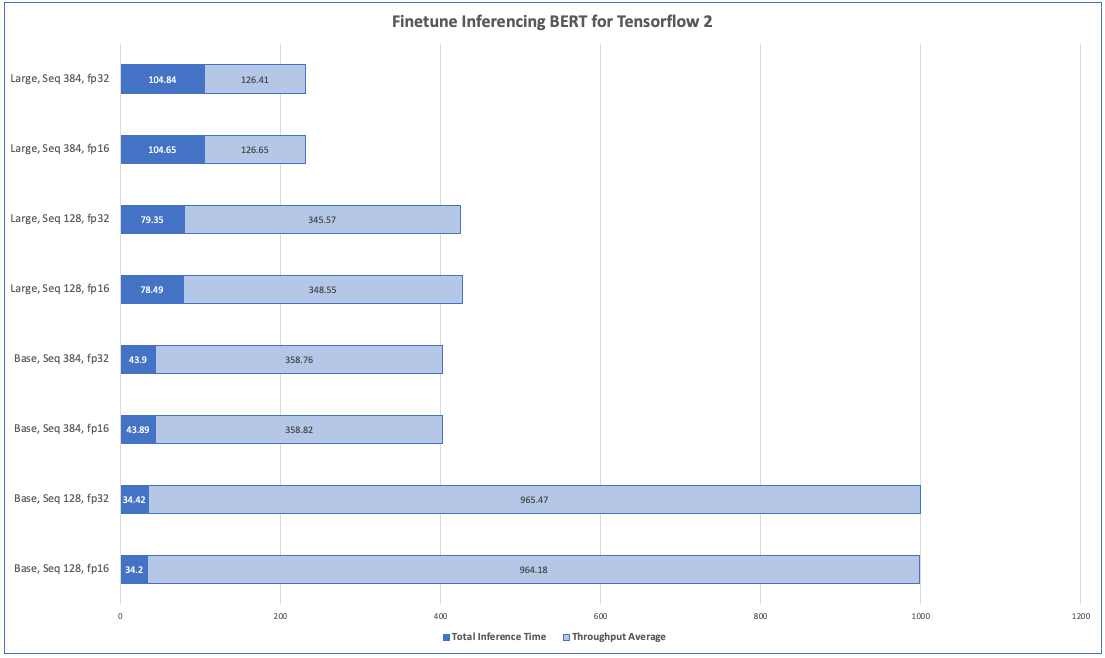
| Model | Sequence-Length | Batch-size | Precision | Total-Inference-Time | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-50%(ms) | Latency-90%(ms) | Latency-95%(ms) | iLatency-99%(ms) | Latency-100%(ms) |
| base | 128 | 1 | fp16 | 25.98 | 186.13 | 8.94 | 5.56 | 6.34 | 6.46 | 6.8 | 6387.51 |
| base | 128 | 1 | fp32 | 20.34 | 188.55 | 8.38 | 5.48 | 6.32 | 6.48 | 6.85 | 5501.44 |
| base | 128 | 2 | fp16 | 20.47 | 364.38 | 8.84 | 5.67 | 6.2 | 6.32 | 6.78 | 5679.04 |
| base | 128 | 2 | fp32 | 19.65 | 389.55 | 8.47 | 5.3 | 5.89 | 5.99 | 6.18 | 5654.98 |
| base | 128 | 4 | fp16 | 26.39 | 695.64 | 11.55 | 5.79 | 6.24 | 6.36 | 6.9 | 5774.98 |
| base | 128 | 4 | fp32 | 26.41 | 696.75 | 11.54 | 5.76 | 6.22 | 6.41 | 6.86 | 5767.47 |
| base | 128 | 8 | fp16 | 34.2 | 964.18 | 13.57 | 8.27 | 8.72 | 8.94 | 9.52 | 5876.52 |
| base | 128 | 8 | fp32 | 34.42 | 965.47 | 13.6 | 8.28 | 8.64 | 8.89 | 9.44 | 5899.06 |
| base | 384 | 1 | fp16 | 17.03 | 177.1 | 11.46 | 5.65 | 6.11 | 6.25 | 6.7 | 6059.77 |
| base | 384 | 1 | fp32 | 17.2 | 176.11 | 11.49 | 5.66 | 6.15 | 6.29 | 6.77 | 6051.43 |
| base | 384 | 2 | fp16 | 25.64 | 239.89 | 19.3 | 8.31 | 8.84 | 9.13 | 9.84 | 6456.22 |
| base | 384 | 2 | fp32 | 25.6 | 240.18 | 19.26 | 8.29 | 8.8 | 9.06 | 9.77 | 6447.57 |
| base | 384 | 4 | fp16 | 31.28 | 305.32 | 24.29 | 13.09 | 13.62 | 13.85 | 14.97 | 6660.95 |
| base | 384 | 4 | fp32 | 31.11 | 304.43 | 24.28 | 13.13 | 13.6 | 13.8 | 14.98 | 6639.34 |
| base | 384 | 8 | fp16 | 43.89 | 358.82 | 34.29 | 22.27 | 22.79 | 23.1 | 24.51 | 7002.83 |
| base | 384 | 8 | fp32 | 43.9 | 358.76 | 34.33 | 22.26 | 22.8 | 23.11 | 24.35 | 7031.13 |
| large | 128 | 1 | fp16 | 47.42 | 103.62 | 15.96 | 9.42 | 10.95 | 11.16 | 11.67 | 11340.21 |
| large | 128 | 1 | fp32 | 36.28 | 108.7 | 15.52 | 8.91 | 10.12 | 10.4 | 10.96 | 11350.15 |
| large | 128 | 2 | fp16 | 38.82 | 180.4 | 17.77 | 11.09 | 11.91 | 12.05 | 12.44 | 11356.99 |
| large | 128 | 2 | fp32 | 39.12 | 177.62 | 17.97 | 11.45 | 11.98 | 12.13 | 12.79 | 11389.43 |
| large | 128 | 4 | fp16 | 58.85 | 253.71 | 27.84 | 15.94 | 16.48 | 16.65 | 17.52 | 11607 |
| large | 128 | 4 | fp32 | 57.8 | 261.94 | 27.35 | 15.01 | 16.17 | 16.35 | 17.01 | 11606.73 |
| large | 128 | 8 | fp16 | 78.49 | 348.55 | 34.15 | 22.89 | 23.82 | 24.05 | 24.71 | 11839.75 |
| large | 128 | 8 | fp32 | 79.35 | 345.57 | 34.53 | 23.22 | 23.96 | 24.19 | 24.88 | 12047.05 |
| large | 384 | 1 | fp16 | 34.49 | 77.09 | 24.99 | 12.98 | 13.76 | 13.89 | 14.59 | 12534.02 |
| large | 384 | 1 | fp32 | 33.95 | 79.81 | 24.49 | 12.34 | 13.35 | 13.51 | 14.09 | 12472.18 |
| large | 384 | 2 | fp16 | 54.4 | 97.77 | 44.04 | 20.34 | 21.21 | 21.38 | 22.2 | 13302.25 |
| large | 384 | 2 | fp32 | 53.88 | 98.22 | 43.83 | 20.12 | 21.18 | 21.38 | 22.19 | 13331.07 |
| large | 384 | 4 | fp16 | 68.97 | 118.22 | 57.65 | 33.95 | 34.44 | 34.62 | 35.31 | 13713.5 |
| large | 384 | 4 | fp32 | 69.14 | 117.88 | 57.75 | 34.07 | 34.59 | 34.78 | 35.73 | 13693.18 |
| large | 384 | 8 | fp16 | 104.65 | 126.65 | 88.76 | 63.22 | 63.87 | 64.17 | 65.32 | 14498.6 |
| large | 384 | 8 | fp32 | 104.84 | 126.41 | 89 | 63.33 | 64.11 | 64.4 | 65.53 | 14539.54 |
Data Chart
Raw Data
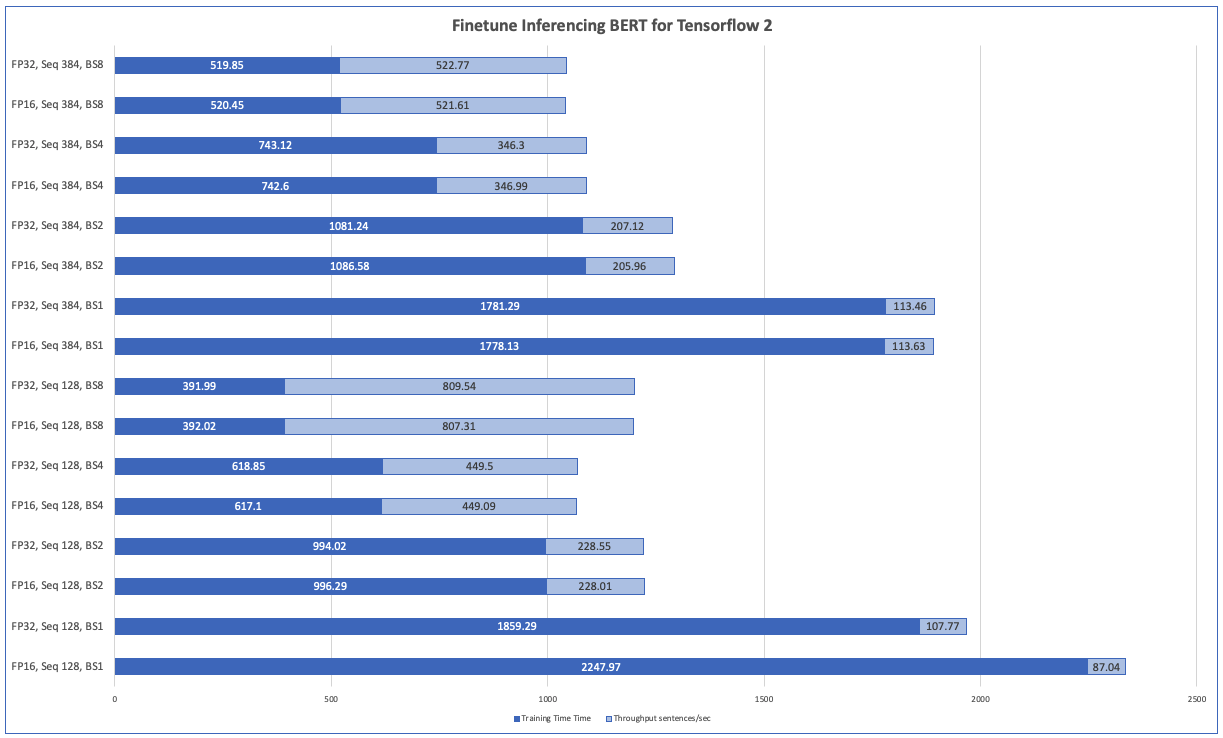
| Training Time Hours | Throughput sentences/sec | |
|---|---|---|
| FP16, Seq 128, BS1 | 2247.97 | 87.04 |
| FP32, Seq 128, BS1 | 1859.29 | 107.77 |
| FP16, Seq 128, BS2 | 996.29 | 228.01 |
| FP32, Seq 128, BS2 | 994.02 | 228.55 |
| FP16, Seq 128, BS4 | 617.1 | 449.09 |
| FP32, Seq 128, BS4 | 618.85 | 449.5 |
| FP16, Seq 128, BS8 | 392.02 | 807.31 |
| FP32, Seq 128, BS8 | 391.99 | 809.54 |
| FP16, Seq 384, BS1 | 1778.13 | 113.63 |
| FP32, Seq 384, BS1 | 1781.29 | 113.46 |
| FP16, Seq 384, BS2 | 1086.58 | 205.96 |
| FP32, Seq 384, BS2 | 1081.24 | 207.12 |
| FP16, Seq 384, BS4 | 742.6 | 346.99 |
| FP32, Seq 384, BS4 | 743.12 | 346.3 |
| FP16, Seq 384, BS8 | 520.45 | 521.61 |
| FP32, Seq 384, BS8 | 519.85 | 522.77 |
Data Chart
NVIDIA RTX A4500 Series GPUs
| GPU Features | NVIDIA RTX A4500 |
|---|---|
| GPU Memory | 20GB GDDR6 with error-correction code (ECC) |
| Display Ports | 4x DisplayPort 1.4 |
| Max Power Consumption | 2000 W |
| Graphics Bus | PCI Express Gen 4 x 16 |
| Form Factor | 4.4” (H) x 10.5” (L) Dual Slot |
| Thermal | Active |
| NVLink | 2-way Low-profile (2-slot and 3-slot bridges) |
| VR Ready | Yes |
Exxact Workstation System Specs
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.2 |
| BERT Dataset | squad v1 |
Have any questions?
Contact Exxact Today
For this post, we measured fine-tuning performance (training and inference) for the BERT implementation of TensorFlow on NVIDIA RTX A4500 GPUs. For testing we used an Exxact Valence Workstation fitted with 8x RTX A4500 GPUs with 20GB GPU memory per GPU.
Benchmark scripts we used for evaluation were the finetune_train_benchmark.sh and finetune_inference_benchmark.sh from NVIDIA NGC Repository BERT for TensorFlow. We made slight modifications to the training benchmark script to get the larger batch size numbers.
The script runs multiple tests on the SQuAD v1.1 dataset using batch sizes 1, 2, 4, and 8. Inferencing tests were conducted using a 1x GPU configurations on BERT Large. In addition, we ran all benchmarks using TensorFlow's XLA across the board.
Interested in getting faster results?
Learn more about Exxact AI workstations to do NLP training on starting around $5,500
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.4 |
| BERT Dataset | squad v1 |
| TensorFlow | 2.40 |
FP = Floating Point Precision, Seq = Sequence Length, BS = Batch Size
Raw Data
| Model | Sequence-Length | Batch-size | Precision | Total-Inference-Time | Throughput-Average(sent/sec) | Latency-Average(ms) | Latency-50%(ms) | Latency-90%(ms) | Latency-95%(ms) | iLatency-99%(ms) | Latency-100%(ms) |
| base | 128 | 1 | fp16 | 25.98 | 186.13 | 8.94 | 5.56 | 6.34 | 6.46 | 6.8 | 6387.51 |
| base | 128 | 1 | fp32 | 20.34 | 188.55 | 8.38 | 5.48 | 6.32 | 6.48 | 6.85 | 5501.44 |
| base | 128 | 2 | fp16 | 20.47 | 364.38 | 8.84 | 5.67 | 6.2 | 6.32 | 6.78 | 5679.04 |
| base | 128 | 2 | fp32 | 19.65 | 389.55 | 8.47 | 5.3 | 5.89 | 5.99 | 6.18 | 5654.98 |
| base | 128 | 4 | fp16 | 26.39 | 695.64 | 11.55 | 5.79 | 6.24 | 6.36 | 6.9 | 5774.98 |
| base | 128 | 4 | fp32 | 26.41 | 696.75 | 11.54 | 5.76 | 6.22 | 6.41 | 6.86 | 5767.47 |
| base | 128 | 8 | fp16 | 34.2 | 964.18 | 13.57 | 8.27 | 8.72 | 8.94 | 9.52 | 5876.52 |
| base | 128 | 8 | fp32 | 34.42 | 965.47 | 13.6 | 8.28 | 8.64 | 8.89 | 9.44 | 5899.06 |
| base | 384 | 1 | fp16 | 17.03 | 177.1 | 11.46 | 5.65 | 6.11 | 6.25 | 6.7 | 6059.77 |
| base | 384 | 1 | fp32 | 17.2 | 176.11 | 11.49 | 5.66 | 6.15 | 6.29 | 6.77 | 6051.43 |
| base | 384 | 2 | fp16 | 25.64 | 239.89 | 19.3 | 8.31 | 8.84 | 9.13 | 9.84 | 6456.22 |
| base | 384 | 2 | fp32 | 25.6 | 240.18 | 19.26 | 8.29 | 8.8 | 9.06 | 9.77 | 6447.57 |
| base | 384 | 4 | fp16 | 31.28 | 305.32 | 24.29 | 13.09 | 13.62 | 13.85 | 14.97 | 6660.95 |
| base | 384 | 4 | fp32 | 31.11 | 304.43 | 24.28 | 13.13 | 13.6 | 13.8 | 14.98 | 6639.34 |
| base | 384 | 8 | fp16 | 43.89 | 358.82 | 34.29 | 22.27 | 22.79 | 23.1 | 24.51 | 7002.83 |
| base | 384 | 8 | fp32 | 43.9 | 358.76 | 34.33 | 22.26 | 22.8 | 23.11 | 24.35 | 7031.13 |
| large | 128 | 1 | fp16 | 47.42 | 103.62 | 15.96 | 9.42 | 10.95 | 11.16 | 11.67 | 11340.21 |
| large | 128 | 1 | fp32 | 36.28 | 108.7 | 15.52 | 8.91 | 10.12 | 10.4 | 10.96 | 11350.15 |
| large | 128 | 2 | fp16 | 38.82 | 180.4 | 17.77 | 11.09 | 11.91 | 12.05 | 12.44 | 11356.99 |
| large | 128 | 2 | fp32 | 39.12 | 177.62 | 17.97 | 11.45 | 11.98 | 12.13 | 12.79 | 11389.43 |
| large | 128 | 4 | fp16 | 58.85 | 253.71 | 27.84 | 15.94 | 16.48 | 16.65 | 17.52 | 11607 |
| large | 128 | 4 | fp32 | 57.8 | 261.94 | 27.35 | 15.01 | 16.17 | 16.35 | 17.01 | 11606.73 |
| large | 128 | 8 | fp16 | 78.49 | 348.55 | 34.15 | 22.89 | 23.82 | 24.05 | 24.71 | 11839.75 |
| large | 128 | 8 | fp32 | 79.35 | 345.57 | 34.53 | 23.22 | 23.96 | 24.19 | 24.88 | 12047.05 |
| large | 384 | 1 | fp16 | 34.49 | 77.09 | 24.99 | 12.98 | 13.76 | 13.89 | 14.59 | 12534.02 |
| large | 384 | 1 | fp32 | 33.95 | 79.81 | 24.49 | 12.34 | 13.35 | 13.51 | 14.09 | 12472.18 |
| large | 384 | 2 | fp16 | 54.4 | 97.77 | 44.04 | 20.34 | 21.21 | 21.38 | 22.2 | 13302.25 |
| large | 384 | 2 | fp32 | 53.88 | 98.22 | 43.83 | 20.12 | 21.18 | 21.38 | 22.19 | 13331.07 |
| large | 384 | 4 | fp16 | 68.97 | 118.22 | 57.65 | 33.95 | 34.44 | 34.62 | 35.31 | 13713.5 |
| large | 384 | 4 | fp32 | 69.14 | 117.88 | 57.75 | 34.07 | 34.59 | 34.78 | 35.73 | 13693.18 |
| large | 384 | 8 | fp16 | 104.65 | 126.65 | 88.76 | 63.22 | 63.87 | 64.17 | 65.32 | 14498.6 |
| large | 384 | 8 | fp32 | 104.84 | 126.41 | 89 | 63.33 | 64.11 | 64.4 | 65.53 | 14539.54 |
Data Chart
Raw Data
| Training Time Hours | Throughput sentences/sec | |
|---|---|---|
| FP16, Seq 128, BS1 | 2247.97 | 87.04 |
| FP32, Seq 128, BS1 | 1859.29 | 107.77 |
| FP16, Seq 128, BS2 | 996.29 | 228.01 |
| FP32, Seq 128, BS2 | 994.02 | 228.55 |
| FP16, Seq 128, BS4 | 617.1 | 449.09 |
| FP32, Seq 128, BS4 | 618.85 | 449.5 |
| FP16, Seq 128, BS8 | 392.02 | 807.31 |
| FP32, Seq 128, BS8 | 391.99 | 809.54 |
| FP16, Seq 384, BS1 | 1778.13 | 113.63 |
| FP32, Seq 384, BS1 | 1781.29 | 113.46 |
| FP16, Seq 384, BS2 | 1086.58 | 205.96 |
| FP32, Seq 384, BS2 | 1081.24 | 207.12 |
| FP16, Seq 384, BS4 | 742.6 | 346.99 |
| FP32, Seq 384, BS4 | 743.12 | 346.3 |
| FP16, Seq 384, BS8 | 520.45 | 521.61 |
| FP32, Seq 384, BS8 | 519.85 | 522.77 |
Data Chart
NVIDIA RTX A4500 Series GPUs
| GPU Features | NVIDIA RTX A4500 |
|---|---|
| GPU Memory | 20GB GDDR6 with error-correction code (ECC) |
| Display Ports | 4x DisplayPort 1.4 |
| Max Power Consumption | 2000 W |
| Graphics Bus | PCI Express Gen 4 x 16 |
| Form Factor | 4.4” (H) x 10.5” (L) Dual Slot |
| Thermal | Active |
| NVLink | 2-way Low-profile (2-slot and 3-slot bridges) |
| VR Ready | Yes |
Exxact Workstation System Specs
| Nodes | 1 |
| Processor / Count | 2x AMD EPYC 7552 |
| Total Logical Cores | 48 |
| Memory | DDR4 512GB |
| Storage | NVMe 3.84TB |
| OS | Ubuntu 18.04 |
| CUDA Version | 11.2 |
| BERT Dataset | squad v1 |
Have any questions?
Contact Exxact Today
