Deep Learning
TensorFlow 2.13 and Keras 2.13 Release Notes
July 27, 2023
16 min read


TensorFlow 2.13 and Keras 2.13 have been released! Highlights of this release include publishing Apple Silicon wheels, the new Keras V3 format being the default for .keras extension files, and many more!
TensorFlow 2.13 is the first version to provide Apple Silicon wheels, which means when you install TensorFlow on an Apple Silicon Mac, you will be able to use the latest version of TensorFlow. The nightly builds for Apple Silicon were released in March 2023 and this new support will enable more fine-grained testing.
The Python TensorFlow Lite Interpreter bindings now have an option to use experimental_disable_delegate_clustering flag to turn-off delegate clustering during delegate graph partitioning phase. You can set this flag in TensorFlow Lite interpreter Python API
interpreter = new Interpreter(file_of_a_tensorflowlite_model, experimental_preserve_all_tensors=False
The flag is set to False by default. This is an advanced feature in experimental that is designed for people who insert explicit control dependencies via with tf.control_dependencies() or need to change graph execution order.
Besides, there are several operator improvements in TensorFlow Lite in 2.13
Improved usability and added functionality for tf.data APIs.
tf.data.Dataset.zip now supports Python-style zipping. Previously, users were required to provide an extra set of parentheses when zipping datasets as in Dataset.zip((a, b, c)). With this change, users can specify the datasets to be zipped simply as Dataset.zip(a, b, c) making it more intuitive.
Additionally, tf.data.Dataset.shuffle now supports full shuffling. To specify that, data should be fully shuffled; use dataset = dataset.shuffle(dataset.cardinality()). This will load the full dataset into memory so that it can be shuffled. Make sure to only use this with datasets of filenames or other small datasets.
Also added is a new tf.data.experimental.pad_to_cardinality transformation which pads a dataset with zero elements up to a specified cardinality. This is useful for avoiding partial batches while not dropping any data.
Example usage:
ds = tf.data.Dataset.from_tensor_slices({'a': [1, 2]})
ds = ds.apply(tf.data.experimental.pad_to_cardinality(3))
list(ds.as_numpy_iterator())
[{'a': 1, 'valid': True}, {'a': 2, 'valid': True}, {'a': 0, 'valid': False}]
This can be useful, e.g. during evaluation when partial batches are undesirable, but it is also important not to drop any data.
oneDNN supports 2.12, is now the default for all files with the .keras extension.
You can start using it now by calling model.save(“your_model.keras”).
It provides richer Python-side model saving and reloading with numerous advantages:
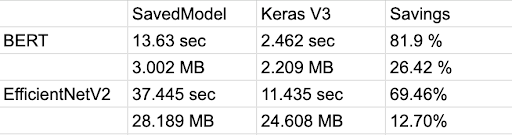
The legacy formats (h5 and Keras SavedModel) will stay supported in perpetuity. However, we recommend that you consider adopting the new Keras v3 format for saving/reloading in Python runtimes and using model.export() for inference in all other runtimes (such as TF Serving).
tf.function
tf.nn
tf.data
tf.math
tf.SavedModel
tf.Variable
tf.distribute
tf.experimental.dtensor
tf.experimental.ExtensionType
tf.nest
Keras is a framework built on top of the TensorFlow. See more details on the Keras website.
TensorFlow and Keras 2.13 Release Notes are sourced from the TensorFlow Github and TensorFlow Blog. Visit TensorFlow for more information.
Have any questions?
Contact Exxact for more information on building out your computing infrastructure.
TensorFlow 2.13 and Keras 2.13 have been released! Highlights of this release include publishing Apple Silicon wheels, the new Keras V3 format being the default for .keras extension files, and many more!
TensorFlow 2.13 is the first version to provide Apple Silicon wheels, which means when you install TensorFlow on an Apple Silicon Mac, you will be able to use the latest version of TensorFlow. The nightly builds for Apple Silicon were released in March 2023 and this new support will enable more fine-grained testing.
The Python TensorFlow Lite Interpreter bindings now have an option to use experimental_disable_delegate_clustering flag to turn-off delegate clustering during delegate graph partitioning phase. You can set this flag in TensorFlow Lite interpreter Python API
interpreter = new Interpreter(file_of_a_tensorflowlite_model, experimental_preserve_all_tensors=False
The flag is set to False by default. This is an advanced feature in experimental that is designed for people who insert explicit control dependencies via with tf.control_dependencies() or need to change graph execution order.
Besides, there are several operator improvements in TensorFlow Lite in 2.13
Improved usability and added functionality for tf.data APIs.
tf.data.Dataset.zip now supports Python-style zipping. Previously, users were required to provide an extra set of parentheses when zipping datasets as in Dataset.zip((a, b, c)). With this change, users can specify the datasets to be zipped simply as Dataset.zip(a, b, c) making it more intuitive.
Additionally, tf.data.Dataset.shuffle now supports full shuffling. To specify that, data should be fully shuffled; use dataset = dataset.shuffle(dataset.cardinality()). This will load the full dataset into memory so that it can be shuffled. Make sure to only use this with datasets of filenames or other small datasets.
Also added is a new tf.data.experimental.pad_to_cardinality transformation which pads a dataset with zero elements up to a specified cardinality. This is useful for avoiding partial batches while not dropping any data.
Example usage:
ds = tf.data.Dataset.from_tensor_slices({'a': [1, 2]})
ds = ds.apply(tf.data.experimental.pad_to_cardinality(3))
list(ds.as_numpy_iterator())
[{'a': 1, 'valid': True}, {'a': 2, 'valid': True}, {'a': 0, 'valid': False}]
This can be useful, e.g. during evaluation when partial batches are undesirable, but it is also important not to drop any data.
oneDNN supports 2.12, is now the default for all files with the .keras extension.
You can start using it now by calling model.save(“your_model.keras”).
It provides richer Python-side model saving and reloading with numerous advantages:
The legacy formats (h5 and Keras SavedModel) will stay supported in perpetuity. However, we recommend that you consider adopting the new Keras v3 format for saving/reloading in Python runtimes and using model.export() for inference in all other runtimes (such as TF Serving).
tf.function
tf.nn
tf.data
tf.math
tf.SavedModel
tf.Variable
tf.distribute
tf.experimental.dtensor
tf.experimental.ExtensionType
tf.nest
Keras is a framework built on top of the TensorFlow. See more details on the Keras website.
TensorFlow and Keras 2.13 Release Notes are sourced from the TensorFlow Github and TensorFlow Blog. Visit TensorFlow for more information.
Have any questions?
Contact Exxact for more information on building out your computing infrastructure.
