Artificial Intelligence
How LoRA Makes AI Fine-Tuning Faster, Cheaper, and More Practical
May 26, 2026
9 min read


Access to extreme-performance hardware is not always feasible, especially for complete fine-tuning of a foundational LLM like DeepSeek R1 or Llama 3. Or, your organization may have trained a model on the main computing infrastructure, but running fine-tuning will interrupt new projects.
LoRA, or Low-Rank Adaptation, is fine-tuning large language models without needing to retrain all of their parameters. LoRA has become a go-to approach because it supports fast iteration, makes it easier to maintain multiple tuned variants of a model, and reduces the operational cost of retraining large base models for every new use case without touching the underlying foundation model, while delivering very convincing results.
Instead of relying on large clusters or high-end GPUs, LoRA makes model customization accessible to teams with modest hardware like your Exxact GPU workstation or an Exxact GPU server. We'll explain how LoRA works, what makes it practical, and how it fits into real-world AI development, especially when paired with hardware designed to support efficient training workflows.
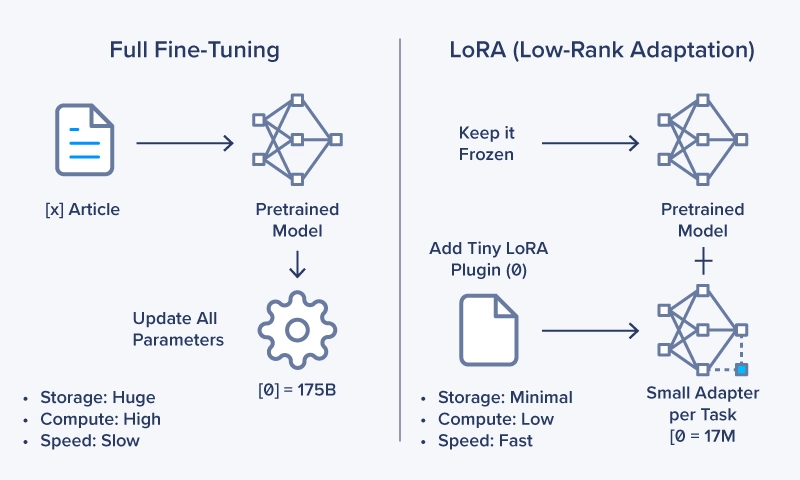
LoRA (Low-Rank Adaptation) is a technique that fine-tunes large language models efficiently by updating only a small number of parameters instead of retraining the entire model. In practice, LoRA trains small add-on weights (often called adapters) that you apply on top of the frozen base model at inference time.
Model customization is now accessible to teams without full-scale compute infrastructure. Practitioners, organizations, or departments can fine-tune foundation models for their specific use cases without requiring large-scale computing resources.
LoRA works by freezing the original model weights and training only a small set of additional low-rank matrices. This approach keeps the base model intact while adapting it to new data or tasks.
Two closely related terms you may see:
One key tuning knob is rank (r), which controls adapter capacity. Higher rank can improve quality for some tasks, but it increases memory use and compute.
For comparison, instead of fine-tuning the entire model with 100 billion parameters, LoRA might only require updating a couple million. This leads to faster, more efficient training without compromising output quality.
LoRA directly benefits teams that need to customize models for specific use cases without the overhead of traditional fine-tuning. It provides practical advantages that go beyond what prompt engineering or full fine-tuning can offer.
The following table provides rule-of-thumb VRAM estimates for loading and fine-tuning Large Language Models (LLMs) with LoRA and QLoRA, using a 7 billion parameter (7B) model as a benchmark.
These numbers can vary significantly based on optimizer choice, batch size, sequence length, LoRA rank/target modules, activation checkpointing, and whether you shard the model across multiple GPUs.
| Fine-Tuning Method | VRAM per 1B Parameters (Approx.) | 32B Model Total VRAM (Approx.) | Example GPU |
|---|---|---|---|
| Full Fine-Tuning | ~16 GB | ~512 GB | 4x H200 NVL (141GB) 8x RTX PRO 6000 (96GB) |
| LoRA (FP16/BF16) | ~2 GB (for model) + overhead | ~64 GB | 2x NVIDIA RTX 5090 (32GB) 1x RTX PRO 6000 (96GB) |
| QLoRA (4-bit) | ~0.5 GB (for model) + overhead | ~16 GB | 1x NVIDIA RTX 5080 (16G) 1x RTX PRO 4500 (32GB) |
Key factors affecting GPU requirements:
Note: LoRA and QLoRA reduce the number of trainable parameters and related optimizer memory, but activation memory can still dominate, especially with long sequence lengths. Plan VRAM headroom accordingly.
Practical GPU Recommendations
By using techniques like LoRA and QLoRA, fine-tuning large models that once required expensive multi-GPU data center setups is now feasible on affordable single-GPU, multi-GPU, or single-node configurations.
LoRA (Low-Rank Adaptation) fine-tunes large language models by updating only a small fraction of parameters, dramatically reducing compute requirements, memory use, and training time. It makes model customization accessible without hyperscaler-level hardware or massive infrastructure costs.
Traditional fine-tuning updates billions of parameters, requiring significant GPU memory and expense. LoRA freezes the original model and trains only small low-rank matrices, using far less VRAM and fewer GPU hours—directly lowering total cost of ownership.
LoRA enables rapid experimentation by creating lightweight adapters for different tasks. You can swap adapters without retraining the base model, resulting in faster iteration, version-controlled deployment, and minimal inference overhead.
In production workflows, this also supports cleaner release management: you can evaluate an updated adapter against a fixed test set, ship it, and roll back quickly if it causes regressions.
Yes. LoRA works efficiently on mid-range and workstation-grade GPUs, not just cutting-edge clusters. Exxact's AI workstations and servers are optimized for LoRA workloads, offering the right balance of GPU memory, compute density, and thermal stability.
Prompt engineering is fast but limited. Full fine-tuning is powerful but expensive. LoRA delivers near-full fine-tuning quality at a fraction of the compute cost, with reusable lightweight adapters—making it ideal for enterprises seeking customized AI without overspending.
LoRA provides a practical way to fine-tune large language models without the heavy compute demands of traditional methods. It lowers training costs, shortens iteration cycles, and gives teams the ability to build domain-specific AI with predictable hardware requirements.
When paired with Exxact hardware, LoRA becomes even more accessible. Exxact systems offer the GPU performance, stability, and flexibility needed to run LoRA efficiently, whether teams are tuning a 7B model on a workstation or supporting larger workloads on multi-GPU servers.
For organizations looking to customize AI without overspending, LoRA delivers a direct path forward. With the right hardware foundation, you can build faster, deploy smarter, and scale your AI projects with confidence.

With the latest CPUs and most powerful GPUs available, accelerate your deep learning and AI project optimized to your deployment, budget, and desired performance!
Configure NowAccess to extreme-performance hardware is not always feasible, especially for complete fine-tuning of a foundational LLM like DeepSeek R1 or Llama 3. Or, your organization may have trained a model on the main computing infrastructure, but running fine-tuning will interrupt new projects.
LoRA, or Low-Rank Adaptation, is fine-tuning large language models without needing to retrain all of their parameters. LoRA has become a go-to approach because it supports fast iteration, makes it easier to maintain multiple tuned variants of a model, and reduces the operational cost of retraining large base models for every new use case without touching the underlying foundation model, while delivering very convincing results.
Instead of relying on large clusters or high-end GPUs, LoRA makes model customization accessible to teams with modest hardware like your Exxact GPU workstation or an Exxact GPU server. We'll explain how LoRA works, what makes it practical, and how it fits into real-world AI development, especially when paired with hardware designed to support efficient training workflows.
LoRA (Low-Rank Adaptation) is a technique that fine-tunes large language models efficiently by updating only a small number of parameters instead of retraining the entire model. In practice, LoRA trains small add-on weights (often called adapters) that you apply on top of the frozen base model at inference time.
Model customization is now accessible to teams without full-scale compute infrastructure. Practitioners, organizations, or departments can fine-tune foundation models for their specific use cases without requiring large-scale computing resources.
LoRA works by freezing the original model weights and training only a small set of additional low-rank matrices. This approach keeps the base model intact while adapting it to new data or tasks.
Two closely related terms you may see:
One key tuning knob is rank (r), which controls adapter capacity. Higher rank can improve quality for some tasks, but it increases memory use and compute.
For comparison, instead of fine-tuning the entire model with 100 billion parameters, LoRA might only require updating a couple million. This leads to faster, more efficient training without compromising output quality.
LoRA directly benefits teams that need to customize models for specific use cases without the overhead of traditional fine-tuning. It provides practical advantages that go beyond what prompt engineering or full fine-tuning can offer.
The following table provides rule-of-thumb VRAM estimates for loading and fine-tuning Large Language Models (LLMs) with LoRA and QLoRA, using a 7 billion parameter (7B) model as a benchmark.
These numbers can vary significantly based on optimizer choice, batch size, sequence length, LoRA rank/target modules, activation checkpointing, and whether you shard the model across multiple GPUs.
| Fine-Tuning Method | VRAM per 1B Parameters (Approx.) | 32B Model Total VRAM (Approx.) | Example GPU |
|---|---|---|---|
| Full Fine-Tuning | ~16 GB | ~512 GB | 4x H200 NVL (141GB) 8x RTX PRO 6000 (96GB) |
| LoRA (FP16/BF16) | ~2 GB (for model) + overhead | ~64 GB | 2x NVIDIA RTX 5090 (32GB) 1x RTX PRO 6000 (96GB) |
| QLoRA (4-bit) | ~0.5 GB (for model) + overhead | ~16 GB | 1x NVIDIA RTX 5080 (16G) 1x RTX PRO 4500 (32GB) |
Key factors affecting GPU requirements:
Note: LoRA and QLoRA reduce the number of trainable parameters and related optimizer memory, but activation memory can still dominate, especially with long sequence lengths. Plan VRAM headroom accordingly.
Practical GPU Recommendations
By using techniques like LoRA and QLoRA, fine-tuning large models that once required expensive multi-GPU data center setups is now feasible on affordable single-GPU, multi-GPU, or single-node configurations.
LoRA (Low-Rank Adaptation) fine-tunes large language models by updating only a small fraction of parameters, dramatically reducing compute requirements, memory use, and training time. It makes model customization accessible without hyperscaler-level hardware or massive infrastructure costs.
Traditional fine-tuning updates billions of parameters, requiring significant GPU memory and expense. LoRA freezes the original model and trains only small low-rank matrices, using far less VRAM and fewer GPU hours—directly lowering total cost of ownership.
LoRA enables rapid experimentation by creating lightweight adapters for different tasks. You can swap adapters without retraining the base model, resulting in faster iteration, version-controlled deployment, and minimal inference overhead.
In production workflows, this also supports cleaner release management: you can evaluate an updated adapter against a fixed test set, ship it, and roll back quickly if it causes regressions.
Yes. LoRA works efficiently on mid-range and workstation-grade GPUs, not just cutting-edge clusters. Exxact's AI workstations and servers are optimized for LoRA workloads, offering the right balance of GPU memory, compute density, and thermal stability.
Prompt engineering is fast but limited. Full fine-tuning is powerful but expensive. LoRA delivers near-full fine-tuning quality at a fraction of the compute cost, with reusable lightweight adapters—making it ideal for enterprises seeking customized AI without overspending.
LoRA provides a practical way to fine-tune large language models without the heavy compute demands of traditional methods. It lowers training costs, shortens iteration cycles, and gives teams the ability to build domain-specific AI with predictable hardware requirements.
When paired with Exxact hardware, LoRA becomes even more accessible. Exxact systems offer the GPU performance, stability, and flexibility needed to run LoRA efficiently, whether teams are tuning a 7B model on a workstation or supporting larger workloads on multi-GPU servers.
For organizations looking to customize AI without overspending, LoRA delivers a direct path forward. With the right hardware foundation, you can build faster, deploy smarter, and scale your AI projects with confidence.
With the latest CPUs and most powerful GPUs available, accelerate your deep learning and AI project optimized to your deployment, budget, and desired performance!
Configure Now