Benchmarks
RTX A5500 Deep Learning Benchmarks for TensorFlow
June 6, 2022
5 min read


For this blog article,
Our Deep Learning Server was fitted with eight A5500 GPUs and we ran the standard “tf_cnn_benchmarks.py” benchmark script found in the official TensorFlow GitHub. We tested on the following networks: ResNet50, ResNet152, Inception v3, and Googlenet. Furthermore, we ran the same tests using 2, 4, and 8 GPU configurations with a batch size of 64 for FP32 and 128 for FP16.
Component | Specs |
CUDA Cores | 10240 |
Tensor Cores & Performance | 320 / 272.8 TFLOPS |
RT Cores & Performance | 80 / 66.6 TFLOPS |
Single Precision Performance | 34.1 TFLOPS |
GPU Memory | 24 GB GDDR6 with ECC |
Memory Interface & Bandwidth | 384-bit / 768 GB/sec |
System Interface | PCI Express 4.0 x16 |
Display Connectors | 4x DisplayPort 1.4a |
Maximum Power Consumption | 230 W |
Learn more about Exxact deep learning workstations starting at $3,700
Make / Model | Supermicro AS -4124GS-TN |
Nodes | 1 |
Processor / Count | 2x AMD EPYC 7552 |
Total Logical Cores | 48 |
Memory | DDR4 512 GB |
Storage | NVMe 3.84 TB |
OS | Ubuntu 18.04 |
CUDA Version | 11.4 |
Tensorflow Version | 2.4 |
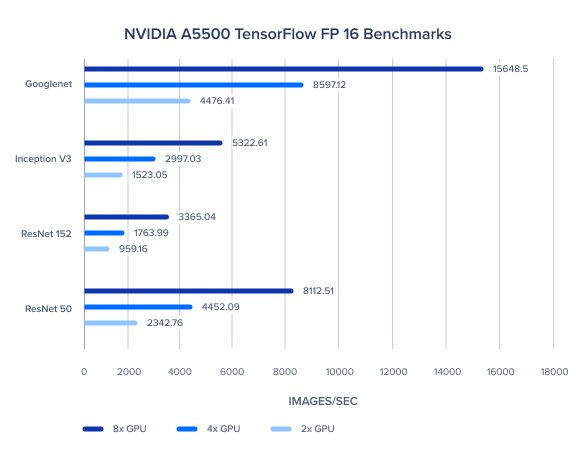
Model Type | 2x GPU | 4x GPU | 8x GPU |
ResNet 50 | 2342.76 | 4452.09 | 8112.51 |
ResNet 152 | 959.16 | 1763.99 | 3365.04 |
Inception V3 | 1523.05 | 2997.03 | 5322.61 |
Googlenet | 4476.41 | 8597.12 | 15648.5 |
Batch Size 256 for all FP16 tests.

Model Type | 2x GPU | 4x GPU | 8x GPU |
ResNet 50 | 875.93 | 1739.51 | 3116.23 |
ResNet 152 | 361.05 | 721.42 | 1334.13 |
Inception V3 | 621.71 | 1232.18 | 2234.22 |
Googlenet | 2179.04 | 4222.93 | 7626.51 |
Batch Size 128 for all FP32 tests.
Have any questions about NVIDIA GPUs or AI workstations and servers?
Contact Exxact Today
For this blog article,
Our Deep Learning Server was fitted with eight A5500 GPUs and we ran the standard “tf_cnn_benchmarks.py” benchmark script found in the official TensorFlow GitHub. We tested on the following networks: ResNet50, ResNet152, Inception v3, and Googlenet. Furthermore, we ran the same tests using 2, 4, and 8 GPU configurations with a batch size of 64 for FP32 and 128 for FP16.
Component | Specs |
CUDA Cores | 10240 |
Tensor Cores & Performance | 320 / 272.8 TFLOPS |
RT Cores & Performance | 80 / 66.6 TFLOPS |
Single Precision Performance | 34.1 TFLOPS |
GPU Memory | 24 GB GDDR6 with ECC |
Memory Interface & Bandwidth | 384-bit / 768 GB/sec |
System Interface | PCI Express 4.0 x16 |
Display Connectors | 4x DisplayPort 1.4a |
Maximum Power Consumption | 230 W |
Learn more about Exxact deep learning workstations starting at $3,700
Make / Model | Supermicro AS -4124GS-TN |
Nodes | 1 |
Processor / Count | 2x AMD EPYC 7552 |
Total Logical Cores | 48 |
Memory | DDR4 512 GB |
Storage | NVMe 3.84 TB |
OS | Ubuntu 18.04 |
CUDA Version | 11.4 |
Tensorflow Version | 2.4 |
Model Type | 2x GPU | 4x GPU | 8x GPU |
ResNet 50 | 2342.76 | 4452.09 | 8112.51 |
ResNet 152 | 959.16 | 1763.99 | 3365.04 |
Inception V3 | 1523.05 | 2997.03 | 5322.61 |
Googlenet | 4476.41 | 8597.12 | 15648.5 |
Batch Size 256 for all FP16 tests.
Model Type | 2x GPU | 4x GPU | 8x GPU |
ResNet 50 | 875.93 | 1739.51 | 3116.23 |
ResNet 152 | 361.05 | 721.42 | 1334.13 |
Inception V3 | 621.71 | 1232.18 | 2234.22 |
Googlenet | 2179.04 | 4222.93 | 7626.51 |
Batch Size 128 for all FP32 tests.
Have any questions about NVIDIA GPUs or AI workstations and servers?
Contact Exxact Today
