News
NVIDIA GTC 2026 Recap - Focusing on The Era of Tokens & Inference
March 17, 2026
16 min read


NVIDIA's GPU Technology Conference returned to San Jose this year with the energy of a company that knows it's at the center of one of the biggest technological shifts in history. Jensen Huang took the stage to cover everything from chip architecture and inference economics to open-source agentic frameworks and physical robotics — a lot of ground for one keynote.
At Exxact, we pay close attention to GTC every year because what NVIDIA announces directly shapes the AI infrastructure landscape our customers are building on. This recap breaks down the highlights and what they mean for organizations investing in AI today.
CUDA, NVIDIA's parallel computing platform, turned 20 this year. Jensen used the anniversary as a framing device for the rest of the keynote, most of what NVIDIA has built, and continues to build, traces back to this foundation.
A few things worth noting about where CUDA stands today:
The core point Jensen made is that the value of NVIDIA's platform isn't just the hardware, it's the compounding effect of two decades of software, tooling, and developer adoption built on top of it. That installed base is why workloads running on older NVIDIA hardware, like Ampere, are still seeing rising cloud pricing despite being several generations old.
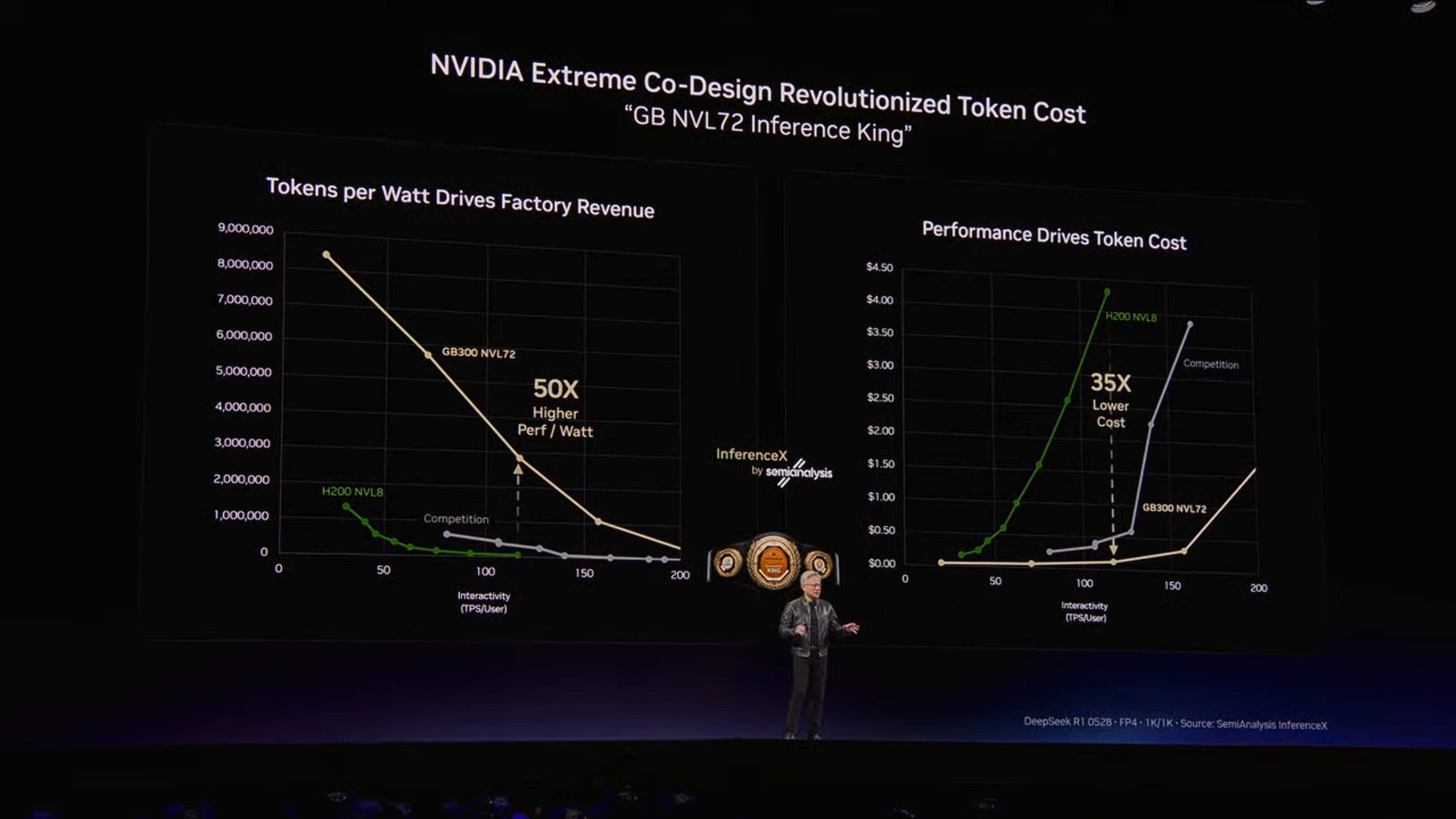
For most of NVIDIA's history, training the model was the dominant and focus in AI workload. As of recently, that has shifted. Jensen made the case that inference is now the primary driver of compute demand and that the economics of AI businesses are increasingly defined by how efficiently they can generate tokens. The more tokens you can hold in memory, the faster you can process these tokens, and the faster you can generate tokens, the smarter the AI.
Three developments over the past two years drove this shift:
Source: NVIDIA
The cumulative effect: Jensen estimated that compute demand per AI workload has increased roughly 10,000x over two years, while overall usage has grown approximately 100x. This implying total compute demand on the order of 1 million times greater than two years ago.
Jensen framed this shift with a concept worth understanding: the AI data center as a token factory.
This framing has direct implications for infrastructure decisions. The architecture you deploy determines your token throughput and token speed at a fixed power envelope which maps directly to revenue potential. Jensen's point was that this is how AI infrastructure ROI should be evaluated going forward, not just raw compute specs.
Blackwell is currently in full production and shipping at scale, but NVIDIA used GTC to formally introduce Vera Rubin, the next-generation platform architected around the demands of agentic AI workloads. The first Vera Rubin rack is already operational at Microsoft Azure.

Vera Rubin is designed as a full-system platform, not just a new GPU. Key specs:
One of the more significant announcements was NVIDIA's acquisition of the Groq chip team and integration of the Groq 3 LPX into the Vera Rubin platform. The two chips serve fundamentally different roles:
NVIDIA's inference orchestration software, Dynamo, splits the workload between them: Vera Rubin handles the prefill and attention portions of inference, while Groq handles the token generation (feedforward decode) stage. The result is 35x more throughput per megawatt compared to running Vera Rubin alone for latency-sensitive workloads.
Beyond the standard Vera Rubin configuration, NVIDIA also announced Rubin Ultra, a higher-density variant using a new rack design called Kyber:
These two metric, throughput and token speed, map directly to the revenue potential of a given infrastructure deployment. NVIDIA presented generation-over-generation comparisons at a fixed 1 gigawatt power envelope:

Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote Today
Two configurations will be available:
Both are in production. NVIDIA also noted the Vera CPU is already selling as a standalone product with high interest.
NVIDIA's broader point on the roadmap is that the platform is designed for continuity. Each generation maintains backward compatibility, and the shift from copper to optical interconnects will happen incrementally across both Scale-up and Scale-out rather than as a hard cutover.
A recurring theme throughout the keynote was NVIDIA's expansion beyond chips and systems into the infrastructure layer that surrounds them. Two areas reflect this most clearly: the tooling NVIDIA has built for designing and operating AI factories, and the breadth of industries now building on NVIDIA platforms.
As AI factories grow in scale and complexity, NVIDIA introduced DSX, an Omniverse-based digital twin platform built for designing, commissioning, and operating large-scale AI infrastructure. The core idea is that the various technology vendors involved in building a data center, cooling, power, networking, compute, need a shared environment to co-design before anything is physically built.
DSX covers the full facility lifecycle:
The underlying argument is that at gigawatt scale, inefficiencies in how a facility is designed and operated translate directly to lost token output and lost revenue. NVIDIA estimates there is roughly a factor of two in recoverable efficiency across a typical AI factory deployment.
Jensen covered the range of industries now building on NVIDIA infrastructure, with each relying on domain-specific Cuda-X libraries rather than general-purpose compute alone:
The breadth here reflects a consistent pattern in how NVIDIA approaches verticals. Rather than positioning GPUs as general-purpose accelerators, each domain gets purpose-built libraries, Cuda-X, that solve specific algorithmic problems in that field. Jensen described these libraries as the core of what differentiates NVIDIA's platform long term.
One of the more significant announcements at GTC was NVIDIA's support for OpenClaw, an open-source agentic AI framework that has seen unusually rapid adoption since its release. Jensen described it as the fastest adopted open-source project in history, surpassing Linux's 30-year install base within weeks.
OpenClaw functions as an operating system for AI agents. The components map closely to what a traditional OS provides:
The practical result is that anyone can spin up a functioning AI agent by running a single command. The agent connects to a language model, receives a task, and executes it autonomously across tools and systems.
The capability that makes OpenClaw useful also creates security risk in a corporate environment. An agentic system with access to internal infrastructure can read sensitive data, execute code, and communicate externally. NVIDIA worked with OpenClaw's author to address this with an enterprise-ready reference design called NeMo Claw, which adds:
NeMo Claw is available to download and deploy and is designed to connect with the policy engines that enterprise software vendors already maintain.
Jensen's framing was that OpenClaw represents the same kind of inflection point for enterprise software that Linux, HTML, and Kubernetes each represented in prior computing eras. The argument is straightforward: just as every company eventually needed a Linux strategy, a web strategy, and a cloud-native strategy, every company now needs an agentic AI strategy.
Alongside its hardware and infrastructure announcements, NVIDIA outlined its position as a contributor to open AI models. Rather than a single general-purpose model, NVIDIA is developing and releasing six domain-specific model families, each targeting a different field.
Each family is being actively maintained and updated. NVIDIA framed the ongoing investment in these models, rather than the models themselves, as the core value proposition for organizations building on them.
A thread running through this section of the keynote was sovereign AI, the ability for individual countries and organizations to build and run their own models rather than depending on a small number of large external providers. NVIDIA's open model initiative, combined with its on-premises infrastructure options, is positioned as the technical foundation for that capability.
Jensen dedicated a significant portion of the keynote to robotics, framing it as the next major frontier for AI after language and reasoning models. The core argument is that the same capabilities that enabled agentic AI in software, perception, reasoning, and action, now need to be extended to systems operating in the physical world.

NVIDIA provides three distinct computers for robotics development:
The simulation layer is particularly important because real-world data collection alone is insufficient to train robots across the full range of edge cases they will encounter in deployment.
GTC 2026 reinforced that the shift from training to inference as the dominant AI workload has real implications for how infrastructure should be evaluated. Tokens per watt and token speed at a fixed power budget are increasingly the metrics that determine what a deployment can deliver. That framing should inform hardware decisions being made today.
NVIDIA Blackwell is the right platform to deploy now. It is in full production, the software stack is mature, and the ecosystem is well established. Vera Rubin is sampling well with broad availability ahead, and the Rubin Ultra to Feynman roadmap signals that NVIDIA's annual architecture cadence is not slowing down. Planning around that cadence, rather than waiting for it, is the more practical approach for most deployment timelines.
As an NVIDIA Elite Partner and solution integrator, Exxact Corporation works with organizations navigating these infrastructure decisions. From GPU servers and workstations to full rack-scale deployments, our team can help identify the right configuration for your workload and budget.
NVIDIA's GPU Technology Conference returned to San Jose this year with the energy of a company that knows it's at the center of one of the biggest technological shifts in history. Jensen Huang took the stage to cover everything from chip architecture and inference economics to open-source agentic frameworks and physical robotics — a lot of ground for one keynote.
At Exxact, we pay close attention to GTC every year because what NVIDIA announces directly shapes the AI infrastructure landscape our customers are building on. This recap breaks down the highlights and what they mean for organizations investing in AI today.
CUDA, NVIDIA's parallel computing platform, turned 20 this year. Jensen used the anniversary as a framing device for the rest of the keynote, most of what NVIDIA has built, and continues to build, traces back to this foundation.
A few things worth noting about where CUDA stands today:
The core point Jensen made is that the value of NVIDIA's platform isn't just the hardware, it's the compounding effect of two decades of software, tooling, and developer adoption built on top of it. That installed base is why workloads running on older NVIDIA hardware, like Ampere, are still seeing rising cloud pricing despite being several generations old.
For most of NVIDIA's history, training the model was the dominant and focus in AI workload. As of recently, that has shifted. Jensen made the case that inference is now the primary driver of compute demand and that the economics of AI businesses are increasingly defined by how efficiently they can generate tokens. The more tokens you can hold in memory, the faster you can process these tokens, and the faster you can generate tokens, the smarter the AI.
Three developments over the past two years drove this shift:
Source: NVIDIA
The cumulative effect: Jensen estimated that compute demand per AI workload has increased roughly 10,000x over two years, while overall usage has grown approximately 100x. This implying total compute demand on the order of 1 million times greater than two years ago.
Jensen framed this shift with a concept worth understanding: the AI data center as a token factory.
This framing has direct implications for infrastructure decisions. The architecture you deploy determines your token throughput and token speed at a fixed power envelope which maps directly to revenue potential. Jensen's point was that this is how AI infrastructure ROI should be evaluated going forward, not just raw compute specs.
Blackwell is currently in full production and shipping at scale, but NVIDIA used GTC to formally introduce Vera Rubin, the next-generation platform architected around the demands of agentic AI workloads. The first Vera Rubin rack is already operational at Microsoft Azure.
Vera Rubin is designed as a full-system platform, not just a new GPU. Key specs:
One of the more significant announcements was NVIDIA's acquisition of the Groq chip team and integration of the Groq 3 LPX into the Vera Rubin platform. The two chips serve fundamentally different roles:
NVIDIA's inference orchestration software, Dynamo, splits the workload between them: Vera Rubin handles the prefill and attention portions of inference, while Groq handles the token generation (feedforward decode) stage. The result is 35x more throughput per megawatt compared to running Vera Rubin alone for latency-sensitive workloads.
Beyond the standard Vera Rubin configuration, NVIDIA also announced Rubin Ultra, a higher-density variant using a new rack design called Kyber:
These two metric, throughput and token speed, map directly to the revenue potential of a given infrastructure deployment. NVIDIA presented generation-over-generation comparisons at a fixed 1 gigawatt power envelope:
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote TodayTwo configurations will be available:
Both are in production. NVIDIA also noted the Vera CPU is already selling as a standalone product with high interest.
NVIDIA's broader point on the roadmap is that the platform is designed for continuity. Each generation maintains backward compatibility, and the shift from copper to optical interconnects will happen incrementally across both Scale-up and Scale-out rather than as a hard cutover.
A recurring theme throughout the keynote was NVIDIA's expansion beyond chips and systems into the infrastructure layer that surrounds them. Two areas reflect this most clearly: the tooling NVIDIA has built for designing and operating AI factories, and the breadth of industries now building on NVIDIA platforms.
As AI factories grow in scale and complexity, NVIDIA introduced DSX, an Omniverse-based digital twin platform built for designing, commissioning, and operating large-scale AI infrastructure. The core idea is that the various technology vendors involved in building a data center, cooling, power, networking, compute, need a shared environment to co-design before anything is physically built.
DSX covers the full facility lifecycle:
The underlying argument is that at gigawatt scale, inefficiencies in how a facility is designed and operated translate directly to lost token output and lost revenue. NVIDIA estimates there is roughly a factor of two in recoverable efficiency across a typical AI factory deployment.
Jensen covered the range of industries now building on NVIDIA infrastructure, with each relying on domain-specific Cuda-X libraries rather than general-purpose compute alone:
The breadth here reflects a consistent pattern in how NVIDIA approaches verticals. Rather than positioning GPUs as general-purpose accelerators, each domain gets purpose-built libraries, Cuda-X, that solve specific algorithmic problems in that field. Jensen described these libraries as the core of what differentiates NVIDIA's platform long term.
One of the more significant announcements at GTC was NVIDIA's support for OpenClaw, an open-source agentic AI framework that has seen unusually rapid adoption since its release. Jensen described it as the fastest adopted open-source project in history, surpassing Linux's 30-year install base within weeks.
OpenClaw functions as an operating system for AI agents. The components map closely to what a traditional OS provides:
The practical result is that anyone can spin up a functioning AI agent by running a single command. The agent connects to a language model, receives a task, and executes it autonomously across tools and systems.
The capability that makes OpenClaw useful also creates security risk in a corporate environment. An agentic system with access to internal infrastructure can read sensitive data, execute code, and communicate externally. NVIDIA worked with OpenClaw's author to address this with an enterprise-ready reference design called NeMo Claw, which adds:
NeMo Claw is available to download and deploy and is designed to connect with the policy engines that enterprise software vendors already maintain.
Jensen's framing was that OpenClaw represents the same kind of inflection point for enterprise software that Linux, HTML, and Kubernetes each represented in prior computing eras. The argument is straightforward: just as every company eventually needed a Linux strategy, a web strategy, and a cloud-native strategy, every company now needs an agentic AI strategy.
Alongside its hardware and infrastructure announcements, NVIDIA outlined its position as a contributor to open AI models. Rather than a single general-purpose model, NVIDIA is developing and releasing six domain-specific model families, each targeting a different field.
Each family is being actively maintained and updated. NVIDIA framed the ongoing investment in these models, rather than the models themselves, as the core value proposition for organizations building on them.
A thread running through this section of the keynote was sovereign AI, the ability for individual countries and organizations to build and run their own models rather than depending on a small number of large external providers. NVIDIA's open model initiative, combined with its on-premises infrastructure options, is positioned as the technical foundation for that capability.
Jensen dedicated a significant portion of the keynote to robotics, framing it as the next major frontier for AI after language and reasoning models. The core argument is that the same capabilities that enabled agentic AI in software, perception, reasoning, and action, now need to be extended to systems operating in the physical world.
NVIDIA provides three distinct computers for robotics development:
The simulation layer is particularly important because real-world data collection alone is insufficient to train robots across the full range of edge cases they will encounter in deployment.
GTC 2026 reinforced that the shift from training to inference as the dominant AI workload has real implications for how infrastructure should be evaluated. Tokens per watt and token speed at a fixed power budget are increasingly the metrics that determine what a deployment can deliver. That framing should inform hardware decisions being made today.
NVIDIA Blackwell is the right platform to deploy now. It is in full production, the software stack is mature, and the ecosystem is well established. Vera Rubin is sampling well with broad availability ahead, and the Rubin Ultra to Feynman roadmap signals that NVIDIA's annual architecture cadence is not slowing down. Planning around that cadence, rather than waiting for it, is the more practical approach for most deployment timelines.
As an NVIDIA Elite Partner and solution integrator, Exxact Corporation works with organizations navigating these infrastructure decisions. From GPU servers and workstations to full rack-scale deployments, our team can help identify the right configuration for your workload and budget.
