Artificial Intelligence
SXM vs PCIe: GPUs Best for Training LLMs like GPT-4
April 11, 2024
7 min read


Recent advancements in deep learning have led to the emergence of Large Language Models (LLMs) displaying uncanny natural language understanding which have revolutionized the world with a significant impact on the future. While the predecessor text-based AI called NLP or natural language processing is designed for their specific text-related task, LLMs are more generalized and just trained on text to understand what the next word in a sentence might be. LLMs fall under the subset of Generative AIs that generate text using machine learning and AI statistics to predict the next best word based on input and preceding text to create a coherent and comprehensive thought.
Large Language Models (LLMs) are a type of Language Model consisting of a neural network of parameters trained on massive amounts of unlabeled textual data. The most famous LLM is OpenAI's GPT (Generative Pre-trained Transformer) series, which has been trained on an incomprehensible amount of text data. GPT-3 and GPT 4 are the foundations for the renowned ChatGPT, the chatbot that broke the internet.
If traditional NLP AI models require massive amounts of data, LLMs would require even more. Enabling our computers to interact with our physical world is become a reality. LLMs have numerous applications in various industries like personalized chatbots, customer service automation, sentiment analysis, content creation, or even code. Startups and companies have opted to train these LLMs on dedicated high-performance hardware, with the NVIDIA DGX as the holy grail of GPU computing. So why do these large-scale organizations opt for an NVIDIA DGX? What is the difference between DGX and traditional PCIe GPUs?
The SXM architecture is a high bandwidth socketed solution for connecting NVIDIA Tensor Core GPUs like the NVIDIA H100 to their proprietary DGX systems or HGX system boards. For each generation of NVIDIA Tensor Core GPUs (P100, V100, A100, and now H100), has their respective SXM socket that allows for high bandwidth, increased power delivery, and full GPU connectivity via NVLink. Because SXM is a NVIDIA specific custom socket module, power delivery does not have to abide by PCIe standards. Increase power means increased performance with ample cooling, and cooling here won’t be a problem with these huge heatsinks. Each SXM module has a configurable max TDP of 700W. While each GPU won't draw 700W, the increased thermal limit allows GPUs to clock higher and in return have higher performance.
The specialized HGX system boards interconnect each of the 8 SXM GPUs via NVLink enabling high GPU-to-GPU bandwidth. NVLink allows the flow of data between GPUs to be extremely fast operating as one single GPU. The exchanging of data bypasses PCIe lanes and the CPU and is direct between GPUs, reducing the copying bottlenecking of transferring data back and forth. The 8 SXM5 H100s is capable of 900 GB/s of bidirectional bandwidth per GPU via 4x NVLink Switch Chips for a total bidirectional bandwidth of over 7.2TB/s. Unlike SLI from decades ago which have a master GPU and a slave GPU, each of the 8 H100 SXM GPU is also able to send data back to the CPU over PCIe. We will go over the architectural schematics later.

The NVIDIA H100 PCIe does not come standard with NVLink. However, it can still make use of NVLink with NVLink Bridges. These bridges can be purchased separately for the NVIDIA H100 PCIe which connect GPUs in pairs for 600 GB/s bidirectional instead of the full 900GB/s bidirectional found in the H100 SXM variant.
Now don’t get it wrong, an NVIDIA H100 PCIe is an extremely capable GPU that can be deployed with ease. The SXM equipped HGX boards draw significantly more power for performance but can pose serious challenges for data centers to supply ample power. The H100 PCIe is free of that extra power draw headache. They can be easily slotted into the data center that value minimal architectural changes to cooling, support, etc. You can also opt to configure your system with NVIDIA H100 NVL which has NVLink bridges included.

In the data center and AI industry, NVIDIA H100 is gold. Both SXM and PCIe variants are in high demand and sometimes have shortages with long lead times. The H100 SXM is only found in NVIDIA DGX and HGX form factor whereas the H100 PCIe can be slotted into any GPU server.
Large corporations flock to the NVIDIA DGX not because it is shiny but because of its ability to scale. The SXM form factor developed by NVIDIA has scalability in mind. In every DGX/HGX deployment, eight H100 GPUs are fully interconnected with NVLink via 4 NVSwitch chips enabling a web for all GPUs to operate as one big GPU. This scalability can further expand with more NVIDIA NVLink Switch System and connect multiple 256 DGX H100s to create one big GPU accelerated AI factory.
.jpg?format=webp)
On the other hand, H100 PCIe with NVLink, only connect pairs of GPUs with the NVLink Bridge. GPU 1 is only directly connected to GPU 2, GPU 3 is only directly connected to GPU 4, etc. GPU 1 and GPU 8 are not directly connected and therefore will have to communicate data over PCIe lanes which isn’t as fast. The NVIDIA DGX and HGX system board has all the SXM GPUs interconnected through the NVLink Switch Chips and thus data transfer between GPU-to-GPU is not limited by the speed of the PCIe lanes.
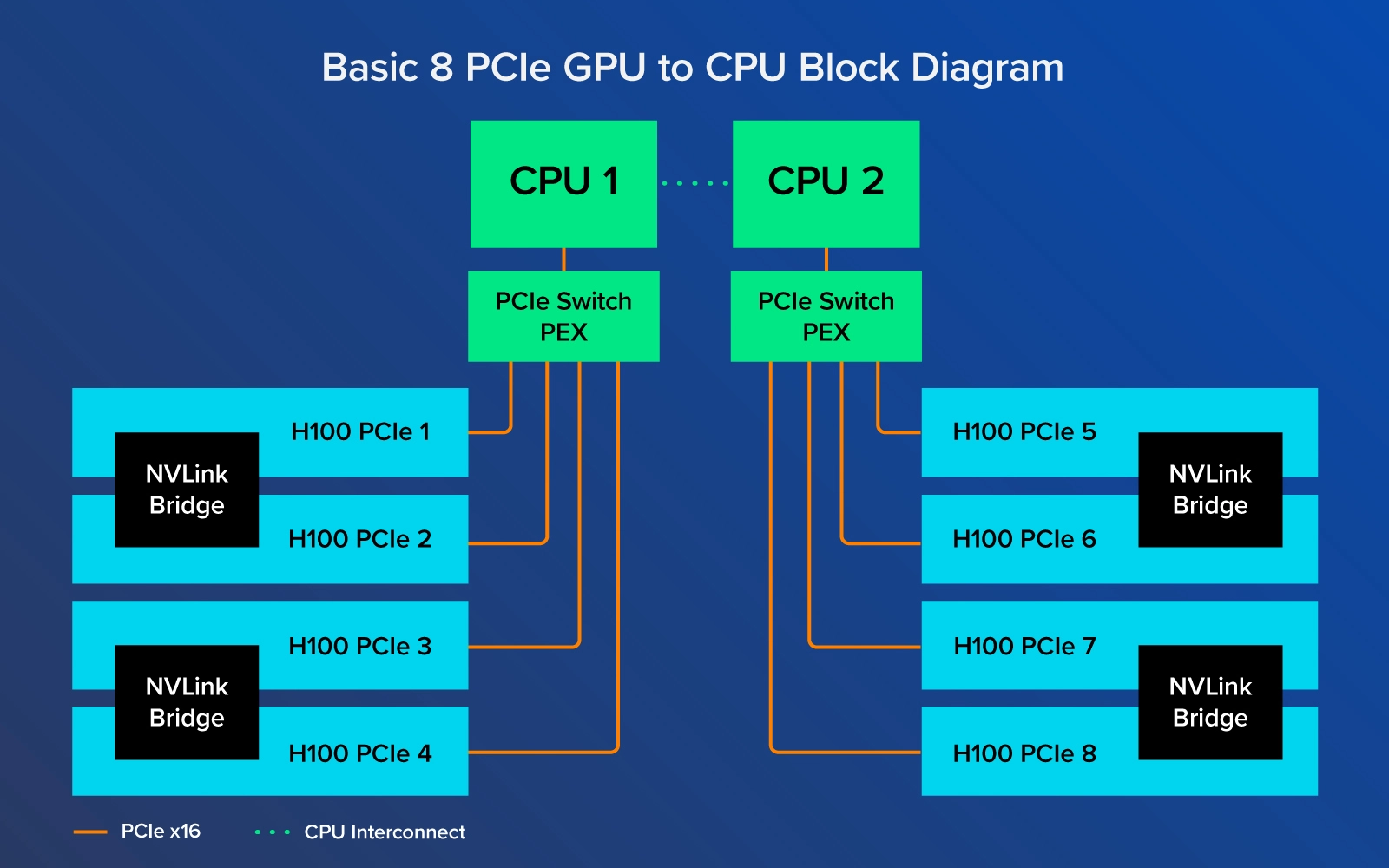
By bypassing the PCI Express lanes when exchanging data between GPUs, the blistering fast SXM H100 GPUs can achieve maximum throughput with fewer slowdowns than their PCIe counterpart. This dramatic speedup and bypassing of copying data to system memory back to another GPU. Limiting data transferring bottlenecks is perfect for training extremely large AI models that have huge amounts of training data that needs to be shared with every GPU quickly. Training and inference time can be reduced drastically when it comes to developing large language models and inferencing text to millions of people.
H100 SXM found in DGX and HGX offer better GPU-to-GPU interconnect and scalability. H100 PCIe is easier to deploy in existing serves and is still a great choice for AI training. But Large Language Models and Generative AI require ungodly amounts of performance and the number of users, the workload, and the training magnitude play a large part in picking the right system.
The NVIDIA H100 SXM can be found in DGX and HGX delivering high scalability and GPU unification. The ability to NVLink H100 to function effectively as one giant GPU is a huge advantage for powering large AI models. With DGX, scalability extends to multiple DGX servers for more interconnected compute, perfect for those training the next big AI. Servers featuring NVIDIA HGX caters to those who want customizable platforms while still able to take advantage of 8 interconnected NVIDIA H100 SXM5 GPUs. Both DGX and HGX systems are best for organizations that can take advantage of the raw computing performance and not let anything go to waste.
The NVIDIA H100 PCIe variant is for those working with smaller workloads and want the ultimate flexibility in deciding the number of GPUs in your system. The H100 PCIe can also be slotted in smaller form factor 1U, 2U, 4U deployments in 2x or 4x or up to 10x GPUs configurations to offer the computing power for smaller AI development or distributed workloads. These GPUs still pack a punch when it comes to performance. It has slightly less raw performance but can be slotted into any computing infrastructure with ease, making these GPUs compelling. If your AI models don’t require the massive amounts of consolidated GPU memory, H100 PCIe is a great choice. These GPUs also make a great choice for HPC, data analytics, simulation, and other tasks apart from AI that are smaller and don’t require the GPU unification found in DGX/HGX.

Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure NowRecent advancements in deep learning have led to the emergence of Large Language Models (LLMs) displaying uncanny natural language understanding which have revolutionized the world with a significant impact on the future. While the predecessor text-based AI called NLP or natural language processing is designed for their specific text-related task, LLMs are more generalized and just trained on text to understand what the next word in a sentence might be. LLMs fall under the subset of Generative AIs that generate text using machine learning and AI statistics to predict the next best word based on input and preceding text to create a coherent and comprehensive thought.
Large Language Models (LLMs) are a type of Language Model consisting of a neural network of parameters trained on massive amounts of unlabeled textual data. The most famous LLM is OpenAI's GPT (Generative Pre-trained Transformer) series, which has been trained on an incomprehensible amount of text data. GPT-3 and GPT 4 are the foundations for the renowned ChatGPT, the chatbot that broke the internet.
If traditional NLP AI models require massive amounts of data, LLMs would require even more. Enabling our computers to interact with our physical world is become a reality. LLMs have numerous applications in various industries like personalized chatbots, customer service automation, sentiment analysis, content creation, or even code. Startups and companies have opted to train these LLMs on dedicated high-performance hardware, with the NVIDIA DGX as the holy grail of GPU computing. So why do these large-scale organizations opt for an NVIDIA DGX? What is the difference between DGX and traditional PCIe GPUs?
The SXM architecture is a high bandwidth socketed solution for connecting NVIDIA Tensor Core GPUs like the NVIDIA H100 to their proprietary DGX systems or HGX system boards. For each generation of NVIDIA Tensor Core GPUs (P100, V100, A100, and now H100), has their respective SXM socket that allows for high bandwidth, increased power delivery, and full GPU connectivity via NVLink. Because SXM is a NVIDIA specific custom socket module, power delivery does not have to abide by PCIe standards. Increase power means increased performance with ample cooling, and cooling here won’t be a problem with these huge heatsinks. Each SXM module has a configurable max TDP of 700W. While each GPU won't draw 700W, the increased thermal limit allows GPUs to clock higher and in return have higher performance.
The specialized HGX system boards interconnect each of the 8 SXM GPUs via NVLink enabling high GPU-to-GPU bandwidth. NVLink allows the flow of data between GPUs to be extremely fast operating as one single GPU. The exchanging of data bypasses PCIe lanes and the CPU and is direct between GPUs, reducing the copying bottlenecking of transferring data back and forth. The 8 SXM5 H100s is capable of 900 GB/s of bidirectional bandwidth per GPU via 4x NVLink Switch Chips for a total bidirectional bandwidth of over 7.2TB/s. Unlike SLI from decades ago which have a master GPU and a slave GPU, each of the 8 H100 SXM GPU is also able to send data back to the CPU over PCIe. We will go over the architectural schematics later.
The NVIDIA H100 PCIe does not come standard with NVLink. However, it can still make use of NVLink with NVLink Bridges. These bridges can be purchased separately for the NVIDIA H100 PCIe which connect GPUs in pairs for 600 GB/s bidirectional instead of the full 900GB/s bidirectional found in the H100 SXM variant.
Now don’t get it wrong, an NVIDIA H100 PCIe is an extremely capable GPU that can be deployed with ease. The SXM equipped HGX boards draw significantly more power for performance but can pose serious challenges for data centers to supply ample power. The H100 PCIe is free of that extra power draw headache. They can be easily slotted into the data center that value minimal architectural changes to cooling, support, etc. You can also opt to configure your system with NVIDIA H100 NVL which has NVLink bridges included.
In the data center and AI industry, NVIDIA H100 is gold. Both SXM and PCIe variants are in high demand and sometimes have shortages with long lead times. The H100 SXM is only found in NVIDIA DGX and HGX form factor whereas the H100 PCIe can be slotted into any GPU server.
Large corporations flock to the NVIDIA DGX not because it is shiny but because of its ability to scale. The SXM form factor developed by NVIDIA has scalability in mind. In every DGX/HGX deployment, eight H100 GPUs are fully interconnected with NVLink via 4 NVSwitch chips enabling a web for all GPUs to operate as one big GPU. This scalability can further expand with more NVIDIA NVLink Switch System and connect multiple 256 DGX H100s to create one big GPU accelerated AI factory.
On the other hand, H100 PCIe with NVLink, only connect pairs of GPUs with the NVLink Bridge. GPU 1 is only directly connected to GPU 2, GPU 3 is only directly connected to GPU 4, etc. GPU 1 and GPU 8 are not directly connected and therefore will have to communicate data over PCIe lanes which isn’t as fast. The NVIDIA DGX and HGX system board has all the SXM GPUs interconnected through the NVLink Switch Chips and thus data transfer between GPU-to-GPU is not limited by the speed of the PCIe lanes.
By bypassing the PCI Express lanes when exchanging data between GPUs, the blistering fast SXM H100 GPUs can achieve maximum throughput with fewer slowdowns than their PCIe counterpart. This dramatic speedup and bypassing of copying data to system memory back to another GPU. Limiting data transferring bottlenecks is perfect for training extremely large AI models that have huge amounts of training data that needs to be shared with every GPU quickly. Training and inference time can be reduced drastically when it comes to developing large language models and inferencing text to millions of people.
H100 SXM found in DGX and HGX offer better GPU-to-GPU interconnect and scalability. H100 PCIe is easier to deploy in existing serves and is still a great choice for AI training. But Large Language Models and Generative AI require ungodly amounts of performance and the number of users, the workload, and the training magnitude play a large part in picking the right system.
The NVIDIA H100 SXM can be found in DGX and HGX delivering high scalability and GPU unification. The ability to NVLink H100 to function effectively as one giant GPU is a huge advantage for powering large AI models. With DGX, scalability extends to multiple DGX servers for more interconnected compute, perfect for those training the next big AI. Servers featuring NVIDIA HGX caters to those who want customizable platforms while still able to take advantage of 8 interconnected NVIDIA H100 SXM5 GPUs. Both DGX and HGX systems are best for organizations that can take advantage of the raw computing performance and not let anything go to waste.
The NVIDIA H100 PCIe variant is for those working with smaller workloads and want the ultimate flexibility in deciding the number of GPUs in your system. The H100 PCIe can also be slotted in smaller form factor 1U, 2U, 4U deployments in 2x or 4x or up to 10x GPUs configurations to offer the computing power for smaller AI development or distributed workloads. These GPUs still pack a punch when it comes to performance. It has slightly less raw performance but can be slotted into any computing infrastructure with ease, making these GPUs compelling. If your AI models don’t require the massive amounts of consolidated GPU memory, H100 PCIe is a great choice. These GPUs also make a great choice for HPC, data analytics, simulation, and other tasks apart from AI that are smaller and don’t require the GPU unification found in DGX/HGX.
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research.
Configure Now