Artificial Intelligence
How To Improve the Performance of a RAG Model
August 16, 2024
9 min read


Retrieval-augmented generation (RAG) models, more commonly known as RAG systems, are gaining significant attention in the AI industry. The concept behind the models is simple: instead of training a model on massive amounts of data, we allow the model to retrieve information from a separate dataset as they need it.
How could this improve machine learning models? Firstly, the process of training or fine-tuning a large language model (LLM) is extremely expensive, time-consuming, and tedious. It requires highly trained machine learning and AI practitioners. RAG systems utilize foundational LLMs and augment the input to keep your model up to date to the minute or second while still being able to incorporate new data. When new data is generated, it can be added to the retrieval database almost instantly.
In this article, we will focus on how to optimize RAG systems to be as efficient as possible. We’ll cover RAG systems from multiple perspectives, diving deeper into their purpose and how we can optimize them.
We will briefly explain Retrieval Augmented Generation but you can read more in-depth in a previous blog we wrote on how RAG makes LLMs smarter than before.
As the name implies a RAG model is comprised of three main components: Retrieval, Augmentation, and Generation. These components represent the general workflow of the model, with each individual component including even more detail.
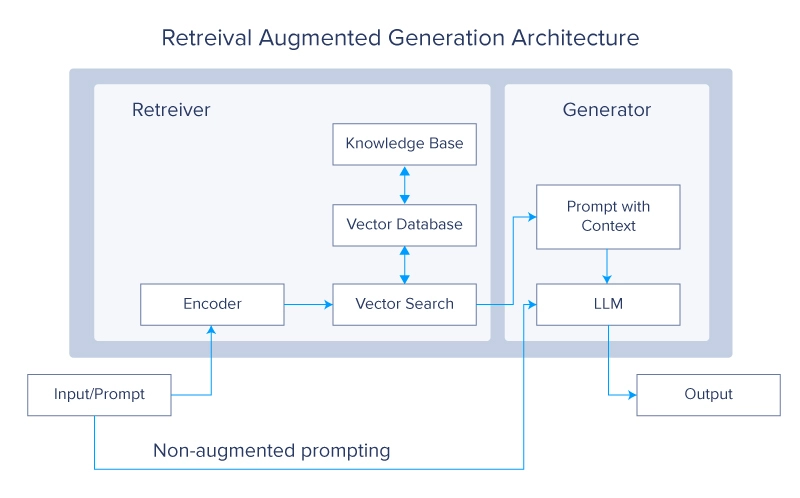
So which areas of this process can we speed up? It’s in its name! We can optimize the R (retrieval), the A (augmentation), and the G (generation) in RAG.
An effective method to improve the performance a RAG system is by enhancing the vectorization process by increasing dimensions and value precision, creating more detailed and precise embeddings. The vectorization process transforms words or phrases into numerical vectors that capture their meanings and relationships and store them in a dimensional database. By increasing the granularity of each data point, we can hope to achieve a more accurate RAG model.
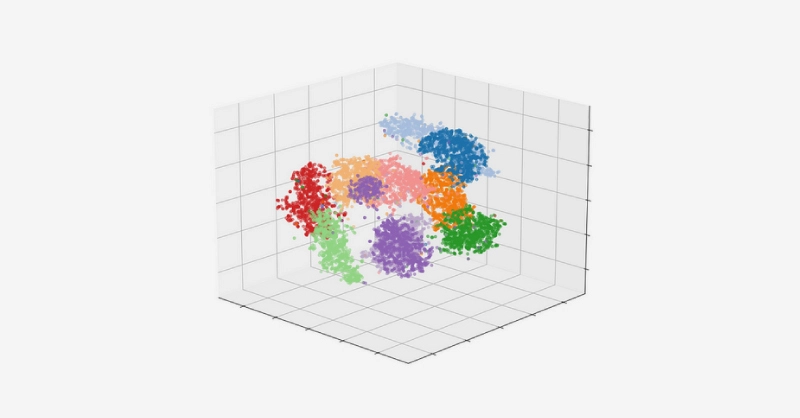
However, it's important to note that these optimizations come with trade-offs. Increasing both the vector dimensions and precision values of the system will result in a larger, more storage and computationally intensive model.

Deploying full-scale AI models can be accelerated exponentially with the right computing infrastructure. Storage, head node, networking, compute - all components of your next Exxact cluster are configurable to your workload to drive and accelerate research and innovation.
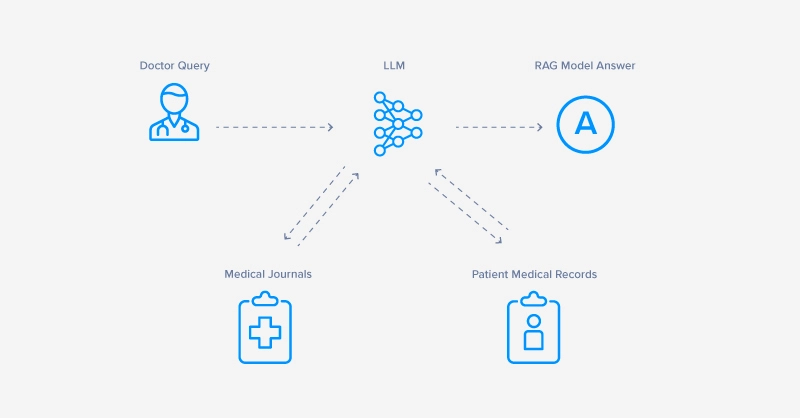
Get a Quote TodayIn a Retrieval-Augmented Generation (RAG) system, the retrieval component is responsible for fetching relevant information that the generative model uses to produce responses.
By incorporating multiple data sources, we can significantly enhance the performance and accuracy of the RAG system. This approach, known as augmentation optimization, leverages a variety of information repositories to provide richer and more comprehensive context, which eventually leads to better responses. Here a some examples:
Although utilizing state-of-the-art LLMs can often promise superior content generation and analysis capabilities when it comes to implementing a Retrieval-Augmented Generation (RAG) system, opting for the most complex LLMs isn't always the best choice.
Below are five points to focus on when utilizing the generation part of your RAG system.
The immense value of RAG-based LLMs is popularized by their potential for optimized, cost-effective, and efficient usage. These extensions are already providing a powerful way to enhance the capabilities of LLMs by allowing them to retrieve and incorporate up-to-date information, ensuring your models remain relevant and accurate.
However, improving the RAG system in every possible lead to other considerations. Increasing vector precision enhances retrieval accuracy but leads to higher computational costs longer training times, and slower inferencing response speed. The most effective RAG system is the one that's tailored to your unique needs and objectives to optimal performance without compromising overall effectiveness. Customizing your RAG system to align with your specific use cases, data sources, and operational requirements will provide the best results.
The same goes for the system that stores your data and powers your RAG. High-performance hardware is in high demand to deliver the best performance against competitors in the AI industry. But these systems are rarely one-size-fits-all. At Exxact, our goal is to tailor the right system unique to your needs and objectives within a fixed budget without compromising performance. With over 30 years of expertise, we have built systems for various workloads working with AI startups, renowned research institutions, and Fortune 500 companies. Our expertise is in your hands to configure the best data center infrastructure to power your innovations to be shared with the world.

Training, inferencing, and fine-tuning Agentic AI, LLMs, and traditional AI models on massive datasets can be accelerated exponentially with the right system. We provide the tool to propel and accelerate your research.
Configure NowRetrieval-augmented generation (RAG) models, more commonly known as RAG systems, are gaining significant attention in the AI industry. The concept behind the models is simple: instead of training a model on massive amounts of data, we allow the model to retrieve information from a separate dataset as they need it.
How could this improve machine learning models? Firstly, the process of training or fine-tuning a large language model (LLM) is extremely expensive, time-consuming, and tedious. It requires highly trained machine learning and AI practitioners. RAG systems utilize foundational LLMs and augment the input to keep your model up to date to the minute or second while still being able to incorporate new data. When new data is generated, it can be added to the retrieval database almost instantly.
In this article, we will focus on how to optimize RAG systems to be as efficient as possible. We’ll cover RAG systems from multiple perspectives, diving deeper into their purpose and how we can optimize them.
We will briefly explain Retrieval Augmented Generation but you can read more in-depth in a previous blog we wrote on how RAG makes LLMs smarter than before.
As the name implies a RAG model is comprised of three main components: Retrieval, Augmentation, and Generation. These components represent the general workflow of the model, with each individual component including even more detail.
So which areas of this process can we speed up? It’s in its name! We can optimize the R (retrieval), the A (augmentation), and the G (generation) in RAG.
An effective method to improve the performance a RAG system is by enhancing the vectorization process by increasing dimensions and value precision, creating more detailed and precise embeddings. The vectorization process transforms words or phrases into numerical vectors that capture their meanings and relationships and store them in a dimensional database. By increasing the granularity of each data point, we can hope to achieve a more accurate RAG model.
However, it's important to note that these optimizations come with trade-offs. Increasing both the vector dimensions and precision values of the system will result in a larger, more storage and computationally intensive model.
Deploying full-scale AI models can be accelerated exponentially with the right computing infrastructure. Storage, head node, networking, compute - all components of your next Exxact cluster are configurable to your workload to drive and accelerate research and innovation.
Get a Quote TodayIn a Retrieval-Augmented Generation (RAG) system, the retrieval component is responsible for fetching relevant information that the generative model uses to produce responses.
By incorporating multiple data sources, we can significantly enhance the performance and accuracy of the RAG system. This approach, known as augmentation optimization, leverages a variety of information repositories to provide richer and more comprehensive context, which eventually leads to better responses. Here a some examples:
Although utilizing state-of-the-art LLMs can often promise superior content generation and analysis capabilities when it comes to implementing a Retrieval-Augmented Generation (RAG) system, opting for the most complex LLMs isn't always the best choice.
Below are five points to focus on when utilizing the generation part of your RAG system.
The immense value of RAG-based LLMs is popularized by their potential for optimized, cost-effective, and efficient usage. These extensions are already providing a powerful way to enhance the capabilities of LLMs by allowing them to retrieve and incorporate up-to-date information, ensuring your models remain relevant and accurate.
However, improving the RAG system in every possible lead to other considerations. Increasing vector precision enhances retrieval accuracy but leads to higher computational costs longer training times, and slower inferencing response speed. The most effective RAG system is the one that's tailored to your unique needs and objectives to optimal performance without compromising overall effectiveness. Customizing your RAG system to align with your specific use cases, data sources, and operational requirements will provide the best results.
The same goes for the system that stores your data and powers your RAG. High-performance hardware is in high demand to deliver the best performance against competitors in the AI industry. But these systems are rarely one-size-fits-all. At Exxact, our goal is to tailor the right system unique to your needs and objectives within a fixed budget without compromising performance. With over 30 years of expertise, we have built systems for various workloads working with AI startups, renowned research institutions, and Fortune 500 companies. Our expertise is in your hands to configure the best data center infrastructure to power your innovations to be shared with the world.
Training, inferencing, and fine-tuning Agentic AI, LLMs, and traditional AI models on massive datasets can be accelerated exponentially with the right system. We provide the tool to propel and accelerate your research.
Configure Now