Artificial Intelligence
Passing the Trillion Parameter Mark with Switch Transformers
August 3, 2021
17 min read


It is practically a trope in certain types of science fiction for an advanced computer system to suddenly “awaken” and become self-aware, often accompanied by vastly improved capabilities, when passing an unseen threshold in computing capacity.
Many prominent members of the AI community believe that this common element of AI in sci-fi is as much a literal prophecy as a plot device, and few are more outspoken about the promise of scale as a primary (if not the sole) driver of artificial general intelligence than Ilya Sutskever and Greg Brockman at OpenAI. Even Richard Sutton made the strong assertion that compute is king in his essay "The Bitter Lesson."
Pre-trained Transformer-3 Language Models
The latest in a line of growing language models from OpenAI, Generalized Pre-trained Transformer-3 (GPT-3 to its friends), garnered plenty of attention when it was announced in May 2020. In part, this was because GPT-3 was, at the time, significantly larger than any other non-sparse model by as much as an order of magnitude.
The full version of GPT-3 has approximately 175 billion parameters, or about two orders of magnitude more than its immediate predecessor, GPT-2, and more than 10 times as many as the previous record holder, the Turing-NLG model from Microsoft.
This year a couple of models have been published that are even larger, breaking the trillion parameter threshold for the first time. These are the Switch Transformer, published by Google in January 2021 (with accompanying code), and the mysterious and even more massive WuDao 2.0 developed at the Beijing Academy of Artificial Intelligence. In both cases researchers had to employ some clever tricks to get there, and while Switch and WuDao both have in excess of 1.5 trillion parameters, they don’t use all of them at the same time.
Can these models live up to the hype of their hugeness?
Interested in a deep learning solution for NLP research?
Learn more about Exxact workstations starting at $3700
Transformers came onto the natural language processing (NLP) scene in 2017 with the NeurIPs paper Attention is All you Need by Vaswani et al. Since then, bigger and better transformers have all but displaced the previous state-of-the art approaches that relied on recurrent connections.
Unlike recurrent networks and long short term memory models, the transformer is a type of model that’s able to parse sequential information (like speech) all in one go, instead of going through a string of words one-by-one while remembering what came earlier.
This might seem counterintuitive to humans, who are certainly used to taking in a conversation in the order it is uttered by a conversation partner. It’s almost like the language used by the mysterious hexapods in Ted Chiang’s short story, "Stories of Your Life and Others," or the film adaptation “Arrival.” The aliens in the story communicate with a written language that is taken as a gestalt and doesn’t differentiate between past, future, or present, leading to some interesting consequences. But transformer models communicate with all the temporal dependencies we humans are used to, sometimes (arguably) managing to do so quite convincingly.
How do transformers keep track of temporal/sequence based relationships between language tokens if they parse entire blocks of text at once?
For a machine learning model, units of language must typically be first converted to a format understandable to neural networks, i.e. vector arrays, and this is generally accomplished by tokenization. Tokenization is the process of embedding parts of language, which can be at the level of characters, words, or some other level of granularity, into a numerical vector format that can be understood by neural models. This is significantly better than one-hot encoding on its own, because the tokens themselves can encode useful relationships between elements of language.
However this doesn’t solve our problem of importing temporal information about word and sentence order, and for that we’ll need positional embeddings, without which an undifferentiated bundle of language tokens might be little better than a bag-of-words approach.
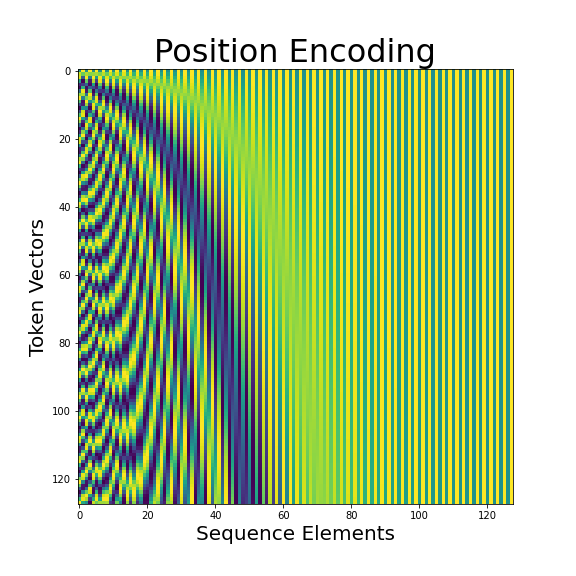
Encoding positions is accomplished by adding the results of a position encoding function to yield a unique and predictable fingerprint for each position. There’s more than one way to go about it, but if we follow the position encoding strategy from the TensorFlow transformer tutorial, we’ll end up with an encoding that looks something like the following:
Position encoding for switch transformer parameters
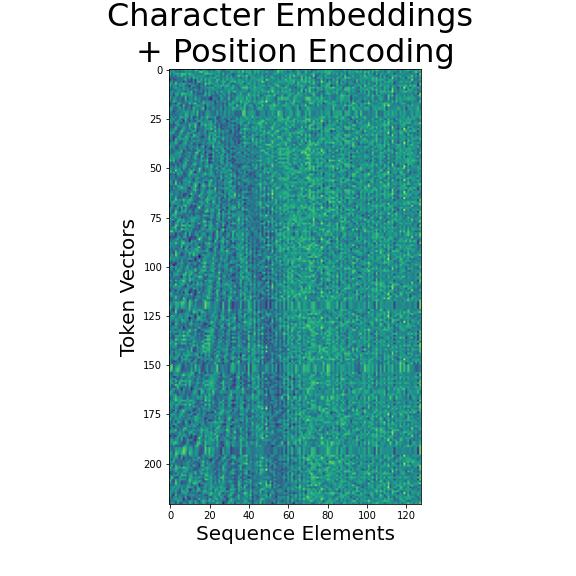
When we combine position encoding with embedded language tokens the input to our model might look a little like:
Combining tokenized embeddings of language elements (e.g. word vectors) with sinusoidal position encodings gives the transformer the information it needs to attend to both the content and the context of language sequences. The example above uses a dictionary of random vectors, whereas in practice language tokens will be the output of learned embedding models.
Of course, we wouldn’t have transformers without attention. There are multiple attention mechanisms available to choose from, but perhaps the best-known (and the type of attention used in the “Attention is all You Need” paper) is called dot-product attention, also known as self-attention.
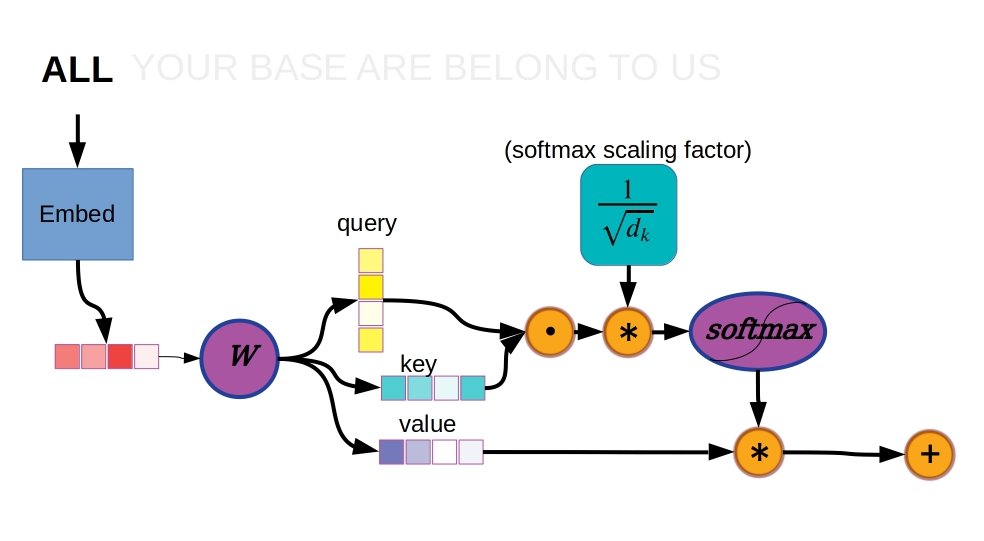
Dot-product attention is fairly simple in principle and the name sort of gives it away. Instead of producing a single output of hidden nodes (or features) like a conventional dense neural layer, a self-attention layer (or 3 separate layers) will produce 3 vectors called key, query, and value vectors. The dot product of the key and query vectors becomes the attention weight for the value vector, and all attention weights are subjected to a softmax activation function to ensure that the total sum of attention weights is always the same and always takes a value of 1.0.
Diagram of self-attention, also known as dot-product attention or intra-attention.
Image source (public domain).
For a more detailed and quite enjoyable romp through attention and other concepts behind transformers, check out Lilian Weng’s review of attention mechanisms and/or Jay Alammar’s impressive explainer: "The Illustrated Transformer." As for us and the blog post you’re currently reading? We’ve got bigger models to fry.
Hinton makes a joke (screenshot of source).
The majority of AI and machine learning researchers think that clever ideas are what drive breakthroughs in their field, and it’s going to take some human ingenuity to eventually engineer any kind of real machine ingenuity, or artificial general intelligence.
A critic might suspect that this is an important belief to hold for purposes of maintaining conviction in one’s life work. Another group of researchers, including high-profile individuals like RL pioneer Richard Sutton and his Bitter Lesson, and at least the leadership at OpenAI, if not the entire crew, have a different theory. That is, under the scaling hypothesis, the main driver of better AI is scale: more parameters, more data, and more compute.
For language models like transformers this seems to be an especially promising strategy, and empirical studies suggest that there are still substantial gains to be had with future increases in model size.
Switch transformers take this idea of scale, specifically in terms of model size, to the next level. Google described their 1.6 billion parameter Switch-C transformer on Arxiv in January 2021.
More recently, researchers at the Beijing Academy of Artificial Intelligence announced a 1.75 trillion parameter model, dubbed WuDao 2.0. WuDao was ostensibly trained with a similar mixture-of-experts type strategy to what was developed for the switch transformer, dubbed a mixture of experts implementation called FastMoE. Reliable English-language information about the model, its capabilities, and the training regime seem to be sorely lacking at the moment, but hopefully more details will be forthcoming soon.
Both of these models surpass OpenAI’s GPT-3 by an order of magnitude or close to it, but the computational costs of a forward pass are roughly equivalent to a non-sparse model with about 20 times fewer parameters. The secret in the sauce for the switch transformer (and mixture-of-experts type models in general) is that they are sparse models, selecting only a small subset of the total layers of the model to be used in a forward pass.
For the switch model this decision occurs when a router module chooses one of many feed-forward neural networks to route the attended features to after they are generated by passing through a self-attention layer. That means that while these models have more than a trillion parameters, they only activate some of them at a time, yielding comparable computational requirements to smaller models and several other advantages as well.
These differences do mean that GPT-3 retains its crown as the largest non-sparse transformer that we know of, for now, but the advantages of the switch transformer (and state-of-the-art performance on multiple benchmarks) suggest that the mixture-of-experts strategy has a lot of potential. Combined with the growing trend of multimodality, or models that combine language, image, and other types of capabilities, we may see a trend of AI models operating more like a committee of different components rather than a monolithic block. This approach actually has many conceptual similarities to a set of interesting ideas described by Marvin Minsky and Seymour Paypert from the early days of AI.
Society of Mind is a conceptual theory and eponymous book by Seymour Paypert and Marvin Minsky. The theory is at least as much cognitive psychology as it is AI, although it is in large part inspired by Minsky’s work trying to teach a robot arm to stack blocks with the help of a video camera.
Society of Mind is a way of thinking about how thinking occurs in humans as well as machines, and it posits that rather than acting as a monolithic whole, a mind can be more accurately thought of as a collection of capabilities (these can be referred to as agents) that are recruited as needed to address a given task. This is a little like how we think of the way ant swarms solve problems (which in turn inspires an entire class of algorithms), and an interesting metaphor for thinking about how the Switch Transformer operates.
Image of Minsky’s MA-3 Manipulator arm at the MIT museum.
Photograph from Wikipedia CC BY SA Rama.
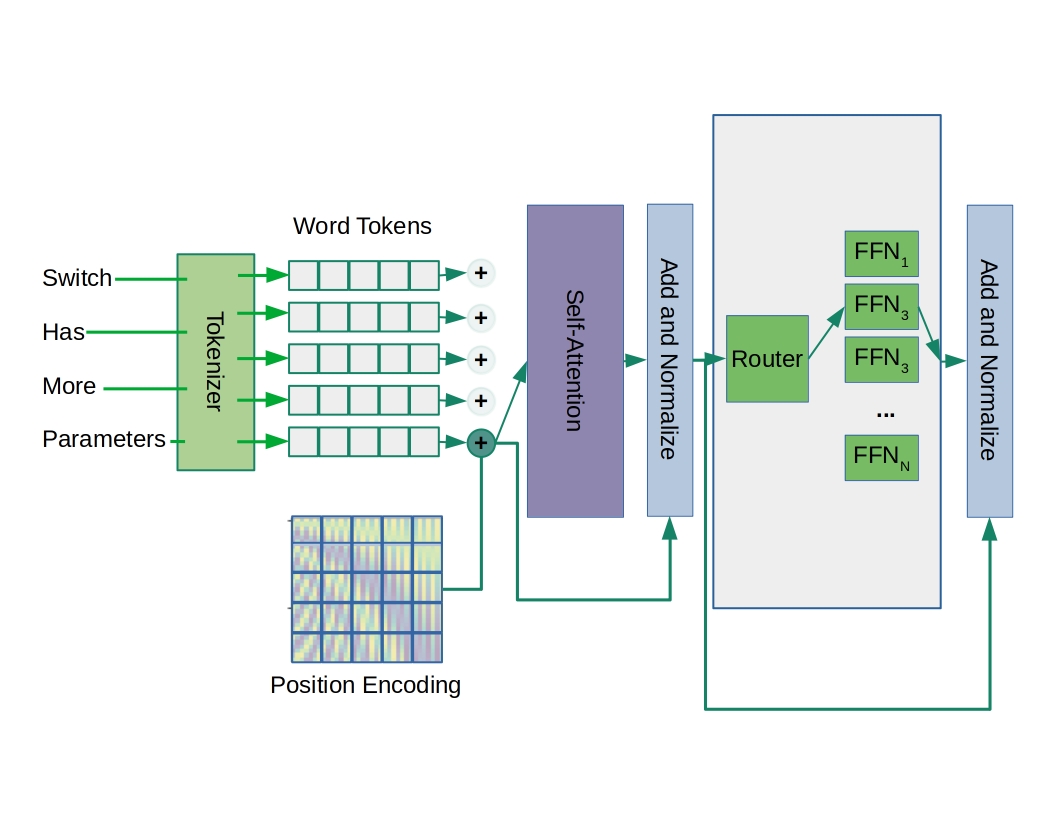
Unlike a typical dense transformer encoder layer, like those used in GPT-3 and most other transformer models, the Switch Transformer uses a routing mechanism to train a mixture of expert feed-forward layers. In the model’s main configuration, the routing and the feed-forward layers follow the self-attention layer in each encoder block. The authors also experimented with replacing the self-attention layers with switching attention layers, but found that while this did improve model quality in some cases it led to more unstable training.
Overview of switch layers used in the Switch Transformer architecture. Similar to other NLP transformer models, a sequence of text chunks are first embedded or by an embedding model known as a tokenizer. This creates vector representations of the text at a level of granularity that depends on the embedding model, shown as words in the cartoon. The vector tokens are summed together with a position encoding to allow the model to learn relationships based on relative positions, after which they are fed into a self-attention layer with multiple heads. Each head in the attention layer learns to attend to different features of the sequence, and a residual connection is used to sum and normalize the input to and output from the self-attention layer. The output from the attention layer is then given to a router layer, which decides on which expert feed-forward network to recruit, and the weight to be given to the expert layer’s output. Depending on the router’s choice, the features are passed to one of many experts, and the probability used to choose the expert layer is also used to weight its output. Another residual connection sums and normalizes the switching layer’s input and output, and the output will be passed to the next switch attention block. The largest version of the model, the Switch-C transformer, had 15 switch blocks, each with 32 attention heads and 2048 experts. In the cartoon we focus on the track taken by only one of the word-tokens, for the word “parameters,” but in practice an entire sequence will be processed by the transformer in parallel. Image source (public domain).
The Switch Transformer architecture allows for training models nearly 10 times larger than the already enormous GPT-3, but only uses the same computational requirements (and hence approximately the same number of parameters) as a model about 20 times smaller during any given forward pass.
So, are Switch Transformers actually able to perform any better than smaller models? Obviously the Switch transformer is much more efficient than a similarly-sized model that uses all parameters for each pass, but does it perform like its parameter count or like its computational requirements?
Interestingly enough, the routing strategy used by Switch architectures does improve model performance, even if the computational budget is held the same. Increasing the number of experts improves the perplexity score (a measure of how well a model understands language by how “surprised” it is by validation text), despite the number of parameters used in any forward pass staying the same. This enabled the model to achieve state-of-the-art performance on the reasoning based ANLI benchmark, as well as improving on the state-of-the-art for knowledge-based question answering benchmarks Web Questions, Natural Questions, and TriviaQA.
The authors note that while negative log perplexity is improved over the impressive 13 billion-parameter T5-XXL transformer from Colin Raffel et al., this didn’t necessarily translate to a new state-of-the art in most of the benchmarks they tested. Another caveat to the Switch architecture is that training does sometimes become unstable and diverge, especially when using the reduced-precision bfloat16 data type.
A Model Can Benefit Without Using All the Parameters
The mixture-of-experts approach taken by the Switch transformer suggests that a model doesn’t have to use all of its parameters or layers to benefit from some of the benefits of scale. This has important conceptual and practical implications for natural language processing and AI models in general.
Using only a selected portion of the layers in a model at any one time means that these layers can be more specialized, while also allowing (at least to some degree) scaling benefits to be realized even when the available hardware doesn’t have the capacity to involve all those specialized layers at once.
Perhaps it’s interesting conceptually as well in relation to how our own minds work, such as the popular belief that “humans only use 10% of their brains [at a time].” While this is largely debunked, we can certainly assert from common experience that we aren’t concentrating fully on every task all the time, and that being in the right state of mind can greatly impact mental performance.
Deep learning with sparse methods is still not as mainstream as dense methods (at least in part due to the lesser support for sparse operations on deep learning accelerators like GPUs), but the success of the Switch transformer and other prominent sparse ML phenomena like the lottery ticket hypothesis prove that sparse approaches to AI are a worthy pursuit.
Have any questions?
Contact Exxact Today
It is practically a trope in certain types of science fiction for an advanced computer system to suddenly “awaken” and become self-aware, often accompanied by vastly improved capabilities, when passing an unseen threshold in computing capacity.
Many prominent members of the AI community believe that this common element of AI in sci-fi is as much a literal prophecy as a plot device, and few are more outspoken about the promise of scale as a primary (if not the sole) driver of artificial general intelligence than Ilya Sutskever and Greg Brockman at OpenAI. Even Richard Sutton made the strong assertion that compute is king in his essay "The Bitter Lesson."
Pre-trained Transformer-3 Language Models
The latest in a line of growing language models from OpenAI, Generalized Pre-trained Transformer-3 (GPT-3 to its friends), garnered plenty of attention when it was announced in May 2020. In part, this was because GPT-3 was, at the time, significantly larger than any other non-sparse model by as much as an order of magnitude.
The full version of GPT-3 has approximately 175 billion parameters, or about two orders of magnitude more than its immediate predecessor, GPT-2, and more than 10 times as many as the previous record holder, the Turing-NLG model from Microsoft.
This year a couple of models have been published that are even larger, breaking the trillion parameter threshold for the first time. These are the Switch Transformer, published by Google in January 2021 (with accompanying code), and the mysterious and even more massive WuDao 2.0 developed at the Beijing Academy of Artificial Intelligence. In both cases researchers had to employ some clever tricks to get there, and while Switch and WuDao both have in excess of 1.5 trillion parameters, they don’t use all of them at the same time.
Can these models live up to the hype of their hugeness?
Interested in a deep learning solution for NLP research?
Learn more about Exxact workstations starting at $3700
Transformers came onto the natural language processing (NLP) scene in 2017 with the NeurIPs paper Attention is All you Need by Vaswani et al. Since then, bigger and better transformers have all but displaced the previous state-of-the art approaches that relied on recurrent connections.
Unlike recurrent networks and long short term memory models, the transformer is a type of model that’s able to parse sequential information (like speech) all in one go, instead of going through a string of words one-by-one while remembering what came earlier.
This might seem counterintuitive to humans, who are certainly used to taking in a conversation in the order it is uttered by a conversation partner. It’s almost like the language used by the mysterious hexapods in Ted Chiang’s short story, "Stories of Your Life and Others," or the film adaptation “Arrival.” The aliens in the story communicate with a written language that is taken as a gestalt and doesn’t differentiate between past, future, or present, leading to some interesting consequences. But transformer models communicate with all the temporal dependencies we humans are used to, sometimes (arguably) managing to do so quite convincingly.
How do transformers keep track of temporal/sequence based relationships between language tokens if they parse entire blocks of text at once?
For a machine learning model, units of language must typically be first converted to a format understandable to neural networks, i.e. vector arrays, and this is generally accomplished by tokenization. Tokenization is the process of embedding parts of language, which can be at the level of characters, words, or some other level of granularity, into a numerical vector format that can be understood by neural models. This is significantly better than one-hot encoding on its own, because the tokens themselves can encode useful relationships between elements of language.
However this doesn’t solve our problem of importing temporal information about word and sentence order, and for that we’ll need positional embeddings, without which an undifferentiated bundle of language tokens might be little better than a bag-of-words approach.
Encoding positions is accomplished by adding the results of a position encoding function to yield a unique and predictable fingerprint for each position. There’s more than one way to go about it, but if we follow the position encoding strategy from the TensorFlow transformer tutorial, we’ll end up with an encoding that looks something like the following:
Position encoding for switch transformer parameters
When we combine position encoding with embedded language tokens the input to our model might look a little like:
Combining tokenized embeddings of language elements (e.g. word vectors) with sinusoidal position encodings gives the transformer the information it needs to attend to both the content and the context of language sequences. The example above uses a dictionary of random vectors, whereas in practice language tokens will be the output of learned embedding models.
Of course, we wouldn’t have transformers without attention. There are multiple attention mechanisms available to choose from, but perhaps the best-known (and the type of attention used in the “Attention is all You Need” paper) is called dot-product attention, also known as self-attention.
Dot-product attention is fairly simple in principle and the name sort of gives it away. Instead of producing a single output of hidden nodes (or features) like a conventional dense neural layer, a self-attention layer (or 3 separate layers) will produce 3 vectors called key, query, and value vectors. The dot product of the key and query vectors becomes the attention weight for the value vector, and all attention weights are subjected to a softmax activation function to ensure that the total sum of attention weights is always the same and always takes a value of 1.0.
Diagram of self-attention, also known as dot-product attention or intra-attention.
Image source (public domain).
For a more detailed and quite enjoyable romp through attention and other concepts behind transformers, check out Lilian Weng’s review of attention mechanisms and/or Jay Alammar’s impressive explainer: "The Illustrated Transformer." As for us and the blog post you’re currently reading? We’ve got bigger models to fry.
Hinton makes a joke (screenshot of source).
The majority of AI and machine learning researchers think that clever ideas are what drive breakthroughs in their field, and it’s going to take some human ingenuity to eventually engineer any kind of real machine ingenuity, or artificial general intelligence.
A critic might suspect that this is an important belief to hold for purposes of maintaining conviction in one’s life work. Another group of researchers, including high-profile individuals like RL pioneer Richard Sutton and his Bitter Lesson, and at least the leadership at OpenAI, if not the entire crew, have a different theory. That is, under the scaling hypothesis, the main driver of better AI is scale: more parameters, more data, and more compute.
For language models like transformers this seems to be an especially promising strategy, and empirical studies suggest that there are still substantial gains to be had with future increases in model size.
Switch transformers take this idea of scale, specifically in terms of model size, to the next level. Google described their 1.6 billion parameter Switch-C transformer on Arxiv in January 2021.
More recently, researchers at the Beijing Academy of Artificial Intelligence announced a 1.75 trillion parameter model, dubbed WuDao 2.0. WuDao was ostensibly trained with a similar mixture-of-experts type strategy to what was developed for the switch transformer, dubbed a mixture of experts implementation called FastMoE. Reliable English-language information about the model, its capabilities, and the training regime seem to be sorely lacking at the moment, but hopefully more details will be forthcoming soon.
Both of these models surpass OpenAI’s GPT-3 by an order of magnitude or close to it, but the computational costs of a forward pass are roughly equivalent to a non-sparse model with about 20 times fewer parameters. The secret in the sauce for the switch transformer (and mixture-of-experts type models in general) is that they are sparse models, selecting only a small subset of the total layers of the model to be used in a forward pass.
For the switch model this decision occurs when a router module chooses one of many feed-forward neural networks to route the attended features to after they are generated by passing through a self-attention layer. That means that while these models have more than a trillion parameters, they only activate some of them at a time, yielding comparable computational requirements to smaller models and several other advantages as well.
These differences do mean that GPT-3 retains its crown as the largest non-sparse transformer that we know of, for now, but the advantages of the switch transformer (and state-of-the-art performance on multiple benchmarks) suggest that the mixture-of-experts strategy has a lot of potential. Combined with the growing trend of multimodality, or models that combine language, image, and other types of capabilities, we may see a trend of AI models operating more like a committee of different components rather than a monolithic block. This approach actually has many conceptual similarities to a set of interesting ideas described by Marvin Minsky and Seymour Paypert from the early days of AI.
Society of Mind is a conceptual theory and eponymous book by Seymour Paypert and Marvin Minsky. The theory is at least as much cognitive psychology as it is AI, although it is in large part inspired by Minsky’s work trying to teach a robot arm to stack blocks with the help of a video camera.
Society of Mind is a way of thinking about how thinking occurs in humans as well as machines, and it posits that rather than acting as a monolithic whole, a mind can be more accurately thought of as a collection of capabilities (these can be referred to as agents) that are recruited as needed to address a given task. This is a little like how we think of the way ant swarms solve problems (which in turn inspires an entire class of algorithms), and an interesting metaphor for thinking about how the Switch Transformer operates.
Image of Minsky’s MA-3 Manipulator arm at the MIT museum.
Photograph from Wikipedia CC BY SA Rama.
Unlike a typical dense transformer encoder layer, like those used in GPT-3 and most other transformer models, the Switch Transformer uses a routing mechanism to train a mixture of expert feed-forward layers. In the model’s main configuration, the routing and the feed-forward layers follow the self-attention layer in each encoder block. The authors also experimented with replacing the self-attention layers with switching attention layers, but found that while this did improve model quality in some cases it led to more unstable training.
Overview of switch layers used in the Switch Transformer architecture. Similar to other NLP transformer models, a sequence of text chunks are first embedded or by an embedding model known as a tokenizer. This creates vector representations of the text at a level of granularity that depends on the embedding model, shown as words in the cartoon. The vector tokens are summed together with a position encoding to allow the model to learn relationships based on relative positions, after which they are fed into a self-attention layer with multiple heads. Each head in the attention layer learns to attend to different features of the sequence, and a residual connection is used to sum and normalize the input to and output from the self-attention layer. The output from the attention layer is then given to a router layer, which decides on which expert feed-forward network to recruit, and the weight to be given to the expert layer’s output. Depending on the router’s choice, the features are passed to one of many experts, and the probability used to choose the expert layer is also used to weight its output. Another residual connection sums and normalizes the switching layer’s input and output, and the output will be passed to the next switch attention block. The largest version of the model, the Switch-C transformer, had 15 switch blocks, each with 32 attention heads and 2048 experts. In the cartoon we focus on the track taken by only one of the word-tokens, for the word “parameters,” but in practice an entire sequence will be processed by the transformer in parallel. Image source (public domain).
The Switch Transformer architecture allows for training models nearly 10 times larger than the already enormous GPT-3, but only uses the same computational requirements (and hence approximately the same number of parameters) as a model about 20 times smaller during any given forward pass.
So, are Switch Transformers actually able to perform any better than smaller models? Obviously the Switch transformer is much more efficient than a similarly-sized model that uses all parameters for each pass, but does it perform like its parameter count or like its computational requirements?
Interestingly enough, the routing strategy used by Switch architectures does improve model performance, even if the computational budget is held the same. Increasing the number of experts improves the perplexity score (a measure of how well a model understands language by how “surprised” it is by validation text), despite the number of parameters used in any forward pass staying the same. This enabled the model to achieve state-of-the-art performance on the reasoning based ANLI benchmark, as well as improving on the state-of-the-art for knowledge-based question answering benchmarks Web Questions, Natural Questions, and TriviaQA.
The authors note that while negative log perplexity is improved over the impressive 13 billion-parameter T5-XXL transformer from Colin Raffel et al., this didn’t necessarily translate to a new state-of-the art in most of the benchmarks they tested. Another caveat to the Switch architecture is that training does sometimes become unstable and diverge, especially when using the reduced-precision bfloat16 data type.
A Model Can Benefit Without Using All the Parameters
The mixture-of-experts approach taken by the Switch transformer suggests that a model doesn’t have to use all of its parameters or layers to benefit from some of the benefits of scale. This has important conceptual and practical implications for natural language processing and AI models in general.
Using only a selected portion of the layers in a model at any one time means that these layers can be more specialized, while also allowing (at least to some degree) scaling benefits to be realized even when the available hardware doesn’t have the capacity to involve all those specialized layers at once.
Perhaps it’s interesting conceptually as well in relation to how our own minds work, such as the popular belief that “humans only use 10% of their brains [at a time].” While this is largely debunked, we can certainly assert from common experience that we aren’t concentrating fully on every task all the time, and that being in the right state of mind can greatly impact mental performance.
Deep learning with sparse methods is still not as mainstream as dense methods (at least in part due to the lesser support for sparse operations on deep learning accelerators like GPUs), but the success of the Switch transformer and other prominent sparse ML phenomena like the lottery ticket hypothesis prove that sparse approaches to AI are a worthy pursuit.
Have any questions?
Contact Exxact Today