Artificial Intelligence
7 Open Source Libraries for Deep Learning Graphs
May 25, 2021
22 min read

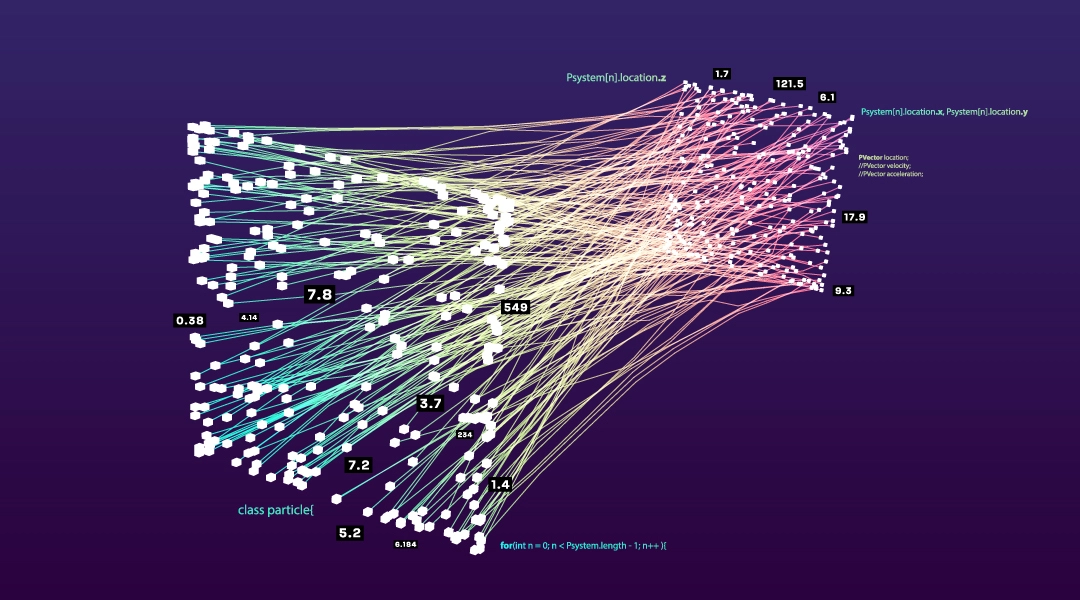
If you’re a deep learning enthusiast you’re probably already familiar with some of the basic mathematical primitives that have been driving the impressive capabilities of what we call deep neural networks. Although we like to think of a basic artificial neural network as some nodes with some weighted connections, it’s more efficient computationally to think of neural networks as matrix multiplication all the way down. We might draw a cartoon of an artificial neural network like the figure below, with information traveling in from left to right from inputs to outputs (ignoring recurrent networks for now).
Multilayer perceptron cartoon in the public domain, Source
This type of neural network is a feed-forward multilayer perceptron (MLP). If we want a computer to compute the forward pass for this model, it’s going to use a string of matrix multiplies and some sort of non-linearity (here represented by the Greek letter sigma) in the hidden layer:
MLP matrix multiplication cartoon in the public domain, Source
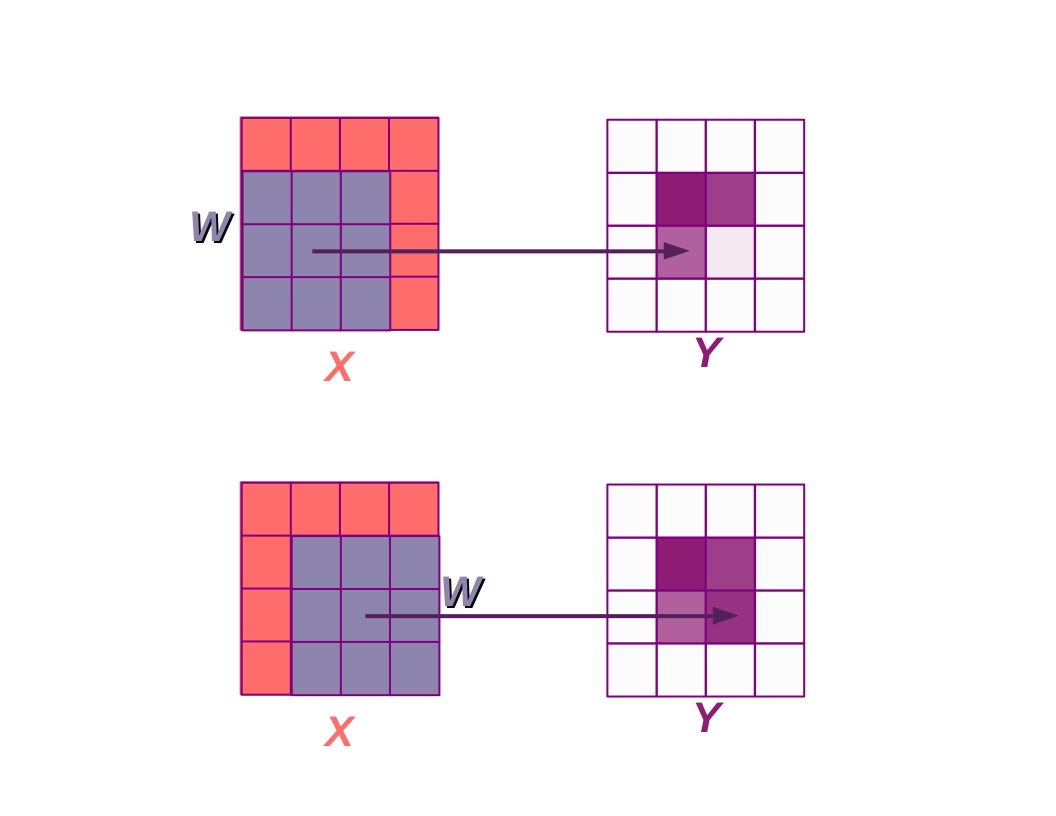
MLPs are well-suited for data that can be naturally shaped as 1D vectors. While neat and all, MLPs use an awful lot of parameters when data samples are large, and this isn’t a very efficient way to treat higher dimensional data like 2D images or 3D volumes. 2D data like images instead naturally lend themselves to the operation of convolution, wherein weights are applied in local neighborhoods across the entire image, instead of granting each point to point connection between layers it’s own weight. This type of weight sharing has a number of advantages, including translation equivariance, regularization, and parameter efficiency.
Convolution can be visualized like so:
Convolution cartoon in the public domain, Source
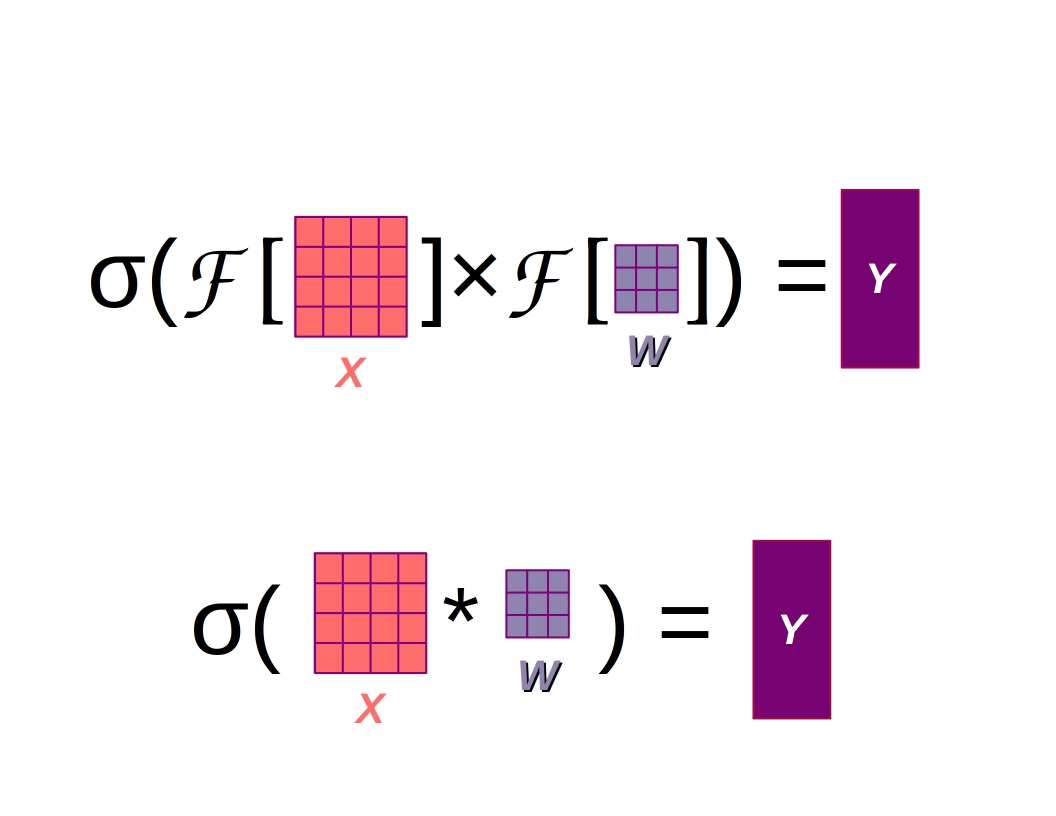
Of course we’re not going to sit down with pen and paper and perform these operations by hand, we want an algorithm that can quickly perform convolution across each image channel in a computer-friendly way.
In principle, computers perform convolutions something like the following:
Convolution as multiplication of matrices in the Fourier domain cartoon in the public domain, Source
That’s right, convolution operations are again implemented as the multiplication of matrices, although this time it is element-wise. This is thanks to the convolution theorem of the Fourier transform, which states that multiplication in the Fourier domain relates to convolution in the spatial domain. But what happens when our data of interest isn’t particularly well-suited to representation as a 1D vector or a 2D/3D image, and is instead naturally represented as a graph?
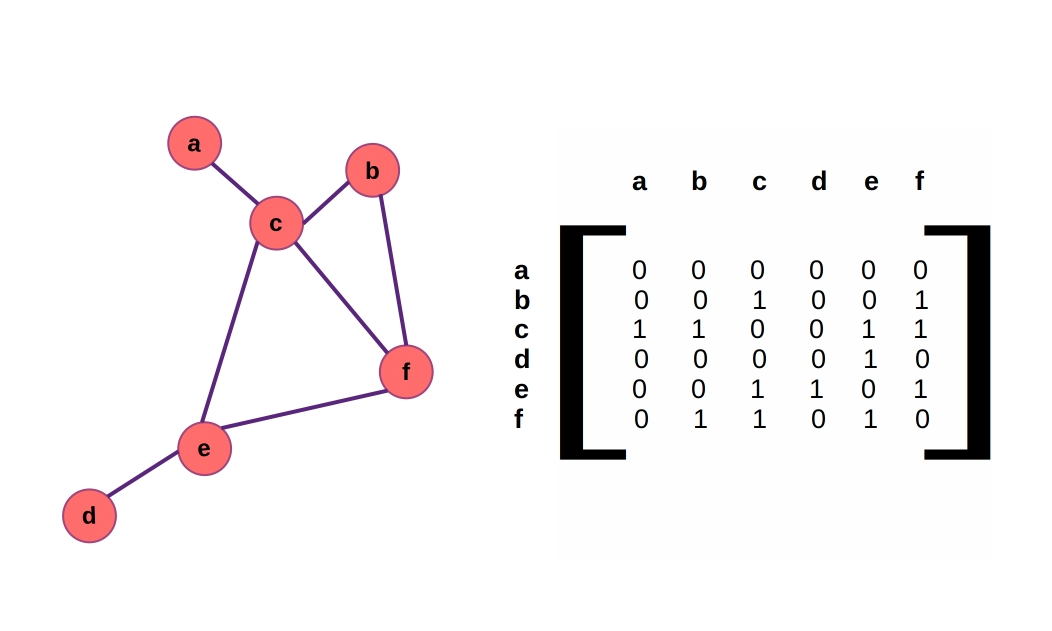
Graph cartoon in the public domain, Source
For our purposes, a graph is a collection of nodes connected by edges, as shown in the cartoon. The edges can have their own properties such as weights and/or directionality, and the nodes typically have some sort of states or features, just like the node activations in a feed-forward MLP.
In a graph neural network, each “layer” is just a snapshot of the node states of the graph, and these are connected by operational updates related to each node and its neighbors, such as neural networks operating as the edges between nodes.
If we want to use graph neural networks to achieve impressive results on graph-structured data, like what convolutional neural networks did for deep learning on images, we need an efficient way to implement these models on computers. That almost always means we need a way to convert the conceptual graph neural network framework to something that works on a modern deep learning GPU.
Interested in a deep learning workstation?
Learn more about Exxact AI workstations starting at $3,700
A convenient way to represent the connections in a graph is with something called an adjacency matrix. As the name suggests, an adjacency matrix describes which nodes are next to each other (i.e. connected to each other by edges) in the graph.
But a graph neural network needs to operate on graphs with arbitrary structure (much like the convolutional kernels of a conv-net can work on images of different height and width), so we can’t expect the input data to have the same adjacency matrix each time or even for each adjacency matrix to have the same dimensions. We can deal with this by combining the adjacency matrices for several samples diagonally into a larger matrix describing all the connections in a batch.
This allows us to deal with multiple graphs with different structures in a single batch, and you’ll notice that this formulation also results in weight sharing between nodes. There are a few more details to this: the adjacency matrix should be normalized so that feature scales don’t completely change, and there are other approaches to convolution on graphs than the graph convolution network approach (GCN) we are talking about here, but it’s a good starting point in understanding the GNN forward pass.
It’s enough to give us an appreciation for the data preparation and mathematical operations needed to implement deep learning on graphs. Luckily, the interest in deep learning for graph-structured data has motivated the development of a number of open source libraries for graph deep learning, leaving more cognitive room for researchers and engineers to concentrate on architectures, experiments, and applications.
In this article we’ll go through 7 up-and-coming open source libraries for graph deep learning, ranked in order of increasing popularity.
Reflecting the dominance of the language for graph deep learning, and for deep learning in general, most of the entries on this list use Python and are built on top of TensorFlow, PyTorch, or JAX. This first entry, however, is an open source library for graph neural networks built on the Flux deep learning framework in the Julia programming language.
One may be tempted to write off GeometricFlux.jl, and even the whole idea of using the Julia language for deep learning due to the relatively small number of practitioners, but it is a language with a growing community and offers a number of technical advantages over Python. One would have hardly predicted DeepMind would start ditching TensorFlow in favor of JAX just a few years ago (see entry number 5 on this list), and likewise in just a few short years we may see the Julia language start to supplant Python as the standard language for machine learning.
The Julia programming language was designed from the start to be both highly productive (like Python), and fast like compiled languages including C. Julia language uses just-in-time compilation to achieve fast execution speed, while it’s read-execute-print loop (REPL) makes interactive and iterative programming reasonably productive. You will notice a slight delay when you run code for the first time, especially if you’re used to using Python in a particularly interactive way (like in Jupyter notebooks), but over time the speed-ups for a given workflow can be significant.
Julia is designed as a scientific programming language, and there has been significant development of automatic differentiation packages over the last five years or so. The end result is functionality that can combine research-centered libraries like the DifferentialEquations.jl package with machine learning capabilities as we see in the neural differential equations package DiffEqFlux.jl. The same goes for GeometricFlux.jl, which is built to be compatible with the graph theory research JuliaGraphs ecosystem as well as other parts of Flux.
If you’re using graph deep learning for work, it may be most efficient to stick with a library that’s built on PyTorch or the standard working framework for deep learning used for other projects. If you’re starting from scratch or doing research, however, GeometricFlux.jl makes a compelling entry point for graph deep learning and differentiable programming with Julia. The library’s friendly MIT License also makes it easy to build and contribute the tools you need, or to tackle some of the open issues from the project’s GitHub repository.
The PyTorch Graph Neural Network library is a graph deep learning library from Microsoft, still under active development at version ~0.9.x after being made public in May of 2020. PTGNN is made to be readily familiar for users familiar with building models based on the torch.nn.Module class, and handles the workflow tasks of dataloaders and turning graphs into PyTorch-ready tensors.
PTGNN is based on an interesting architecture called the AbstractNeuralModel. This class encapsulates the entire process of training a graph neural network including tensorizing and pre-proccessing raw data, and includes the TNeuralModule that is the actual neural model sub-classed from PyTorch’s nn.Module class. The neural modules can be used independently of the AbstractNeuralModel object, and in fact can be combined with other types of PyTorch modules/layers if desired.
PTGNN is slightly younger than GeometricFlux.jl and has a less active commit history, but ekes out slightly more GitHub stars and forks. It has the same permissive and open source MIT License, but if you’re looking for a project to contribute to, you’ll need to be fairly self-directed. The “Issues” tab on GitHub provides little to no direction of what needs to be fixed or implemented. PTGNN has a few interesting design elements in its construction that may be of interest to work with or on, but if you’re a graph neural network enthusiast looking for a PyTorch-based graph deep learning library you may be better served by using PyTorch Geometric (number 1 on our list). PyTorch Geometric is more mature, having been in development for about 4 years now, and has an established and growing community of users and developers.
Late last year you may have noticed a blog post from DeepMind with a little less pomp and circumstance than their usual headline-grabbing landmarks. In December 2020 Deepmind described their ongoing efforts in developing and using a capable ecosystem of deep learning research libraries based on the functional differentiable programming library JAX. JAX is the conceptual progeny of what started as an academic project for simple but nigh-universal automatic differentiation in Python (especially NumPy) called Autograd.
After Google scooped up several of the research programmers responsible for the original Autograd, they developed a new library and now we have JAX. JAX is an interesting package due in no small part to its emphasis on composable functional programming paradigms. It also pays attention to the more general concept of “differentiable programming” rather than focusing primarily on neural networks like TensorFlow or PyTorch. Although PyTorch and TensorFlow can both be used to build, say, differentiable physics models instead of neural networks, JAX is more readily amenable to flexible differentiable programming for scientific and other programming tasks from the start. The JAX offering is compelling enough, at least, to induce DeepMind to embark on a substantial adoption and development track, despite having previously spent significant time building TensorFlow-based tools like Sonnet.
As part of DeepMind’s efforts to develop a JAX-based ecosystem for deep learning research they’ve developed a graph learning library called Jraph.
Original image in the public domain from Wikimedia contributor Scambelo
Unlike some of the other libraries on this list, Jraph is a lightweight and minimalistic graph learning library that doesn’t in general prescribe a specific way for working with itself. Jraph inherited some design patterns from a spiritual predecessor, Graph Nets, built with TensorFlow and Sonnet. Namely, Jraph uses the same GraphsTuple concept as Graph Nets, which is a data structure containing infromation describing nodes, edges, and edge directions. Another feature handled by Jraph, makes special accommodations for dealing with variable-structured graphs using masks and padding. That’s not a concern for most of the other Python libraries on this list, but it’s necessary due to the use of just-in-time compilation in JAX. This ensures that working with graphs in JAX doesn’t mean giving up the execution speedups JAX provides on both GPU and CPU hardware.
Spektral logos used under the MIT License, from the Spektral documentation.
Spektral is a graph deep learning library based on Tensorflow 2 and Keras, and with a logo clearly inspired by the Pac-Man ghost villains. If you are set on using a TensorFlow-based library for your graph deep learning needs, Spektral may be your best option (although DGL, number 2 on our list, can support both PyTorch or TensorFlow back-ends). It’s designed to be easy-to-use and flexible, while retaining usage that is as close as possible to the familiar Keras API. This means that you can even train a model using the convenient model.fit() method, so long as you provide a Spetkral dataloader to handle the formation of TensorFlow friendly sparse matrices defining the graph. Unfortunately there is a trade-off for the ease-of-use of Spektral, and this comes in the form of noticeably slower training speeds for most tasks compared to the other major libraries DGL and PyTorch Geometric.
Spektral has significant adoption and it may be an appealing option should you want to build graph models with TensorFlow. It’s likely to be better supported than the Graph Nets library by Deepmind, which is next on our list but for all appearances is being phased out in favor of the JAX-based Jraph. Spektral is released under the Apache 2.0 open source license and has an active issues board with pull requests being integrated on a regular basis, making this an appealing library for someone wishing to not only use a good deep learning library, but contribute to one as well.
Graph Nets is another graph deep learning from Deepmind. Built on TensorFlow and Sonnet (another DeepMind library), it may soon be largely superseded by the JAX-based Jraph described earlier. Graph Nets requires TensorFlow 1, and as a result it feels somewhat dated despite being only about 3 years old. As of this writing, It has an impressive 737 forks and nearly 5,000 stars on GitHub, and, like most other libraries from Google/DeepMind, is licensed under Apache 2.0. Graph Nets originated the GraphsTuple data structure used by Jraph.
While Graph Nets seems to be quite popular on GitHub, it is probably a less attractive option than the other libraries on this list, unless you are working on a pre-existing code base that already makes heavy use of the library. For new projects with TensforFlow, Spektral and DGL are probably a better bet, as they’re built with more up-to-date technology and likely to continue to receive decent support for a few years.
Rather than being associated with a major tech company like Microsoft’s PTGNN or Google/DeepMind’s Jraph and Graph Nets, DGL is the product of a group of deep learning enthusiasts called the Distributed Deep Machine Learning Community. It has over 100 contributors, over 1500 commits, and over 7,000 stars on GitHub. DGL is also unique in our list for offering a flexible choice of back-end. Models can have PyTorch, TensorFlow, or MXNet running under the hood, while offering a largely similar experience to the one driving an experiment. It’s one of the longer-lived libraries still under active development on our list, with a first commit going back to April 2018. DGL was used recently to build the SE(3) transformer, a powerful graph transformer with both rotational and translational equivariance that is suspected to be a building block or inspiration for AlphaFold2. This model, the successor to the already impressive AlphaFold, was the star behind DeepMind’s impressive, show-winning performance at the 2020 CASP14 protein structure prediction challenge. That event prompted some major news outlets to herald AlphaFold2 as the first AI project to solve a major scientific challenge.
DGL is built around the neural message passing paradigm described by Gilmer et al. in 2017. This provides a flexible framework and it covers most types of graph layers for building graph neural networks. As you’ll notice from reading through the code repository and documentation, DGL is an expansive project. This also means there are plenty (nearly 200) open issues, a ripe opportunity for someone looking to contribute to a graph deep learning project with a big impact. DGL is used for a number of specialized applications, to the extent where several additional libraries have been built on top of it. DGL-LifeSci is a library built specifically for deep learning graphs as applied to chem- and bio-informatics, while DGL-KE is built for working with knowledge graph embeddings. Both of those bonus libraries are developed by AWS Labs.
The library topping our list is none other than PyTorch Geometric. PyTorch Geometric, or PyG to friends, is a mature geometric deep learning library with over 10,000 stars and 4400 commits, most of these being the output of one very prolific PhD student rusty1s. PyG sports a very long list of implemented graph neural network layers. Not only does it run deep graph networks quite quickly, but PyG is also built for other types of geometric deep learning such as point cloud and mesh-based models.
PyG has a well written tutorial introduction by example, and having been developed since 2017, it’s pretty well established and well-supported by a community of users and just over 140 contributors. Using PyG will be very familiar for anyone who has worked with PyTorch before, with the most noticeable difference being some differences in the data input. Instead of the usual forward(x) programming pattern, you’ll instead get used to using forward(batch), where batch is a data structure that contains all the information describing graph features and connections.
For new projects with a free hand in choosing a library, PyTorch Geometric is pretty tough to beat.
For example, here’s how the libraries compare to each other:
Name | License | Stars | Language, Flavor | Main Contributor(s) |
MIT | 180 | Julia Language, Flux.jl | ||
MIT | 206 | Python, PyTorch | Microsoft | |
Apache 2.0 | 536 | Python, JAX | DeepMind | |
MIT | 1,700 | Python, TF2/keras | ||
Apache 2.0 | 4,800 | Python, PyTorch | DeepMind | |
Apache 2.0 | 7,000 | Python, PyTorch, TF, MxNet | ||
MIT | 10,600 | Python, PyTorch |
In many cases, your choice of a deep graph learning library will be heavily influenced by a previous choice of deep learning library made by you, your employer, or maybe your supervising professor. If you are fond of the Keras API and TensorFlow or need to retain consistent dependencies with a pre-existing code base, for example, Spektral may be the right library for you. We wouldn’t recommend starting a new project with DeepMind’s Graph Nets and TensorFlow 1, but the library does still get occasional updates and may be a reasonable choice to support legacy projects.
If you’re lucky enough to be starting from scratch, you have a couple of enticing options. If you think the deliberate productivity + execution speed prioritization of the Julia Programming is the future of machine learning and scientific programming, GeometricFlux.jl is an exciting prospect. If you are intrigued by functional programming paradigms and want to retain some of the speed advantages from just-in-time compilation (like Julia) but would prefer to stick with Python, the JAX-based Jraph is an attractive option. Finally, if you want a fast, capable library at a relatively established and mature state of development, it’s going to be hard to go wrong with PyTorch Geometric.
Have any questions?
Contact Exxact Today
If you’re a deep learning enthusiast you’re probably already familiar with some of the basic mathematical primitives that have been driving the impressive capabilities of what we call deep neural networks. Although we like to think of a basic artificial neural network as some nodes with some weighted connections, it’s more efficient computationally to think of neural networks as matrix multiplication all the way down. We might draw a cartoon of an artificial neural network like the figure below, with information traveling in from left to right from inputs to outputs (ignoring recurrent networks for now).
Multilayer perceptron cartoon in the public domain, Source
This type of neural network is a feed-forward multilayer perceptron (MLP). If we want a computer to compute the forward pass for this model, it’s going to use a string of matrix multiplies and some sort of non-linearity (here represented by the Greek letter sigma) in the hidden layer:
MLP matrix multiplication cartoon in the public domain, Source
MLPs are well-suited for data that can be naturally shaped as 1D vectors. While neat and all, MLPs use an awful lot of parameters when data samples are large, and this isn’t a very efficient way to treat higher dimensional data like 2D images or 3D volumes. 2D data like images instead naturally lend themselves to the operation of convolution, wherein weights are applied in local neighborhoods across the entire image, instead of granting each point to point connection between layers it’s own weight. This type of weight sharing has a number of advantages, including translation equivariance, regularization, and parameter efficiency.
Convolution can be visualized like so:
Convolution cartoon in the public domain, Source
Of course we’re not going to sit down with pen and paper and perform these operations by hand, we want an algorithm that can quickly perform convolution across each image channel in a computer-friendly way.
In principle, computers perform convolutions something like the following:
Convolution as multiplication of matrices in the Fourier domain cartoon in the public domain, Source
That’s right, convolution operations are again implemented as the multiplication of matrices, although this time it is element-wise. This is thanks to the convolution theorem of the Fourier transform, which states that multiplication in the Fourier domain relates to convolution in the spatial domain. But what happens when our data of interest isn’t particularly well-suited to representation as a 1D vector or a 2D/3D image, and is instead naturally represented as a graph?
Graph cartoon in the public domain, Source
For our purposes, a graph is a collection of nodes connected by edges, as shown in the cartoon. The edges can have their own properties such as weights and/or directionality, and the nodes typically have some sort of states or features, just like the node activations in a feed-forward MLP.
In a graph neural network, each “layer” is just a snapshot of the node states of the graph, and these are connected by operational updates related to each node and its neighbors, such as neural networks operating as the edges between nodes.
If we want to use graph neural networks to achieve impressive results on graph-structured data, like what convolutional neural networks did for deep learning on images, we need an efficient way to implement these models on computers. That almost always means we need a way to convert the conceptual graph neural network framework to something that works on a modern deep learning GPU.
Interested in a deep learning workstation?
Learn more about Exxact AI workstations starting at $3,700
A convenient way to represent the connections in a graph is with something called an adjacency matrix. As the name suggests, an adjacency matrix describes which nodes are next to each other (i.e. connected to each other by edges) in the graph.
But a graph neural network needs to operate on graphs with arbitrary structure (much like the convolutional kernels of a conv-net can work on images of different height and width), so we can’t expect the input data to have the same adjacency matrix each time or even for each adjacency matrix to have the same dimensions. We can deal with this by combining the adjacency matrices for several samples diagonally into a larger matrix describing all the connections in a batch.
This allows us to deal with multiple graphs with different structures in a single batch, and you’ll notice that this formulation also results in weight sharing between nodes. There are a few more details to this: the adjacency matrix should be normalized so that feature scales don’t completely change, and there are other approaches to convolution on graphs than the graph convolution network approach (GCN) we are talking about here, but it’s a good starting point in understanding the GNN forward pass.
It’s enough to give us an appreciation for the data preparation and mathematical operations needed to implement deep learning on graphs. Luckily, the interest in deep learning for graph-structured data has motivated the development of a number of open source libraries for graph deep learning, leaving more cognitive room for researchers and engineers to concentrate on architectures, experiments, and applications.
In this article we’ll go through 7 up-and-coming open source libraries for graph deep learning, ranked in order of increasing popularity.
Reflecting the dominance of the language for graph deep learning, and for deep learning in general, most of the entries on this list use Python and are built on top of TensorFlow, PyTorch, or JAX. This first entry, however, is an open source library for graph neural networks built on the Flux deep learning framework in the Julia programming language.
One may be tempted to write off GeometricFlux.jl, and even the whole idea of using the Julia language for deep learning due to the relatively small number of practitioners, but it is a language with a growing community and offers a number of technical advantages over Python. One would have hardly predicted DeepMind would start ditching TensorFlow in favor of JAX just a few years ago (see entry number 5 on this list), and likewise in just a few short years we may see the Julia language start to supplant Python as the standard language for machine learning.
The Julia programming language was designed from the start to be both highly productive (like Python), and fast like compiled languages including C. Julia language uses just-in-time compilation to achieve fast execution speed, while it’s read-execute-print loop (REPL) makes interactive and iterative programming reasonably productive. You will notice a slight delay when you run code for the first time, especially if you’re used to using Python in a particularly interactive way (like in Jupyter notebooks), but over time the speed-ups for a given workflow can be significant.
Julia is designed as a scientific programming language, and there has been significant development of automatic differentiation packages over the last five years or so. The end result is functionality that can combine research-centered libraries like the DifferentialEquations.jl package with machine learning capabilities as we see in the neural differential equations package DiffEqFlux.jl. The same goes for GeometricFlux.jl, which is built to be compatible with the graph theory research JuliaGraphs ecosystem as well as other parts of Flux.
If you’re using graph deep learning for work, it may be most efficient to stick with a library that’s built on PyTorch or the standard working framework for deep learning used for other projects. If you’re starting from scratch or doing research, however, GeometricFlux.jl makes a compelling entry point for graph deep learning and differentiable programming with Julia. The library’s friendly MIT License also makes it easy to build and contribute the tools you need, or to tackle some of the open issues from the project’s GitHub repository.
The PyTorch Graph Neural Network library is a graph deep learning library from Microsoft, still under active development at version ~0.9.x after being made public in May of 2020. PTGNN is made to be readily familiar for users familiar with building models based on the torch.nn.Module class, and handles the workflow tasks of dataloaders and turning graphs into PyTorch-ready tensors.
PTGNN is based on an interesting architecture called the AbstractNeuralModel. This class encapsulates the entire process of training a graph neural network including tensorizing and pre-proccessing raw data, and includes the TNeuralModule that is the actual neural model sub-classed from PyTorch’s nn.Module class. The neural modules can be used independently of the AbstractNeuralModel object, and in fact can be combined with other types of PyTorch modules/layers if desired.
PTGNN is slightly younger than GeometricFlux.jl and has a less active commit history, but ekes out slightly more GitHub stars and forks. It has the same permissive and open source MIT License, but if you’re looking for a project to contribute to, you’ll need to be fairly self-directed. The “Issues” tab on GitHub provides little to no direction of what needs to be fixed or implemented. PTGNN has a few interesting design elements in its construction that may be of interest to work with or on, but if you’re a graph neural network enthusiast looking for a PyTorch-based graph deep learning library you may be better served by using PyTorch Geometric (number 1 on our list). PyTorch Geometric is more mature, having been in development for about 4 years now, and has an established and growing community of users and developers.
Late last year you may have noticed a blog post from DeepMind with a little less pomp and circumstance than their usual headline-grabbing landmarks. In December 2020 Deepmind described their ongoing efforts in developing and using a capable ecosystem of deep learning research libraries based on the functional differentiable programming library JAX. JAX is the conceptual progeny of what started as an academic project for simple but nigh-universal automatic differentiation in Python (especially NumPy) called Autograd.
After Google scooped up several of the research programmers responsible for the original Autograd, they developed a new library and now we have JAX. JAX is an interesting package due in no small part to its emphasis on composable functional programming paradigms. It also pays attention to the more general concept of “differentiable programming” rather than focusing primarily on neural networks like TensorFlow or PyTorch. Although PyTorch and TensorFlow can both be used to build, say, differentiable physics models instead of neural networks, JAX is more readily amenable to flexible differentiable programming for scientific and other programming tasks from the start. The JAX offering is compelling enough, at least, to induce DeepMind to embark on a substantial adoption and development track, despite having previously spent significant time building TensorFlow-based tools like Sonnet.
As part of DeepMind’s efforts to develop a JAX-based ecosystem for deep learning research they’ve developed a graph learning library called Jraph.
Original image in the public domain from Wikimedia contributor Scambelo
Unlike some of the other libraries on this list, Jraph is a lightweight and minimalistic graph learning library that doesn’t in general prescribe a specific way for working with itself. Jraph inherited some design patterns from a spiritual predecessor, Graph Nets, built with TensorFlow and Sonnet. Namely, Jraph uses the same GraphsTuple concept as Graph Nets, which is a data structure containing infromation describing nodes, edges, and edge directions. Another feature handled by Jraph, makes special accommodations for dealing with variable-structured graphs using masks and padding. That’s not a concern for most of the other Python libraries on this list, but it’s necessary due to the use of just-in-time compilation in JAX. This ensures that working with graphs in JAX doesn’t mean giving up the execution speedups JAX provides on both GPU and CPU hardware.
Spektral logos used under the MIT License, from the Spektral documentation.
Spektral is a graph deep learning library based on Tensorflow 2 and Keras, and with a logo clearly inspired by the Pac-Man ghost villains. If you are set on using a TensorFlow-based library for your graph deep learning needs, Spektral may be your best option (although DGL, number 2 on our list, can support both PyTorch or TensorFlow back-ends). It’s designed to be easy-to-use and flexible, while retaining usage that is as close as possible to the familiar Keras API. This means that you can even train a model using the convenient model.fit() method, so long as you provide a Spetkral dataloader to handle the formation of TensorFlow friendly sparse matrices defining the graph. Unfortunately there is a trade-off for the ease-of-use of Spektral, and this comes in the form of noticeably slower training speeds for most tasks compared to the other major libraries DGL and PyTorch Geometric.
Spektral has significant adoption and it may be an appealing option should you want to build graph models with TensorFlow. It’s likely to be better supported than the Graph Nets library by Deepmind, which is next on our list but for all appearances is being phased out in favor of the JAX-based Jraph. Spektral is released under the Apache 2.0 open source license and has an active issues board with pull requests being integrated on a regular basis, making this an appealing library for someone wishing to not only use a good deep learning library, but contribute to one as well.
Graph Nets is another graph deep learning from Deepmind. Built on TensorFlow and Sonnet (another DeepMind library), it may soon be largely superseded by the JAX-based Jraph described earlier. Graph Nets requires TensorFlow 1, and as a result it feels somewhat dated despite being only about 3 years old. As of this writing, It has an impressive 737 forks and nearly 5,000 stars on GitHub, and, like most other libraries from Google/DeepMind, is licensed under Apache 2.0. Graph Nets originated the GraphsTuple data structure used by Jraph.
While Graph Nets seems to be quite popular on GitHub, it is probably a less attractive option than the other libraries on this list, unless you are working on a pre-existing code base that already makes heavy use of the library. For new projects with TensforFlow, Spektral and DGL are probably a better bet, as they’re built with more up-to-date technology and likely to continue to receive decent support for a few years.
Rather than being associated with a major tech company like Microsoft’s PTGNN or Google/DeepMind’s Jraph and Graph Nets, DGL is the product of a group of deep learning enthusiasts called the Distributed Deep Machine Learning Community. It has over 100 contributors, over 1500 commits, and over 7,000 stars on GitHub. DGL is also unique in our list for offering a flexible choice of back-end. Models can have PyTorch, TensorFlow, or MXNet running under the hood, while offering a largely similar experience to the one driving an experiment. It’s one of the longer-lived libraries still under active development on our list, with a first commit going back to April 2018. DGL was used recently to build the SE(3) transformer, a powerful graph transformer with both rotational and translational equivariance that is suspected to be a building block or inspiration for AlphaFold2. This model, the successor to the already impressive AlphaFold, was the star behind DeepMind’s impressive, show-winning performance at the 2020 CASP14 protein structure prediction challenge. That event prompted some major news outlets to herald AlphaFold2 as the first AI project to solve a major scientific challenge.
DGL is built around the neural message passing paradigm described by Gilmer et al. in 2017. This provides a flexible framework and it covers most types of graph layers for building graph neural networks. As you’ll notice from reading through the code repository and documentation, DGL is an expansive project. This also means there are plenty (nearly 200) open issues, a ripe opportunity for someone looking to contribute to a graph deep learning project with a big impact. DGL is used for a number of specialized applications, to the extent where several additional libraries have been built on top of it. DGL-LifeSci is a library built specifically for deep learning graphs as applied to chem- and bio-informatics, while DGL-KE is built for working with knowledge graph embeddings. Both of those bonus libraries are developed by AWS Labs.
The library topping our list is none other than PyTorch Geometric. PyTorch Geometric, or PyG to friends, is a mature geometric deep learning library with over 10,000 stars and 4400 commits, most of these being the output of one very prolific PhD student rusty1s. PyG sports a very long list of implemented graph neural network layers. Not only does it run deep graph networks quite quickly, but PyG is also built for other types of geometric deep learning such as point cloud and mesh-based models.
PyG has a well written tutorial introduction by example, and having been developed since 2017, it’s pretty well established and well-supported by a community of users and just over 140 contributors. Using PyG will be very familiar for anyone who has worked with PyTorch before, with the most noticeable difference being some differences in the data input. Instead of the usual forward(x) programming pattern, you’ll instead get used to using forward(batch), where batch is a data structure that contains all the information describing graph features and connections.
For new projects with a free hand in choosing a library, PyTorch Geometric is pretty tough to beat.
For example, here’s how the libraries compare to each other:
Name | License | Stars | Language, Flavor | Main Contributor(s) |
MIT | 180 | Julia Language, Flux.jl | ||
MIT | 206 | Python, PyTorch | Microsoft | |
Apache 2.0 | 536 | Python, JAX | DeepMind | |
MIT | 1,700 | Python, TF2/keras | ||
Apache 2.0 | 4,800 | Python, PyTorch | DeepMind | |
Apache 2.0 | 7,000 | Python, PyTorch, TF, MxNet | ||
MIT | 10,600 | Python, PyTorch |
In many cases, your choice of a deep graph learning library will be heavily influenced by a previous choice of deep learning library made by you, your employer, or maybe your supervising professor. If you are fond of the Keras API and TensorFlow or need to retain consistent dependencies with a pre-existing code base, for example, Spektral may be the right library for you. We wouldn’t recommend starting a new project with DeepMind’s Graph Nets and TensorFlow 1, but the library does still get occasional updates and may be a reasonable choice to support legacy projects.
If you’re lucky enough to be starting from scratch, you have a couple of enticing options. If you think the deliberate productivity + execution speed prioritization of the Julia Programming is the future of machine learning and scientific programming, GeometricFlux.jl is an exciting prospect. If you are intrigued by functional programming paradigms and want to retain some of the speed advantages from just-in-time compilation (like Julia) but would prefer to stick with Python, the JAX-based Jraph is an attractive option. Finally, if you want a fast, capable library at a relatively established and mature state of development, it’s going to be hard to go wrong with PyTorch Geometric.
Have any questions?
Contact Exxact Today








{kind=link}