Artificial Intelligence
Getting Started with NLP using the PyTorch Framework
March 19, 2019
8 min read



In this article we will be looking into the classes that PyTorch provides for helping with Natural Language Processing (NLP).
There are 6 classes in PyTorch that can be used for NLP related tasks using recurrent layers:
Understanding these classes, their parameters, their inputs and their outputs are key to getting started with building your own neural networks for Natural Language Processing (NLP) in Pytorch.
If you have started your NLP journey, chances are that you have encountered a similar type of diagram (if not, we recommend that you check out this excellent and often-cited article by Chris Olah — Understanding LSTM Networks):
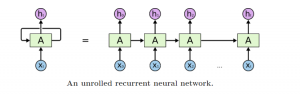
Source — http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Such unrolled diagrams are used by teachers to provide students with a simple-to-grasp explanation of the recurrent structure of such neural networks. Going from these pretty, unrolled diagrams and intuitive explanations to the Pytorch API can prove to be challenging.

Source —https://pytorch.org/docs/stable/nn.html#recurrent-layers

Hence, in this article, we aim to bridge that gap by explaining the parameters, inputs and the outputs of the relevant classes in PyTorch in a clear and descriptive manner.
Pytorch basically has 2 levels of classes for building recurrent networks:
All the classes in the same level share the same API. Hence, understanding the parameters, inputs and outputs of any one of the classes in both the above levels is enough.
To make explanations simple, we will use the simplest classes — torch.nn.RNN and torch.nn.RNNCell
We will use the following diagram to explain the API —
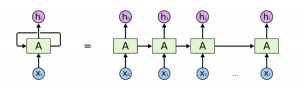
Source — http://colah.github.io/posts/2015-08-Understanding-LSTMs/
This represents the dimensions of vector x[i] (i.e, any of the vectors from x[0] to x[t] in the above diagram). Note that it is easy to confuse this with the sequence length, which is the total number of cells that we get after unrolling the RNN as above.
This represents the dimension of vector h[i] (i.e, any of the vectors from h[0] to h[t] in the above diagram). Together, hidden_size and input_size are necessary and sufficient in determining the shape of the weight matrices of the network.
This parameter is used to build deep RNNs like these:
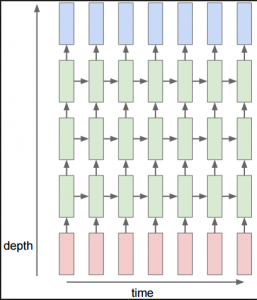
Here red cells represent the inputs, green blocks represent the RNN cells and blue blocks represent the output
So for the above diagram, we would set the num_layers parameter to 3.
This is self-explanatory.
In the Deep Learning community, some people find that removing/using bias does not affect the model’s performance. Hence, this boolean parameter.
This parameter is used to control the dropout regularisation method in the RNN architecture.
Creating a bidirectional RNN is as simple as setting this parameter to True!
So, to make an RNN in PyTorch, we need to pass 2 mandatory parameters to the class — input_size and hidden_size.
Once we have created an object, we can “call” the object with the relevant inputs and it returns outputs.
We need to pass 2 inputs to the object — input and h_0 :
Outputs:
In a similar manner, the object returns 2 outputs to us — output and h_n :
As mentioned before, both torch.nn.GRU and torch.nn.LSTM have the same API, i.e, they accept the same set of parameters and accept inputs in the same format and return out in the same format too.
Since this represents only a single cell of the RNN, it accepts only 4 parameters, all of which have the same meaning as they did in torch.nn.RNN .
Again, since this is just a single cell of an RNN, the input and output dimensions are much simpler —
This was all about getting started with the PyTorch framework for Natural Language Processing (NLP). If you are looking for ideas on what is possible and what you can build, check out — Deep Learning for Natural Language Processing using RNNs and CNNs.

In this article we will be looking into the classes that PyTorch provides for helping with Natural Language Processing (NLP).
There are 6 classes in PyTorch that can be used for NLP related tasks using recurrent layers:
Understanding these classes, their parameters, their inputs and their outputs are key to getting started with building your own neural networks for Natural Language Processing (NLP) in Pytorch.
If you have started your NLP journey, chances are that you have encountered a similar type of diagram (if not, we recommend that you check out this excellent and often-cited article by Chris Olah — Understanding LSTM Networks):
Source — http://colah.github.io/posts/2015-08-Understanding-LSTMs/
Such unrolled diagrams are used by teachers to provide students with a simple-to-grasp explanation of the recurrent structure of such neural networks. Going from these pretty, unrolled diagrams and intuitive explanations to the Pytorch API can prove to be challenging.
Source —https://pytorch.org/docs/stable/nn.html#recurrent-layers
Hence, in this article, we aim to bridge that gap by explaining the parameters, inputs and the outputs of the relevant classes in PyTorch in a clear and descriptive manner.
Pytorch basically has 2 levels of classes for building recurrent networks:
All the classes in the same level share the same API. Hence, understanding the parameters, inputs and outputs of any one of the classes in both the above levels is enough.
To make explanations simple, we will use the simplest classes — torch.nn.RNN and torch.nn.RNNCell
We will use the following diagram to explain the API —
Source — http://colah.github.io/posts/2015-08-Understanding-LSTMs/
This represents the dimensions of vector x[i] (i.e, any of the vectors from x[0] to x[t] in the above diagram). Note that it is easy to confuse this with the sequence length, which is the total number of cells that we get after unrolling the RNN as above.
This represents the dimension of vector h[i] (i.e, any of the vectors from h[0] to h[t] in the above diagram). Together, hidden_size and input_size are necessary and sufficient in determining the shape of the weight matrices of the network.
This parameter is used to build deep RNNs like these:
Here red cells represent the inputs, green blocks represent the RNN cells and blue blocks represent the output
So for the above diagram, we would set the num_layers parameter to 3.
This is self-explanatory.
In the Deep Learning community, some people find that removing/using bias does not affect the model’s performance. Hence, this boolean parameter.
This parameter is used to control the dropout regularisation method in the RNN architecture.
Creating a bidirectional RNN is as simple as setting this parameter to True!
So, to make an RNN in PyTorch, we need to pass 2 mandatory parameters to the class — input_size and hidden_size.
Once we have created an object, we can “call” the object with the relevant inputs and it returns outputs.
We need to pass 2 inputs to the object — input and h_0 :
Outputs:
In a similar manner, the object returns 2 outputs to us — output and h_n :
As mentioned before, both torch.nn.GRU and torch.nn.LSTM have the same API, i.e, they accept the same set of parameters and accept inputs in the same format and return out in the same format too.
Since this represents only a single cell of the RNN, it accepts only 4 parameters, all of which have the same meaning as they did in torch.nn.RNN .
Again, since this is just a single cell of an RNN, the input and output dimensions are much simpler —
This was all about getting started with the PyTorch framework for Natural Language Processing (NLP). If you are looking for ideas on what is possible and what you can build, check out — Deep Learning for Natural Language Processing using RNNs and CNNs.
