Artificial Intelligence
A Tutorial Introduction to Privacy-Centric Deep Learning in PyTorch
April 8, 2019
15 min read


Secure multi-party computation and homomorphic encryption add computational overhead, but the results are well worth it! Data privacy and model parameter security are mutually protected with clever encryption schemes.
As machine learning continues to impact our society in massive ways it's often the models that make the headlines, but ask any data scientist or machine learning engineer about what they spend the majority of their time on and the answer is likely to be the data.
Sourcing, labeling, augmenting, and otherwise rendering data suitable for machine and deep learning models is a critical part of a machine learning practitioner's skillset and underlies the knack for getting products to "just work" (at least until the automation wave catches up to the automaters with advances like Google's AutoML).
Indeed, big models are not worth their millions of parameters without large training datasets to match. A somewhat famous conceptual figure that Andrew Ng likes to use in his lectures illustrates the relationship between model performance, model size, and data availability.
In arbitrary units, the figure looks something like:
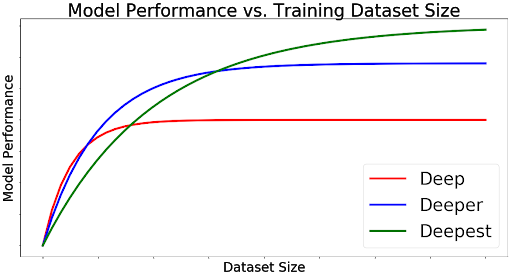
Where large models training on small datasets typically underperform appropriately diminutive networks, and vice-versa.
The availability of large, high-quality datasets is a necessary requisite to take advantage of state-of-the-art models and computational capabilities.
This has led some to call data "the new gold" or "the new oil" in relation to its importance to the modern economy. In 2013, around the time the data floodgates first began to open, some estimated that the world's recorded data had increased by 10 times in just two years. Exact numbers are hard to pin down, but while we can't necessarily expect a 1,000% biennial increase in data to continue indefinitely, there's no doubt that the number of high-quality training datasets is higher now than ever before.
But this data deluge comes with some unintended negative consequences, and as the field matures the way data ownership and privacy is practiced and regulated is bound to adapt.

While people have for the most part been surprisingly OK with openly sharing their data for very little in return, growing awareness and an expanding list of data breaches and blatant misconduct is starting to change that at both the public and regulatory levels.
Big data giant Facebook has had a rough few years of endless scandals, while Google was recently fined for violating the new European data protection laws. People and organizations are increasingly aware of the way data and machine intelligence impact every aspect of our lives and ready to take privacy and data security more seriously.
Additionally, the main bottleneck in modern machine learning pipelines is more often communication bandwidth than computational power.
It's not realistic for a hospital to upload every computed tomography scan to a centralized server for real-time model updates, for example, and there are many other use-cases where it is preferable for learning to occur on-site or in a distributed fashion.
To revisit the example above, it may not be realistic for the hospital to upload many terabytes of sensitive medical data daily for centralized training due to both privacy and bandwidth considerations. It may still be beneficial to share the training experience of the model, however, and so the updated parameters (or their gradients) can be accumulated across different sites to improve the performance of all instances of the model. This is called federated learning.
Federated learning is widely used in ML pipelines, and it can also be used for distributed learning on a big dataset.
But when dealing with private and privileged data, how can we ensure its security? We could just blindly trust all parties involved and this may have been generally acceptable in the past, but we can also run the data through a sharing cipher and employ what's called Secure Multi-party Computation (SMPC)
Secure Multi-Party Computation (SMPC) is any protocol for processing data that doesn't depend on revealing the data to all parties.
This can be as simple as performing local training on local (unencrypted) data, then encrypting the gradients to upload.
Another method is to use a homomorphic encryption (aka HE) scheme, where encrypted data still supports mathematical operations such as addition and multiplication. Using HE the aforementioned encrypted gradients can all be added together before being transferred to whoever owns the model and the private key for decrypting the combined gradients.
Alternatively, with the right HE scheme an encrypted model can be trained on encrypted data, producing encrypted predictions that are only useful once decrypted. This method has the important consequence that the security of valuable models can be maintained at the same time.
Let's build our understanding with some code.
We'll start out by looking at a simple method for SMPC with only Python's numpy as a dependency.
Then we'll look at teaching a small network the exclusive or function, a classic and infamous example of a non-linear function, using an open source cryptographic deep learning library called PySyft.
In the example below we'll see how SMPC can split data into shares while preserving the ability to add encrypted variables to other encrypted variables and multiply encrypted variables with plaintext values.
import numpy as np
# demonstrate secure multiparty computation
Q = 501337
def encrypt(x):
share_a = np.random.randint(0,Q)
share_b = np.random.randint(0,Q)
share_c = (x - share_a - share_b) % Q
return (share_a, share_b, share_c)
def decrypt(*shares):
return sum(shares) % Q
def add(x, y):
z = []
assert (len(x) == len(y)), "each variable must consist of the same number of shares!"
for ii in range(len(x)):
z.append((x[ii] + y[ii]) % Q)
return z
def product(x, w):
# w is a plaintext value,
z = []
for ii in range(len(x)):
z.append((x[ii] * w) % Q)
return z
# encrypt variables
var1 = encrypt(2)
var2 = encrypt(5)
# get sum
my_sum = add(var1,var2)
# print results
print(my_sum)
print(decrypt(*my_sum))
print(decrypt(*my_sum[0:2]))
As we can see above, after taking the sum of our encrypted variables we get a result that looks like three random integers.
Those integers are encrypted shares that we can translate into a plaintext result using decrypt(). The important thing to notice above is that if we try to "decrypt" the result with access to only two shares, we get nonsense. No party with access to incomplete shares can decipher the meaning of the data.
The example above supports addition of encrypted data and multiplication with plaintext operands. Deep learning neural nets are mainly built of addition, multiplication, and activation functions, and we've just shown that the first two can be accomplished relatively easily without relinquishing control of the underlying data.
This is enough for simple statistical learning models like linear regression, but to take advantage of the ability of neural networks to fit arbitrary data functions according to the universal approximation theorem, we need to introduce non-linearities. That is a main area of development for for privacy-centric deep learning libraries like PySyft, using clever tricks like Taylor expansion series to approximate common activation functions.
It's also possible to reduce a non-linear problem to a linear one with a complex random transformation, an approach known as reservoir computing. That's what we'll do in the next example.
To run this part of the tutorial we will explore using PyTorch, and more specifically PySyft. But First, you need to understand what system/resource requirements you'll need to run the following demo.
IMPORTANT NOTE: We HIGHLY recommend using Docker for the following experiment due to the large number of DL/ML/Math packages that are needed for this exercise. PySyft is highly experimental, and these scripts are stable in PyTorch v0.3.1, we just want to be up front about that. Please use Docker to avoid possible dependency issues.
sudo docker run -it -p 8888:8888 -v ~/demo:/demo2 continuumio/anaconda bash
NOTE: you can always copy and save the source code below in the 'source code' section instead of downloading the zip file.
navigate to the folder where 'bash encrypted_reservoir_pysyft_demo.sh' is located for this example just enter the following:
cd demo2
Run the bash file
bash encrypted_reservoir_pysyft_demo.sh
NOTE: Running the bash file may take several minutes, creates the entire training environment, downloads all dependencies, and installs all necessary packages, furthermore it takes the source code of the script (seen further below) and executes the training script.
If you want to run the script again, you'll need to enter the PySyft conda enviroment by using the following command:
conda activate pysyft_demo
Now run the demo (again) by entering:
python encrypted_reservoir_demo.py
You should see some outputs like the following:
Encrypting variables 2 and 5 as var1 and var2
Performing encrypted addition...
Multiparty result from add(var1,var2):
[463355, 2676, 35313]
Decrypted result:
7
Decrypted partial result:
466031
Begin training encrypted reservoir...
loss at step 0: 2.000e+00
loss at step 50: 1.059e+00
loss at step 100: 5.590e-01
loss at step 150: 3.290e-01
loss at step 200: 1.800e-01
predictions:
[
0
1
1
0
[syft.core.frameworks.torch.tensor.ByteTensor of size 4x1]
]
targets:
0
1
1
0
[syft.core.frameworks.torch.tensor.FloatTensor of size 4x1]
Now, if you want to experiment more on your own, feel free to modify the source code below.
#!/usr/bin/env bash
# download this script and run by typing 'bash encrypted_reservoir_pysyft_demo.sh' from the command line while in the same directory
# create a new environment with PyTorch 0.3
conda create -n pysyft_demo pytorch=0.3 torchvision matplotlib pip -c pytorch -y
source activate pysyft_demo
# clone PySyft and checkout the required commit
git clone https://github.com/OpenMined/PySyft.git
cd PySyft
git checkout 1f8387a7b22406945482332c8171cb4994a3cfe8
# install requirements, install PySyft, and test
pip install -r requirements.txt
python setup.py install
# run demo learning XOR with an encrypted reservoir
cd ../
# write out the python demo file
echo "import numpy as np
import syft as sy
hook = sy.TorchHook()
import numpy as np
import matplotlib.pyplot as plt
# demonstrate secure multiparty computation
display_figs = False
Q = 501337
def encrypt(x):
share_a = np.random.randint(0,Q)
share_b = np.random.randint(0,Q)
share_c = (x - share_a - share_b) % Q
return (share_a, share_b, share_c)
def decrypt(*shares):
return sum(shares) % Q
def add(x, y):
z = []
assert (len(x) == len(y)), 'each variable must consist of the same number of shares!'
for ii in range(len(x)):
z.append((x[ii] + y[ii]) % Q)
return z
def product(x, w):
# w is a plaintext value,
z = []
for ii in range(len(x)):
z.append((x[ii] * w) % Q)
return z
if __name__ == '__main__':
# encrypt variables
print('Encrypting variables 2 and 5 as var1 and var2')
var1 = encrypt(2)
var2 = encrypt(5)
# get sum
print('Performing encrypted addition...')
my_sum = add(var1,var2)
# print results
print('Multiparty result from add(var1,var2):\n\t\t\t\t',my_sum)
print('Decrypted result:\n\t\t\t\t',decrypt(*my_sum))
print('Decrypted partial result:\n\t\t\t\t',decrypt(*my_sum[0:2]))
bob = sy.VirtualWorker(id='bob')
alice = sy.VirtualWorker(id='alice')
# Create our dataset: an XOR truth table
x = np.array([[0.,0],[0,1],[1,0],[1,1]],'float')
y = np.array([[0],[1],[1],[0]],'float')
# use a reservoir transformation to achieve non-linearity in the model
res_size = 256
my_transform = np.random.randn(2,res_size)
x_2 = np.matmul(x,my_transform)
# apply relu non_linearity
x_2[x_2<0] = 0.
# convert data and targets to Syft tensors
data = sy.FloatTensor(x_2) #[[0,0],[0,1],[1,0],[ 1,1]])
target = sy.FloatTensor(y) #[[0],[1],[1],[0]])
# init model (just a matrix for linear regression)
model = sy.zeros(res_size,1)
# encrypt and share the data, targets, and model
data = data.fix_precision().share(alice, bob)
target = target.fix_precision().share(alice, bob)
model = model.fix_precision().share(alice, bob)
# train the model
learning_rate = 1e-3
J = []
print('\nBegin training encrypted reservoir...')
for i in range(250):
pred = data.mm(model)
grad = pred - target
update = data.transpose(0,1).mm(grad)
model = model - update * learning_rate
loss = grad.get().decode().abs().sum()
J.append(loss)
if(i % 50 == 0): print('loss at step %i: %.3e'%(i,loss))
got_pred = pred.get()
got_target = target.get()
if(display_figs):
# display training results
plt.figure(figsize=(10,6))
plt.plot(J,'g',lw=4)
plt.xlabel('step',fontsize=19)
plt.ylabel('loss',fontsize=19)
plt.title('Learning XOR While Encrypted',fontsize=20)
plt.show()
# print decrypted predictions and targets (decision boundary of predictions at 0.5)
print('predictions: \n',[got_pred.decode()>0.5])
print('targets: \n',got_target.decode())" >> encrypted_reservoir_demo.py
python encrypted_reservoir_demo.py
In this article we learned that it's possible to preserve privacy and security of both models and data.
This is an active and rewarding area of research that is only going to become more important as the role of machine learning and data in our society continues to mature.
Privacy-centric deep and machine learning is a skillset worth adding to your repertoire, set to experience increasing demand as regulatory, consumer, and business pressures all wise up to good data practices.
It also is a worthwhile capability for businesses to develop, as valuable models can be protected.
Finally, homomorphic encryption and secure computation are tools we can use to achieve morally good solutions to the world's sensitive problems.
There remains a significant computational cost to deep learning this way, which is in general at least an order of magnitude slower than conventional models. That's exemplified by the example of training the XOR example above: the training dataset is literally only 12 bits of data including the target values and a far cry from modern deep learning tasks.
This makes accelerating HE algorithms on GPUs and other specialized hardware an active area of development. Homomorphic encryption libraries are in the early stages of being developed to fully leverage modern GPUs, much like the state deep learning libraries were in a few years ago.
This creates an opportunity to get in on the cutting edge and influence the direction of the field for the better. An accelerated encryption library called cuHE already claims speedups of 12 to 50 times on various encrypted tasks over previous implementations.
In the future, it will make sense for GPU manufacturers to cater to demand for good data practices with improved hardware support of cryptographic primitives, much like the tensor cores and decreased precision capabilities developed in response to deep learning demand.
Deep learning friendly libraries such as PySyft (built on PyTorch) and tf-encrypted (built on TensorFlow), or PySEAL (a python port of Microsoft's Simple Encrypted Arithmetic Library) are developing active communities of users and developers.
Homomorphic encryption, secure multi-party computation, and other privacy preserving schemes are sure to become necessary skillsets for the machine learning practitioner of the future, and there's no better time to get involved.
When you're ready to get started, read the introduction to Craig Gentry's thesis on fully homomorphic encryption.
Then when you're ready to learn more, find a GPU and start working through the examples from tf-encrypted and PySyft.
(227361, 106917, 167163) (44123, 289723, 167588) (165513, 231191, 104745) (478016, 430732, 94038) (312810, 257243, 432742) (19638, 239579, 242152) (235418, 28417, 237603) (410735, 485411, 106638) (115624, 38923, 346889) (500014, 163171, 339603) (169683, 396997, 436115) (108180, 449757, 444849) (225167, 471257, 306366) (47789, 254175, 199478) (179954, 40895, 280598) (357183, 274943, 370651) !
Secure multi-party computation and homomorphic encryption add computational overhead, but the results are well worth it! Data privacy and model parameter security are mutually protected with clever encryption schemes.
As machine learning continues to impact our society in massive ways it's often the models that make the headlines, but ask any data scientist or machine learning engineer about what they spend the majority of their time on and the answer is likely to be the data.
Sourcing, labeling, augmenting, and otherwise rendering data suitable for machine and deep learning models is a critical part of a machine learning practitioner's skillset and underlies the knack for getting products to "just work" (at least until the automation wave catches up to the automaters with advances like Google's AutoML).
Indeed, big models are not worth their millions of parameters without large training datasets to match. A somewhat famous conceptual figure that Andrew Ng likes to use in his lectures illustrates the relationship between model performance, model size, and data availability.
In arbitrary units, the figure looks something like:
Where large models training on small datasets typically underperform appropriately diminutive networks, and vice-versa.
The availability of large, high-quality datasets is a necessary requisite to take advantage of state-of-the-art models and computational capabilities.
This has led some to call data "the new gold" or "the new oil" in relation to its importance to the modern economy. In 2013, around the time the data floodgates first began to open, some estimated that the world's recorded data had increased by 10 times in just two years. Exact numbers are hard to pin down, but while we can't necessarily expect a 1,000% biennial increase in data to continue indefinitely, there's no doubt that the number of high-quality training datasets is higher now than ever before.
But this data deluge comes with some unintended negative consequences, and as the field matures the way data ownership and privacy is practiced and regulated is bound to adapt.
While people have for the most part been surprisingly OK with openly sharing their data for very little in return, growing awareness and an expanding list of data breaches and blatant misconduct is starting to change that at both the public and regulatory levels.
Big data giant Facebook has had a rough few years of endless scandals, while Google was recently fined for violating the new European data protection laws. People and organizations are increasingly aware of the way data and machine intelligence impact every aspect of our lives and ready to take privacy and data security more seriously.
Additionally, the main bottleneck in modern machine learning pipelines is more often communication bandwidth than computational power.
It's not realistic for a hospital to upload every computed tomography scan to a centralized server for real-time model updates, for example, and there are many other use-cases where it is preferable for learning to occur on-site or in a distributed fashion.
To revisit the example above, it may not be realistic for the hospital to upload many terabytes of sensitive medical data daily for centralized training due to both privacy and bandwidth considerations. It may still be beneficial to share the training experience of the model, however, and so the updated parameters (or their gradients) can be accumulated across different sites to improve the performance of all instances of the model. This is called federated learning.
Federated learning is widely used in ML pipelines, and it can also be used for distributed learning on a big dataset.
But when dealing with private and privileged data, how can we ensure its security? We could just blindly trust all parties involved and this may have been generally acceptable in the past, but we can also run the data through a sharing cipher and employ what's called Secure Multi-party Computation (SMPC)
Secure Multi-Party Computation (SMPC) is any protocol for processing data that doesn't depend on revealing the data to all parties.
This can be as simple as performing local training on local (unencrypted) data, then encrypting the gradients to upload.
Another method is to use a homomorphic encryption (aka HE) scheme, where encrypted data still supports mathematical operations such as addition and multiplication. Using HE the aforementioned encrypted gradients can all be added together before being transferred to whoever owns the model and the private key for decrypting the combined gradients.
Alternatively, with the right HE scheme an encrypted model can be trained on encrypted data, producing encrypted predictions that are only useful once decrypted. This method has the important consequence that the security of valuable models can be maintained at the same time.
Let's build our understanding with some code.
We'll start out by looking at a simple method for SMPC with only Python's numpy as a dependency.
Then we'll look at teaching a small network the exclusive or function, a classic and infamous example of a non-linear function, using an open source cryptographic deep learning library called PySyft.
In the example below we'll see how SMPC can split data into shares while preserving the ability to add encrypted variables to other encrypted variables and multiply encrypted variables with plaintext values.
import numpy as np
# demonstrate secure multiparty computation
Q = 501337
def encrypt(x):
share_a = np.random.randint(0,Q)
share_b = np.random.randint(0,Q)
share_c = (x - share_a - share_b) % Q
return (share_a, share_b, share_c)
def decrypt(*shares):
return sum(shares) % Q
def add(x, y):
z = []
assert (len(x) == len(y)), "each variable must consist of the same number of shares!"
for ii in range(len(x)):
z.append((x[ii] + y[ii]) % Q)
return z
def product(x, w):
# w is a plaintext value,
z = []
for ii in range(len(x)):
z.append((x[ii] * w) % Q)
return z
# encrypt variables
var1 = encrypt(2)
var2 = encrypt(5)
# get sum
my_sum = add(var1,var2)
# print results
print(my_sum)
print(decrypt(*my_sum))
print(decrypt(*my_sum[0:2]))
As we can see above, after taking the sum of our encrypted variables we get a result that looks like three random integers.
Those integers are encrypted shares that we can translate into a plaintext result using decrypt(). The important thing to notice above is that if we try to "decrypt" the result with access to only two shares, we get nonsense. No party with access to incomplete shares can decipher the meaning of the data.
The example above supports addition of encrypted data and multiplication with plaintext operands. Deep learning neural nets are mainly built of addition, multiplication, and activation functions, and we've just shown that the first two can be accomplished relatively easily without relinquishing control of the underlying data.
This is enough for simple statistical learning models like linear regression, but to take advantage of the ability of neural networks to fit arbitrary data functions according to the universal approximation theorem, we need to introduce non-linearities. That is a main area of development for for privacy-centric deep learning libraries like PySyft, using clever tricks like Taylor expansion series to approximate common activation functions.
It's also possible to reduce a non-linear problem to a linear one with a complex random transformation, an approach known as reservoir computing. That's what we'll do in the next example.
To run this part of the tutorial we will explore using PyTorch, and more specifically PySyft. But First, you need to understand what system/resource requirements you'll need to run the following demo.
IMPORTANT NOTE: We HIGHLY recommend using Docker for the following experiment due to the large number of DL/ML/Math packages that are needed for this exercise. PySyft is highly experimental, and these scripts are stable in PyTorch v0.3.1, we just want to be up front about that. Please use Docker to avoid possible dependency issues.
sudo docker run -it -p 8888:8888 -v ~/demo:/demo2 continuumio/anaconda bash
NOTE: you can always copy and save the source code below in the 'source code' section instead of downloading the zip file.
navigate to the folder where 'bash encrypted_reservoir_pysyft_demo.sh' is located for this example just enter the following:
cd demo2
Run the bash file
bash encrypted_reservoir_pysyft_demo.sh
NOTE: Running the bash file may take several minutes, creates the entire training environment, downloads all dependencies, and installs all necessary packages, furthermore it takes the source code of the script (seen further below) and executes the training script.
If you want to run the script again, you'll need to enter the PySyft conda enviroment by using the following command:
conda activate pysyft_demo
Now run the demo (again) by entering:
python encrypted_reservoir_demo.py
You should see some outputs like the following:
Encrypting variables 2 and 5 as var1 and var2
Performing encrypted addition...
Multiparty result from add(var1,var2):
[463355, 2676, 35313]
Decrypted result:
7
Decrypted partial result:
466031
Begin training encrypted reservoir...
loss at step 0: 2.000e+00
loss at step 50: 1.059e+00
loss at step 100: 5.590e-01
loss at step 150: 3.290e-01
loss at step 200: 1.800e-01
predictions:
[
0
1
1
0
[syft.core.frameworks.torch.tensor.ByteTensor of size 4x1]
]
targets:
0
1
1
0
[syft.core.frameworks.torch.tensor.FloatTensor of size 4x1]
Now, if you want to experiment more on your own, feel free to modify the source code below.
#!/usr/bin/env bash
# download this script and run by typing 'bash encrypted_reservoir_pysyft_demo.sh' from the command line while in the same directory
# create a new environment with PyTorch 0.3
conda create -n pysyft_demo pytorch=0.3 torchvision matplotlib pip -c pytorch -y
source activate pysyft_demo
# clone PySyft and checkout the required commit
git clone https://github.com/OpenMined/PySyft.git
cd PySyft
git checkout 1f8387a7b22406945482332c8171cb4994a3cfe8
# install requirements, install PySyft, and test
pip install -r requirements.txt
python setup.py install
# run demo learning XOR with an encrypted reservoir
cd ../
# write out the python demo file
echo "import numpy as np
import syft as sy
hook = sy.TorchHook()
import numpy as np
import matplotlib.pyplot as plt
# demonstrate secure multiparty computation
display_figs = False
Q = 501337
def encrypt(x):
share_a = np.random.randint(0,Q)
share_b = np.random.randint(0,Q)
share_c = (x - share_a - share_b) % Q
return (share_a, share_b, share_c)
def decrypt(*shares):
return sum(shares) % Q
def add(x, y):
z = []
assert (len(x) == len(y)), 'each variable must consist of the same number of shares!'
for ii in range(len(x)):
z.append((x[ii] + y[ii]) % Q)
return z
def product(x, w):
# w is a plaintext value,
z = []
for ii in range(len(x)):
z.append((x[ii] * w) % Q)
return z
if __name__ == '__main__':
# encrypt variables
print('Encrypting variables 2 and 5 as var1 and var2')
var1 = encrypt(2)
var2 = encrypt(5)
# get sum
print('Performing encrypted addition...')
my_sum = add(var1,var2)
# print results
print('Multiparty result from add(var1,var2):\n\t\t\t\t',my_sum)
print('Decrypted result:\n\t\t\t\t',decrypt(*my_sum))
print('Decrypted partial result:\n\t\t\t\t',decrypt(*my_sum[0:2]))
bob = sy.VirtualWorker(id='bob')
alice = sy.VirtualWorker(id='alice')
# Create our dataset: an XOR truth table
x = np.array([[0.,0],[0,1],[1,0],[1,1]],'float')
y = np.array([[0],[1],[1],[0]],'float')
# use a reservoir transformation to achieve non-linearity in the model
res_size = 256
my_transform = np.random.randn(2,res_size)
x_2 = np.matmul(x,my_transform)
# apply relu non_linearity
x_2[x_2<0] = 0.
# convert data and targets to Syft tensors
data = sy.FloatTensor(x_2) #[[0,0],[0,1],[1,0],[ 1,1]])
target = sy.FloatTensor(y) #[[0],[1],[1],[0]])
# init model (just a matrix for linear regression)
model = sy.zeros(res_size,1)
# encrypt and share the data, targets, and model
data = data.fix_precision().share(alice, bob)
target = target.fix_precision().share(alice, bob)
model = model.fix_precision().share(alice, bob)
# train the model
learning_rate = 1e-3
J = []
print('\nBegin training encrypted reservoir...')
for i in range(250):
pred = data.mm(model)
grad = pred - target
update = data.transpose(0,1).mm(grad)
model = model - update * learning_rate
loss = grad.get().decode().abs().sum()
J.append(loss)
if(i % 50 == 0): print('loss at step %i: %.3e'%(i,loss))
got_pred = pred.get()
got_target = target.get()
if(display_figs):
# display training results
plt.figure(figsize=(10,6))
plt.plot(J,'g',lw=4)
plt.xlabel('step',fontsize=19)
plt.ylabel('loss',fontsize=19)
plt.title('Learning XOR While Encrypted',fontsize=20)
plt.show()
# print decrypted predictions and targets (decision boundary of predictions at 0.5)
print('predictions: \n',[got_pred.decode()>0.5])
print('targets: \n',got_target.decode())" >> encrypted_reservoir_demo.py
python encrypted_reservoir_demo.py
In this article we learned that it's possible to preserve privacy and security of both models and data.
This is an active and rewarding area of research that is only going to become more important as the role of machine learning and data in our society continues to mature.
Privacy-centric deep and machine learning is a skillset worth adding to your repertoire, set to experience increasing demand as regulatory, consumer, and business pressures all wise up to good data practices.
It also is a worthwhile capability for businesses to develop, as valuable models can be protected.
Finally, homomorphic encryption and secure computation are tools we can use to achieve morally good solutions to the world's sensitive problems.
There remains a significant computational cost to deep learning this way, which is in general at least an order of magnitude slower than conventional models. That's exemplified by the example of training the XOR example above: the training dataset is literally only 12 bits of data including the target values and a far cry from modern deep learning tasks.
This makes accelerating HE algorithms on GPUs and other specialized hardware an active area of development. Homomorphic encryption libraries are in the early stages of being developed to fully leverage modern GPUs, much like the state deep learning libraries were in a few years ago.
This creates an opportunity to get in on the cutting edge and influence the direction of the field for the better. An accelerated encryption library called cuHE already claims speedups of 12 to 50 times on various encrypted tasks over previous implementations.
In the future, it will make sense for GPU manufacturers to cater to demand for good data practices with improved hardware support of cryptographic primitives, much like the tensor cores and decreased precision capabilities developed in response to deep learning demand.
Deep learning friendly libraries such as PySyft (built on PyTorch) and tf-encrypted (built on TensorFlow), or PySEAL (a python port of Microsoft's Simple Encrypted Arithmetic Library) are developing active communities of users and developers.
Homomorphic encryption, secure multi-party computation, and other privacy preserving schemes are sure to become necessary skillsets for the machine learning practitioner of the future, and there's no better time to get involved.
When you're ready to get started, read the introduction to Craig Gentry's thesis on fully homomorphic encryption.
Then when you're ready to learn more, find a GPU and start working through the examples from tf-encrypted and PySyft.
(227361, 106917, 167163) (44123, 289723, 167588) (165513, 231191, 104745) (478016, 430732, 94038) (312810, 257243, 432742) (19638, 239579, 242152) (235418, 28417, 237603) (410735, 485411, 106638) (115624, 38923, 346889) (500014, 163171, 339603) (169683, 396997, 436115) (108180, 449757, 444849) (225167, 471257, 306366) (47789, 254175, 199478) (179954, 40895, 280598) (357183, 274943, 370651) !
