Benchmarks
Deep Learning Benchmarks Comparison 2019: RTX 2080 Ti vs. TITAN RTX vs. RTX 6000 vs. RTX 8000 Selecting the Right GPU for your Needs
July 2, 2019
23 min read


Selecting the right GPU for deep learning is not always such a clear cut task. Based on the types of networks you're training, selecting the right GPU is more nuanced than simply looking at price/performance. Here we aim to provide some insights based on real data in the form of deep learning benchmarks for computer vision (img/sec throughput, batch size) and, natural language processing (NLP), where we compare the performance of training transformer models based on model size and batch size.
Overall, the RTX 2080 Ti is an excellent value GPU for deep learning experimentation. However, it should be noted that this GPU may have some limitations on training modern NLP models due to the relatively low GPU Memory per card (11GB). On the plus side, the blower design allows for dense system configurations.
The TITAN RTX is a good all purpose GPU for just about any deep learning task. When used as a pair with the NVLink bridge you have effectively 48 GB of memory to train large models, including big transformer models for NLP. The twin fan design may hamper dense system configurations. As a plus, qualifying EDU discounts are available on TITAN RTX.
Looking at the TITAN RTX and the 2080 Ti, this card you gives you the best of both worlds. The large memory capacity, plus the blower design allows for densely populated system configurations with ample memory capacity to train large models. Furthermore, the raw image throughput performance (img/sec) is on par with the mighty RTX 8000. Like the TITAN RTX, EDU discounts may be available on Quadro cards, so be sure to check!
If you've done any significant amount deep learning on GPUs, you'll be familiar with the dreaded 'RuntimeError: CUDA error: out of memory'. Enter the RTX 8000, perhaps one of the best deep learning GPUs ever created. This card when used in a pair w/NVLink lives 96GB of GPU memory, double that of the RTX 6000 and TITAN RTX. It's blower design allows for dense system configurations. The price does come at a premium, however if you can afford it, go for it.
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 | |
 |  |  |  | |
| Chipset | TU102-300-K1-A1 | TU102-400-A1 | TU102-875 | TU102-875 |
| CUDA Cores | 4352 | 4608 | 4608 | 4608 |
| Memory | 11GB DDR6 | 24GB DDR6 | 24GB DDR6 | 48GB DDR6 |
| NVLink | 2-way | 2-way | 2-way | 2-way |
| Outputs | DisplayPort 1.4 (x3), HDMI 2.0b, USB Type-C | 3 x DisplayPort , 1 x HDMI, 1 x USB Type-C | DisplayPort 1.4 (4) + VirtualLink, USB Type-C | DisplayPort 1.4 (4) + VirtualLink, USB Type-C |
| Power consumption | 250 W | 280 W | 295W | 295W |
| Relative Cost | $ | $$ | $$$ | $$$$ |

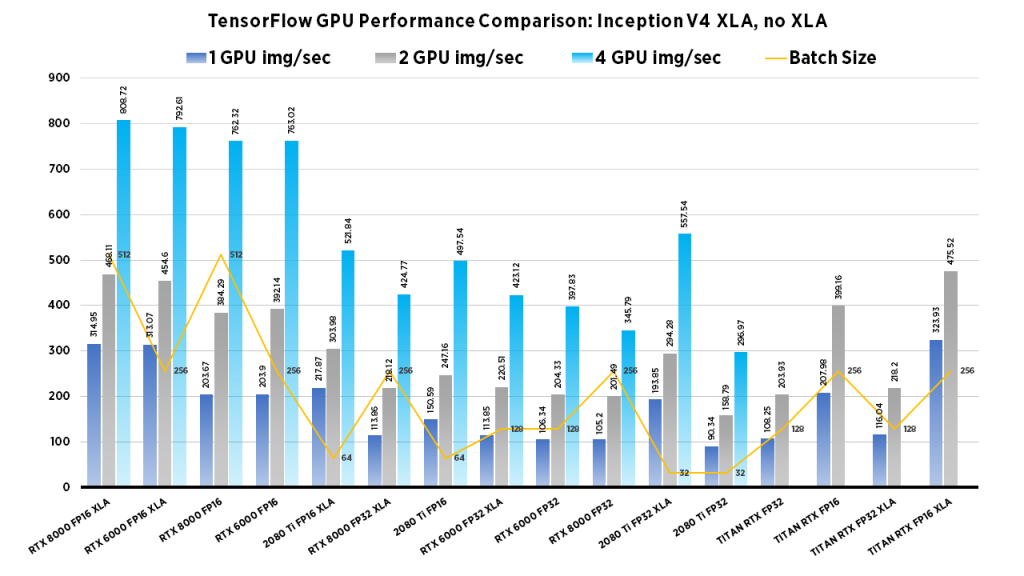
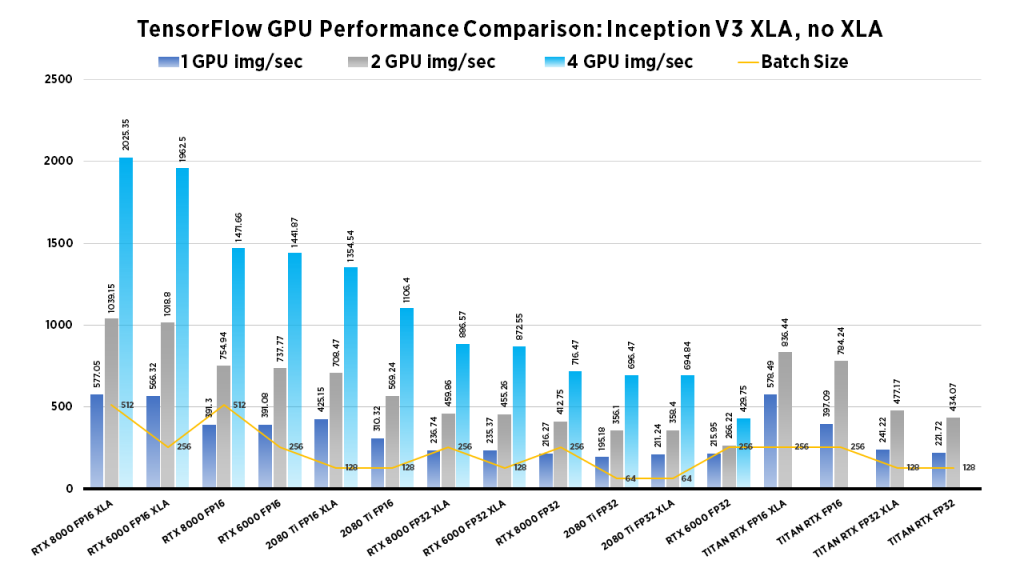
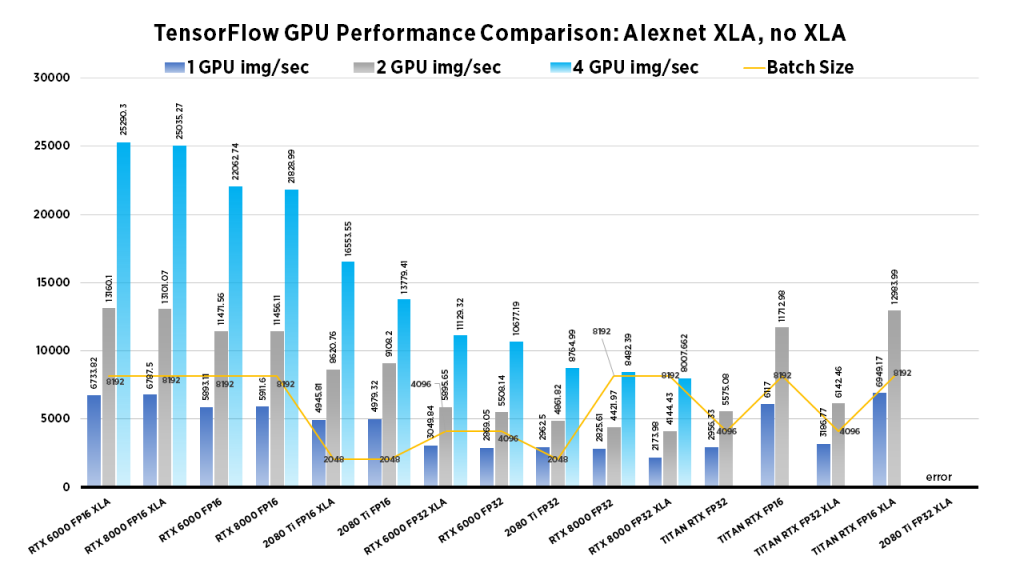
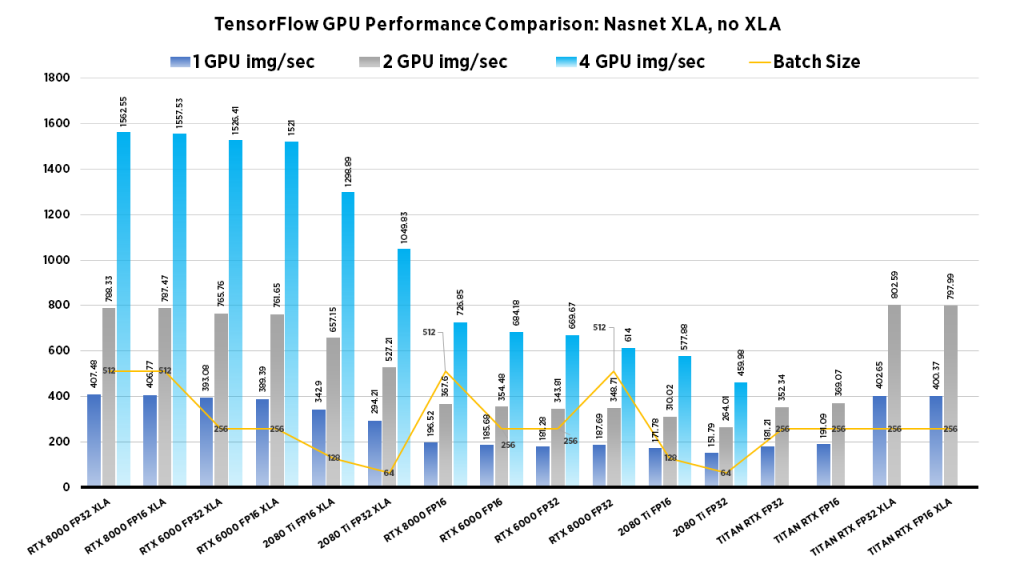
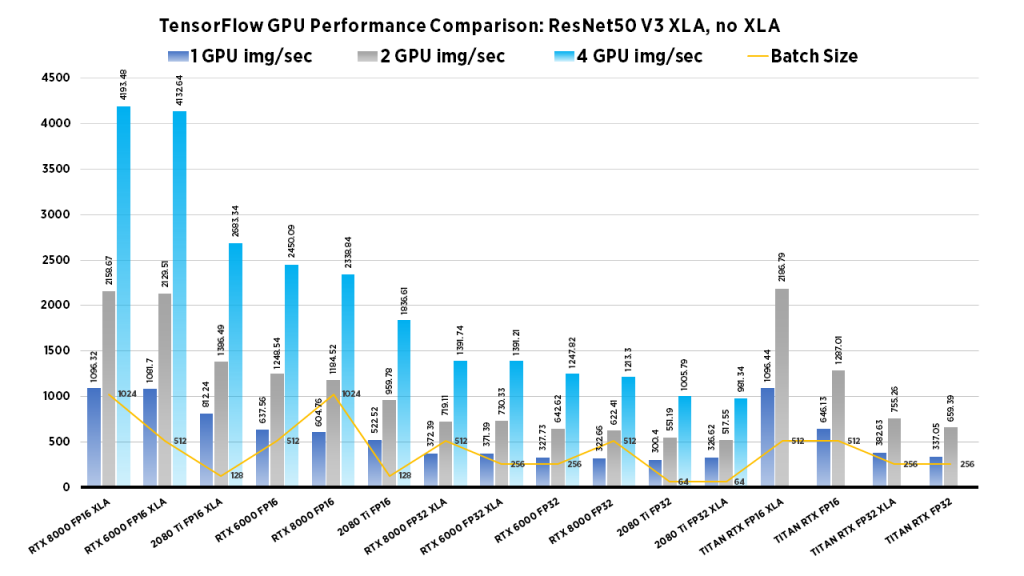
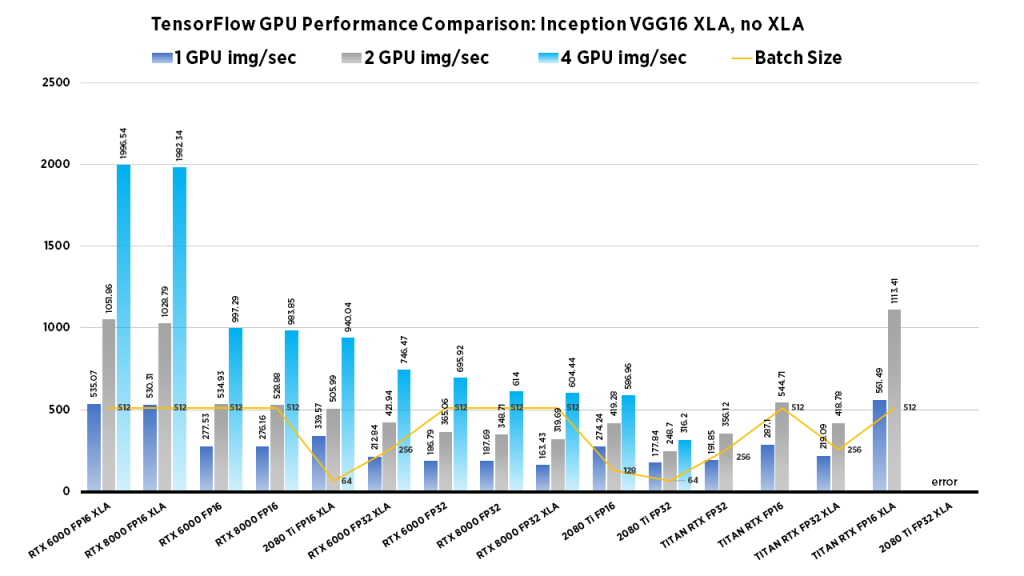
The goal of computer vision is to make computers gain high-level “understanding” of images. To evaluate if a model truly “understands” the image, researchers have developed different evaluation methods to measure performance. We examine Images/second throughput and batch size by running tf_cnn_benchmarks.py from the official TensorFlow github page.
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|
| Due to their smaller GPU memory footprints, high-throughput workloads work well on the RTX 2080 Ti. Specifically, this card is best suited for small-scale model development rather than full-scale training workloads. The blower design allows for workstations to be configured with up to 4 in a single workstation. | With 24 GB Memory, the TITAN RTX Can work with larger batch sizes, or larger models. If you need to train large computer vision models the TITAN RTX can do it. Due to its twin fan design, they cannot be densely packed into workstations without significant modifications to the cooling apparatus. | On the other hand, the RTX 6000, while at a significantly higher cost than the 2080 Ti, has the benefits of both the 2080 Ti's blower design and the TITAN RTX's large memory capacity. Furthermore, the RTX 6000 can be densely populated in a system, whilst boasting large memory capacity for large models. | This GPU boasts the largest memory capacity of any NVIDIA GPU, Its blower design allows for maximum flexibility for system configuration. For this reason the RTX 8000 especially performs well for Computer vision tasks that require extremely large models or use large batch sizes, if you can afford it, go for it. |
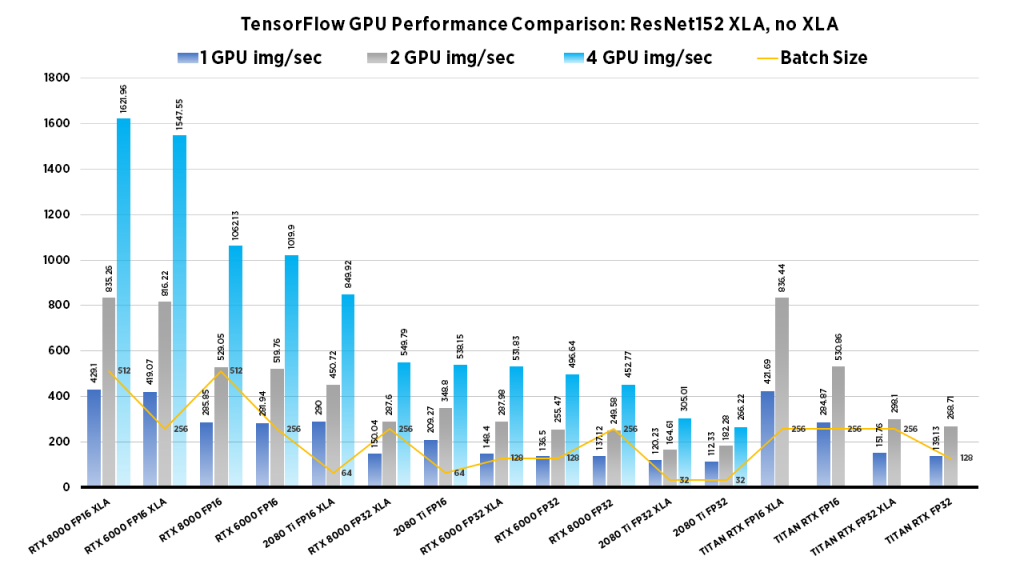
Clearly the RTX 8000 and 6000 models perform well in the 4x GPU configuration. If batch size isn't important, the 2080 Ti system provides a excellent choice at a value price.
NLP tasks include speech recognition, translation, speech-to-text, and Q&A Systems. Incidentally, GPU memory is of great importance, as modern transformer networks such as XLNet and BERT require massive memory to achieve highest accuracy. For this section, we compare training the official Transformer model (BASE and BIG) from the official Tensorflow Github.
Note: For a detailed tutorial on how we trained the transformer models and how we obtained our metrics see our blog post Examining the Transformer Architecture – Part 3: Training a Transformer Network from Scratch in Docker
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 |
| For modern NLP networks such as Transformers, Batch size is very important. Therefore, the RTX 2080 Ti not ideal for modern NLP Tasks. While workstations can be configured with up to 4 GPU's, the smaller memory footprint is unfortunately a hindrance for this application. | At at minimum, a pair of TITAN RTX cards bridged with NVLink can train larger transformer models and therefore work with larger batch sizes. The TITAN RTX Workstation can use 48GB Unified Memory with NVLink. Hence, for a single developer looking to work with large NLP models, a TITAN RTX workstation can be a excellent choice. | The RTX 6000, boasts the similar performance metrics as the TITAN RTX, however the blower design allows dense configurations. Similar to the TITAN RTX, 24GB (48 per pair w/NVLink) of memory therefore allows for working with large batch sizes. | Perhaps the best GPU for NLP, the RTX 8000 with 48GB memory/GPU allows for maximum memory footprint in a single GPU. All the performance benefits of the RTX 6000, but with double the effective GPU memory. These cards are able to be bridged (96GB memory per pair) with NVLink as well. |
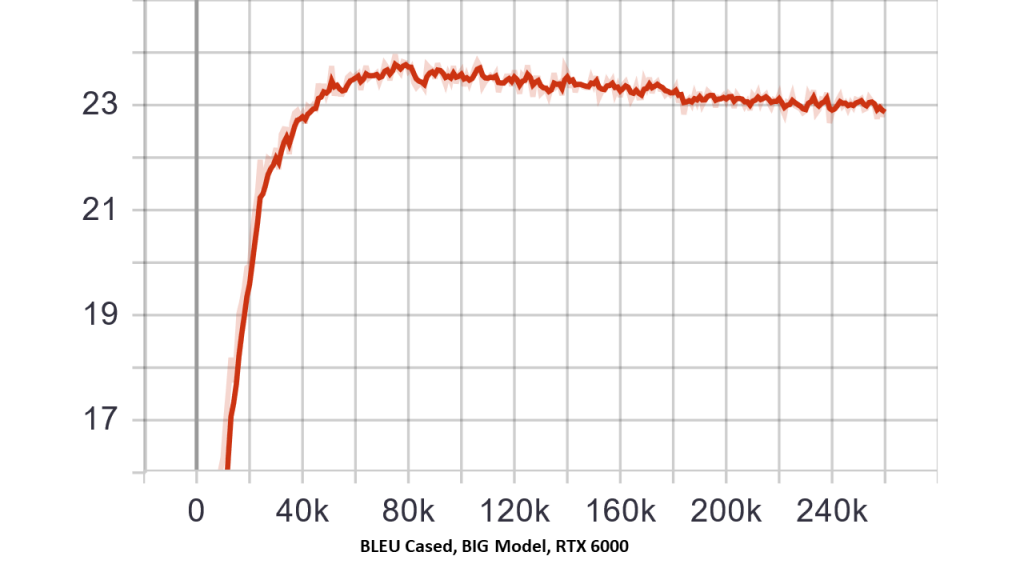
| Transformer BLEU Score trained with RTX 6000 (BIG Model) | Transformer BLEU Score trained with RTX 2080 ti (BASE Model) |
| The Big model trained using the RTX 6000 can obtain a higher bleu score (based on vanilla settings for transformer model). Default settings/batch size were used on 2x RTX 6000 wNVLink system. | Here, the BASE model trained using the RTX 2080 Ti (based on vanilla settings for transformer model) clearly is inferior. Note: BIG model failed training on 2x 2080 Ti System with default batch size. |
 |

For more detailed deep learning benchmarks, and methods used for obtaining data see below for specific GPU statistics.

Selecting the right GPU for deep learning is not always such a clear cut task. Based on the types of networks you're training, selecting the right GPU is more nuanced than simply looking at price/performance. Here we aim to provide some insights based on real data in the form of deep learning benchmarks for computer vision (img/sec throughput, batch size) and, natural language processing (NLP), where we compare the performance of training transformer models based on model size and batch size.
Overall, the RTX 2080 Ti is an excellent value GPU for deep learning experimentation. However, it should be noted that this GPU may have some limitations on training modern NLP models due to the relatively low GPU Memory per card (11GB). On the plus side, the blower design allows for dense system configurations.
The TITAN RTX is a good all purpose GPU for just about any deep learning task. When used as a pair with the NVLink bridge you have effectively 48 GB of memory to train large models, including big transformer models for NLP. The twin fan design may hamper dense system configurations. As a plus, qualifying EDU discounts are available on TITAN RTX.
Looking at the TITAN RTX and the 2080 Ti, this card you gives you the best of both worlds. The large memory capacity, plus the blower design allows for densely populated system configurations with ample memory capacity to train large models. Furthermore, the raw image throughput performance (img/sec) is on par with the mighty RTX 8000. Like the TITAN RTX, EDU discounts may be available on Quadro cards, so be sure to check!
If you've done any significant amount deep learning on GPUs, you'll be familiar with the dreaded 'RuntimeError: CUDA error: out of memory'. Enter the RTX 8000, perhaps one of the best deep learning GPUs ever created. This card when used in a pair w/NVLink lives 96GB of GPU memory, double that of the RTX 6000 and TITAN RTX. It's blower design allows for dense system configurations. The price does come at a premium, however if you can afford it, go for it.
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 | |
| | | | |
| Chipset | TU102-300-K1-A1 | TU102-400-A1 | TU102-875 | TU102-875 |
| CUDA Cores | 4352 | 4608 | 4608 | 4608 |
| Memory | 11GB DDR6 | 24GB DDR6 | 24GB DDR6 | 48GB DDR6 |
| NVLink | 2-way | 2-way | 2-way | 2-way |
| Outputs | DisplayPort 1.4 (x3), HDMI 2.0b, USB Type-C | 3 x DisplayPort , 1 x HDMI, 1 x USB Type-C | DisplayPort 1.4 (4) + VirtualLink, USB Type-C | DisplayPort 1.4 (4) + VirtualLink, USB Type-C |
| Power consumption | 250 W | 280 W | 295W | 295W |
| Relative Cost | $ | $$ | $$$ | $$$$ |
The goal of computer vision is to make computers gain high-level “understanding” of images. To evaluate if a model truly “understands” the image, researchers have developed different evaluation methods to measure performance. We examine Images/second throughput and batch size by running tf_cnn_benchmarks.py from the official TensorFlow github page.
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 |
|---|---|---|---|
| Due to their smaller GPU memory footprints, high-throughput workloads work well on the RTX 2080 Ti. Specifically, this card is best suited for small-scale model development rather than full-scale training workloads. The blower design allows for workstations to be configured with up to 4 in a single workstation. | With 24 GB Memory, the TITAN RTX Can work with larger batch sizes, or larger models. If you need to train large computer vision models the TITAN RTX can do it. Due to its twin fan design, they cannot be densely packed into workstations without significant modifications to the cooling apparatus. | On the other hand, the RTX 6000, while at a significantly higher cost than the 2080 Ti, has the benefits of both the 2080 Ti's blower design and the TITAN RTX's large memory capacity. Furthermore, the RTX 6000 can be densely populated in a system, whilst boasting large memory capacity for large models. | This GPU boasts the largest memory capacity of any NVIDIA GPU, Its blower design allows for maximum flexibility for system configuration. For this reason the RTX 8000 especially performs well for Computer vision tasks that require extremely large models or use large batch sizes, if you can afford it, go for it. |
Clearly the RTX 8000 and 6000 models perform well in the 4x GPU configuration. If batch size isn't important, the 2080 Ti system provides a excellent choice at a value price.
NLP tasks include speech recognition, translation, speech-to-text, and Q&A Systems. Incidentally, GPU memory is of great importance, as modern transformer networks such as XLNet and BERT require massive memory to achieve highest accuracy. For this section, we compare training the official Transformer model (BASE and BIG) from the official Tensorflow Github.
Note: For a detailed tutorial on how we trained the transformer models and how we obtained our metrics see our blog post Examining the Transformer Architecture – Part 3: Training a Transformer Network from Scratch in Docker
| RTX 2080 Ti | TITAN RTX | RTX 6000 | RTX 8000 |
| For modern NLP networks such as Transformers, Batch size is very important. Therefore, the RTX 2080 Ti not ideal for modern NLP Tasks. While workstations can be configured with up to 4 GPU's, the smaller memory footprint is unfortunately a hindrance for this application. | At at minimum, a pair of TITAN RTX cards bridged with NVLink can train larger transformer models and therefore work with larger batch sizes. The TITAN RTX Workstation can use 48GB Unified Memory with NVLink. Hence, for a single developer looking to work with large NLP models, a TITAN RTX workstation can be a excellent choice. | The RTX 6000, boasts the similar performance metrics as the TITAN RTX, however the blower design allows dense configurations. Similar to the TITAN RTX, 24GB (48 per pair w/NVLink) of memory therefore allows for working with large batch sizes. | Perhaps the best GPU for NLP, the RTX 8000 with 48GB memory/GPU allows for maximum memory footprint in a single GPU. All the performance benefits of the RTX 6000, but with double the effective GPU memory. These cards are able to be bridged (96GB memory per pair) with NVLink as well. |
| Transformer BLEU Score trained with RTX 6000 (BIG Model) | Transformer BLEU Score trained with RTX 2080 ti (BASE Model) |
| The Big model trained using the RTX 6000 can obtain a higher bleu score (based on vanilla settings for transformer model). Default settings/batch size were used on 2x RTX 6000 wNVLink system. | Here, the BASE model trained using the RTX 2080 Ti (based on vanilla settings for transformer model) clearly is inferior. Note: BIG model failed training on 2x 2080 Ti System with default batch size. |
|
For more detailed deep learning benchmarks, and methods used for obtaining data see below for specific GPU statistics.
