HPC
Networking Considerations for Multi-Node Computing Deployments
February 21, 2025
7 min read


Multi-node computing deployments require a robust networking infrastructure to ensure efficient node communication, minimize latency, and maximize throughput. Whether you are building an HPC cluster, AI training farm, or large-scale data processing system, careful networking design is essential. Here are the key considerations when networking for a multi-node computing environment.
Choosing the right network bandwidth is crucial to prevent bottlenecks and ensure efficient data transfer:
Understanding these options helps determine the best fit based on workload demands and budget constraints.
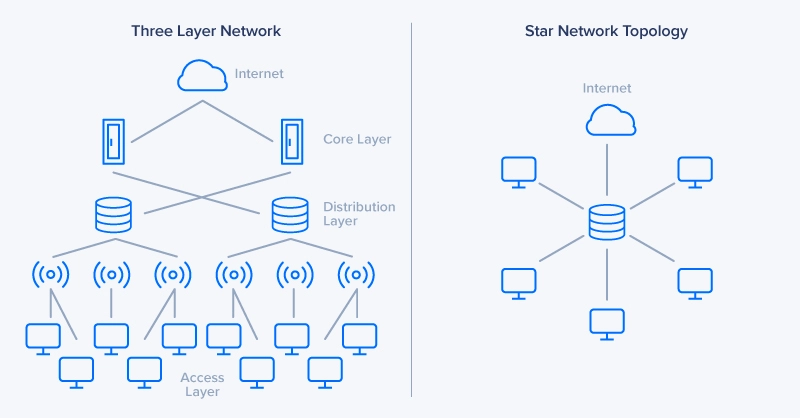
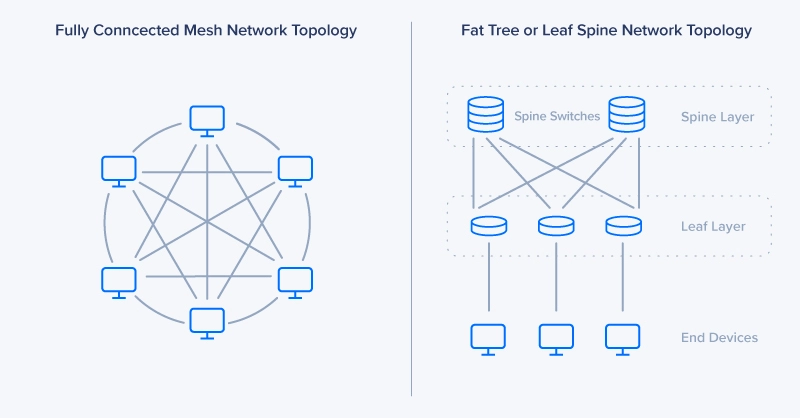
The network topology determines how nodes communicate and how traffic is routed. Selecting the right topology ensures efficient data flow and scalability:
Here's a comparison of the advantages and disadvantages of each topology:
Topology | Pros | Cons |
Star Topology | • Simple to implement and manage | • Single point of failure at central switch |
Fat-Tree Topology | • Excellent scalability | • Complex implementation |
Full-Mesh Topology | • Lowest possible latency | • Very expensive to implement |
Hybrid Topology | • Flexible and customizable | • Complex design process |
Reducing latency is vital for distributed computing performance significantly impacting overall system performance and user experience. High latency can cause delays in data processing, slow down distributed applications, and create bottlenecks in system operations. Furthermore, maintaining a redundancy in the data center also applies to networking. Addressing single failure points and adding resiliency through redundant NICs and switches are essential for when thing go wrong. Understanding and minimizing latency and ensuring consistent performance is crucial for efficiency in:
Performance optimization requires a holistic approach, considering both hardware and software aspects of the network infrastructure. Network congestion, protocol overhead, and physical distance between nodes all contribute to overall latency. Methods to address and minimize latency in multi-node computing environments include:
Implementing robust monitoring and management systems is crucial for maintaining optimal network performance. Here are key tools and strategies:
Regular monitoring and management not only helps maintain network performance but also aids in capacity planning and future infrastructure decisions. Using these tools effectively can significantly reduce downtime and improve overall system reliability.
A well-structured networking infrastructure is the backbone of any successful multi-node computing deployment. By carefully selecting your topology, optimizing for latency, ensuring scalability, securing your network, and implementing proactive monitoring, you can build a resilient and high-performance system. Whether you're planning a new deployment or upgrading existing infrastructure, Exxact's expertise is available to help configure and implement the right networking solution for your specific needs. Investing in a robust networking strategy today ensures seamless communication and future-proofing for tomorrow's computing demands.

With access to the highest performing hardware, at Exxact, we can offer the platform optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Talk to an Engineer TodayMulti-node computing deployments require a robust networking infrastructure to ensure efficient node communication, minimize latency, and maximize throughput. Whether you are building an HPC cluster, AI training farm, or large-scale data processing system, careful networking design is essential. Here are the key considerations when networking for a multi-node computing environment.
Choosing the right network bandwidth is crucial to prevent bottlenecks and ensure efficient data transfer:
Understanding these options helps determine the best fit based on workload demands and budget constraints.
The network topology determines how nodes communicate and how traffic is routed. Selecting the right topology ensures efficient data flow and scalability:
Here's a comparison of the advantages and disadvantages of each topology:
Topology | Pros | Cons |
Star Topology | • Simple to implement and manage | • Single point of failure at central switch |
Fat-Tree Topology | • Excellent scalability | • Complex implementation |
Full-Mesh Topology | • Lowest possible latency | • Very expensive to implement |
Hybrid Topology | • Flexible and customizable | • Complex design process |
Reducing latency is vital for distributed computing performance significantly impacting overall system performance and user experience. High latency can cause delays in data processing, slow down distributed applications, and create bottlenecks in system operations. Furthermore, maintaining a redundancy in the data center also applies to networking. Addressing single failure points and adding resiliency through redundant NICs and switches are essential for when thing go wrong. Understanding and minimizing latency and ensuring consistent performance is crucial for efficiency in:
Performance optimization requires a holistic approach, considering both hardware and software aspects of the network infrastructure. Network congestion, protocol overhead, and physical distance between nodes all contribute to overall latency. Methods to address and minimize latency in multi-node computing environments include:
Implementing robust monitoring and management systems is crucial for maintaining optimal network performance. Here are key tools and strategies:
Regular monitoring and management not only helps maintain network performance but also aids in capacity planning and future infrastructure decisions. Using these tools effectively can significantly reduce downtime and improve overall system reliability.
A well-structured networking infrastructure is the backbone of any successful multi-node computing deployment. By carefully selecting your topology, optimizing for latency, ensuring scalability, securing your network, and implementing proactive monitoring, you can build a resilient and high-performance system. Whether you're planning a new deployment or upgrading existing infrastructure, Exxact's expertise is available to help configure and implement the right networking solution for your specific needs. Investing in a robust networking strategy today ensures seamless communication and future-proofing for tomorrow's computing demands.
With access to the highest performing hardware, at Exxact, we can offer the platform optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Talk to an Engineer Today