Artificial Intelligence
How LLMs Reach 1 Million Token Context Windows - Context Parallelism & Ring Attention
January 22, 2026
8 min read


Context windows have exploded from 4k tokens to 10 million in just a few years. Meta's Llama 4 Scout supports 10M tokens—78x more than Llama 3's 128k. Google's Gemini 3 Pro handles 1M tokens, while Claude 4 offers 1M in beta.
This enables processing entire codebases, hundreds of research papers, or multi-day conversation histories in a single pass. But there's a problem: context length has outpaced hardware capacity.
Training a 405B parameter model requires approximately 6.5TB of memory at 32-bit precision. Add gradients, optimizer states, and activations—which scale quadratically with context length—and even a single NVIDIA HGX B300 with 2.3TB of HBM3e per system falls short.
The math:
This forces multi-node distribution across dozens or hundreds of NVIDIA Blackwell GPUs, which is why NVIDIA NVLink (at 1.8TB/s) and InfiniBand are essential networking technologies within the data center. The challenge isn't just splitting the workload—it's the communication bottlenecks when we split the workload among the GPUs.
When a model or dataset exceeds single-GPU capacity, parallelism strategies distribute the workload. Each approach trades communication overhead for memory relief.
The Limitation: When models are large, and context windows extend to millions of tokens, even tensor parallelism falls short. Attention's quadratic memory scaling means activations dominate memory usage. A 128k token context requires 16x more activation memory than an 8k context

Training AI models on massive datasets can be accelerated exponentially with purpose-built AI systems. NVIDIA HGX isn't just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA HGX B300 or NVIDIA HGX B200.
Get a Quote TodayBoth sequence and context parallelism address memory constraints by splitting sequences across devices, but they differ in scope and application.
Sequence Parallelism: Works alongside tensor parallelism to split non-matrix-multiplication operations (layer normalization, dropout) across the sequence dimension. Each device handles a portion of activations for operations that tensor parallelism doesn't cover. Combined with tensor parallelism, this extends sequence length capacity but still faces limits at 128k+ tokens due to attention's quadratic memory scaling.
Context Parallelism: Splits the entire sequence across all modules, not just non-matmul operations. Every operation—including attention—processes a partitioned sequence. This enables training with million-token contexts by distributing the massive activation memory footprint.
The Attention Challenge: Most model operations process tokens independently, making parallelization straightforward. Attention is different—every token must "attend" to every other token in the sequence. When the sequence is split across GPUs, how does GPU 1's tokens attend to GPU 2's tokens without stalling the entire computation?
This is where Ring Attention enables multi-node, multi-GPU LLM training and inferencing across a huge data center
Ring Attention solves the cross-device attention problem by organizing GPUs in a ring topology. Each GPU:
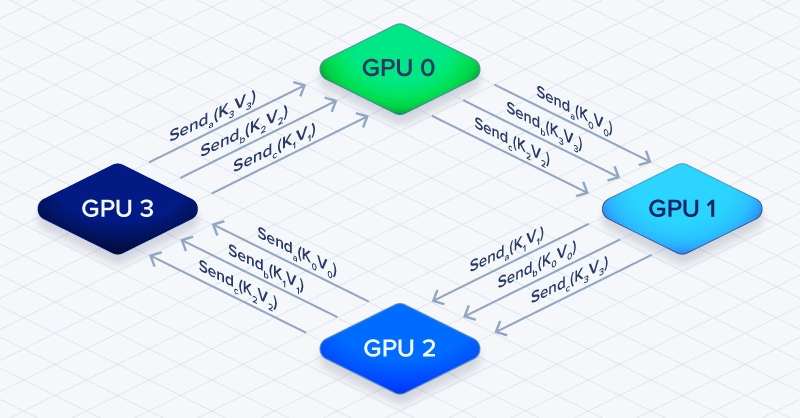
Computation and communication overlap. While GPU 1 computes attention using its current K/V chunks, it simultaneously receives the next chunks from GPU 0. This hides communication latency behind compute, avoiding the stall that would occur if GPUs waited for all data before computing.
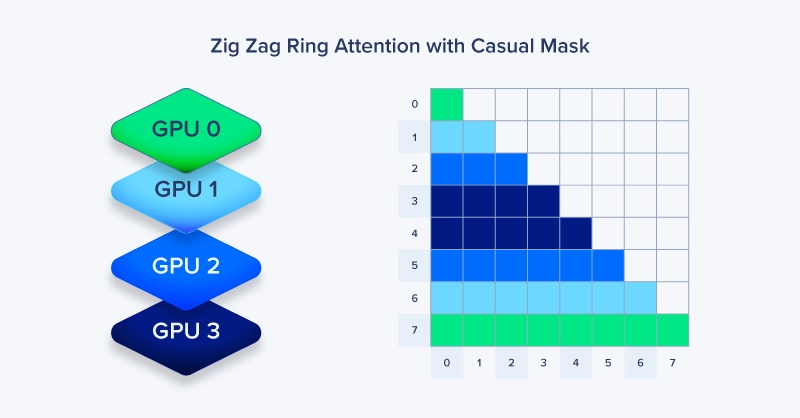
In autoregressive models like GPT, tokens only attend to previous tokens—not future ones, causing a load balancing challenge, leaving some GPUs idle. Zig-Zag Ring Attention addresses this imbalance by distributing sequence chunks in an interleaved pattern rather than sequential blocks. GPU 0 processes tokens [0, 4, 8...], GPU 1 handles [1, 5, 9...], and so on. This ensures every GPU receives a balanced mix of early and late tokens, equalizing compute load during causal attention and preventing idle GPUs in the ring.
This pattern maintains the ring communication structure while achieving near-perfect GPU utilization even with causal masking. The trade-off: slightly more complex indexing logic, but the performance gains at scale are substantial.
Context parallelism splits input sequences across multiple GPUs to overcome memory constraints during training. Unlike tensor or data parallelism, it partitions the entire sequence dimension across all model modules, enabling training with million-token contexts that exceed single-GPU memory capacity.
Ring Attention organizes GPUs in a ring topology where each device passes key-value pairs to the next while computing attention on available data. This overlaps communication with computation, allowing all-to-all attention calculations without stalling GPUs while waiting for complete sequence data.
Sequence parallelism splits non-matrix-multiplication operations (like layer normalization) across the sequence dimension and works alongside tensor parallelism. Context parallelism splits the entire sequence across all modules, including attention, making it necessary for contexts exceeding 128k tokens, where activation memory scales quadratically.
Zig-Zag Ring Attention uses interleaved sequence splitting instead of sequential assignment, balancing GPU utilization during causal masking. Standard Ring Attention can create idle compute where later GPUs wait for earlier chunks, while Zig-Zag distributes early and late tokens evenly across all devices.
For training with a 1M token, choose a multi-node GPU cluster with GPUs featuring HBM memory coupled with high-speed interconnects like NVIDIA NVLink (1.8TB/s) or InfiniBand. For a 405B parameter model, 4x NVIDIA HGX B300 servers in a rack deployment is a great starting point for, from scratch, training and inferencing on 32-bit precision.
Context parallelism trades communication overhead for memory relief—but that trade only works if your hardware can keep pace. Network bandwidth is the critical bottleneck: Ring Attention requires continuous key-value pair exchanges between GPUs, and if transfer time exceeds compute time, devices return to waiting instead of computing.
Essential Resources:
High-speed interconnects between systems with NVIDIA NVLink (1.8TB/s) and InfiniBand are essential in multi-rack deployments. Your interconnect bandwidth must match your GPU compute throughput, or context parallelism effectiveness collapses.
If you are looking to work together on designing your next multi-node rack, Exxact RackEXXpress offers a turnkey option with configurable GPU compute, storage, and management from start to finish. Our team will assess your budget deployment facility and many more factors that will get you on the ground running.

Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote TodayContext windows have exploded from 4k tokens to 10 million in just a few years. Meta's Llama 4 Scout supports 10M tokens—78x more than Llama 3's 128k. Google's Gemini 3 Pro handles 1M tokens, while Claude 4 offers 1M in beta.
This enables processing entire codebases, hundreds of research papers, or multi-day conversation histories in a single pass. But there's a problem: context length has outpaced hardware capacity.
Training a 405B parameter model requires approximately 6.5TB of memory at 32-bit precision. Add gradients, optimizer states, and activations—which scale quadratically with context length—and even a single NVIDIA HGX B300 with 2.3TB of HBM3e per system falls short.
The math:
This forces multi-node distribution across dozens or hundreds of NVIDIA Blackwell GPUs, which is why NVIDIA NVLink (at 1.8TB/s) and InfiniBand are essential networking technologies within the data center. The challenge isn't just splitting the workload—it's the communication bottlenecks when we split the workload among the GPUs.
When a model or dataset exceeds single-GPU capacity, parallelism strategies distribute the workload. Each approach trades communication overhead for memory relief.
The Limitation: When models are large, and context windows extend to millions of tokens, even tensor parallelism falls short. Attention's quadratic memory scaling means activations dominate memory usage. A 128k token context requires 16x more activation memory than an 8k context
Training AI models on massive datasets can be accelerated exponentially with purpose-built AI systems. NVIDIA HGX isn't just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA HGX B300 or NVIDIA HGX B200.
Get a Quote TodayBoth sequence and context parallelism address memory constraints by splitting sequences across devices, but they differ in scope and application.
Sequence Parallelism: Works alongside tensor parallelism to split non-matrix-multiplication operations (layer normalization, dropout) across the sequence dimension. Each device handles a portion of activations for operations that tensor parallelism doesn't cover. Combined with tensor parallelism, this extends sequence length capacity but still faces limits at 128k+ tokens due to attention's quadratic memory scaling.
Context Parallelism: Splits the entire sequence across all modules, not just non-matmul operations. Every operation—including attention—processes a partitioned sequence. This enables training with million-token contexts by distributing the massive activation memory footprint.
The Attention Challenge: Most model operations process tokens independently, making parallelization straightforward. Attention is different—every token must "attend" to every other token in the sequence. When the sequence is split across GPUs, how does GPU 1's tokens attend to GPU 2's tokens without stalling the entire computation?
This is where Ring Attention enables multi-node, multi-GPU LLM training and inferencing across a huge data center
Ring Attention solves the cross-device attention problem by organizing GPUs in a ring topology. Each GPU:
Computation and communication overlap. While GPU 1 computes attention using its current K/V chunks, it simultaneously receives the next chunks from GPU 0. This hides communication latency behind compute, avoiding the stall that would occur if GPUs waited for all data before computing.
In autoregressive models like GPT, tokens only attend to previous tokens—not future ones, causing a load balancing challenge, leaving some GPUs idle. Zig-Zag Ring Attention addresses this imbalance by distributing sequence chunks in an interleaved pattern rather than sequential blocks. GPU 0 processes tokens [0, 4, 8...], GPU 1 handles [1, 5, 9...], and so on. This ensures every GPU receives a balanced mix of early and late tokens, equalizing compute load during causal attention and preventing idle GPUs in the ring.
This pattern maintains the ring communication structure while achieving near-perfect GPU utilization even with causal masking. The trade-off: slightly more complex indexing logic, but the performance gains at scale are substantial.
Context parallelism splits input sequences across multiple GPUs to overcome memory constraints during training. Unlike tensor or data parallelism, it partitions the entire sequence dimension across all model modules, enabling training with million-token contexts that exceed single-GPU memory capacity.
Ring Attention organizes GPUs in a ring topology where each device passes key-value pairs to the next while computing attention on available data. This overlaps communication with computation, allowing all-to-all attention calculations without stalling GPUs while waiting for complete sequence data.
Sequence parallelism splits non-matrix-multiplication operations (like layer normalization) across the sequence dimension and works alongside tensor parallelism. Context parallelism splits the entire sequence across all modules, including attention, making it necessary for contexts exceeding 128k tokens, where activation memory scales quadratically.
Zig-Zag Ring Attention uses interleaved sequence splitting instead of sequential assignment, balancing GPU utilization during causal masking. Standard Ring Attention can create idle compute where later GPUs wait for earlier chunks, while Zig-Zag distributes early and late tokens evenly across all devices.
For training with a 1M token, choose a multi-node GPU cluster with GPUs featuring HBM memory coupled with high-speed interconnects like NVIDIA NVLink (1.8TB/s) or InfiniBand. For a 405B parameter model, 4x NVIDIA HGX B300 servers in a rack deployment is a great starting point for, from scratch, training and inferencing on 32-bit precision.
Context parallelism trades communication overhead for memory relief—but that trade only works if your hardware can keep pace. Network bandwidth is the critical bottleneck: Ring Attention requires continuous key-value pair exchanges between GPUs, and if transfer time exceeds compute time, devices return to waiting instead of computing.
Essential Resources:
High-speed interconnects between systems with NVIDIA NVLink (1.8TB/s) and InfiniBand are essential in multi-rack deployments. Your interconnect bandwidth must match your GPU compute throughput, or context parallelism effectiveness collapses.
If you are looking to work together on designing your next multi-node rack, Exxact RackEXXpress offers a turnkey option with configurable GPU compute, storage, and management from start to finish. Our team will assess your budget deployment facility and many more factors that will get you on the ground running.
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote Today