Artificial Intelligence
How Agentic AI Platforms Organize Their Hardware Infrastructure
February 27, 2026
11 min read


Agentic AI pipelines are computational architectures where multiple specialized AI agents collaborate to complete complex tasks. Each agent in the pipeline handles a specific function, such as retrieving data, analyzing it, making decisions, or executing actions in coordination to complete the larger goal.
In a nutshell, on-premises deployment advantages:
This article explores the advantages of on-premises GPU deployment, provides a high-level architectural view, explains orchestration and inter-agent communication, examines performance optimization patterns, evaluates economic considerations, and presents a practical starting strategy.
Agents within an agentic AI pipeline operate as distinct, specialized services, each designed to execute a specific step in a larger workflow.
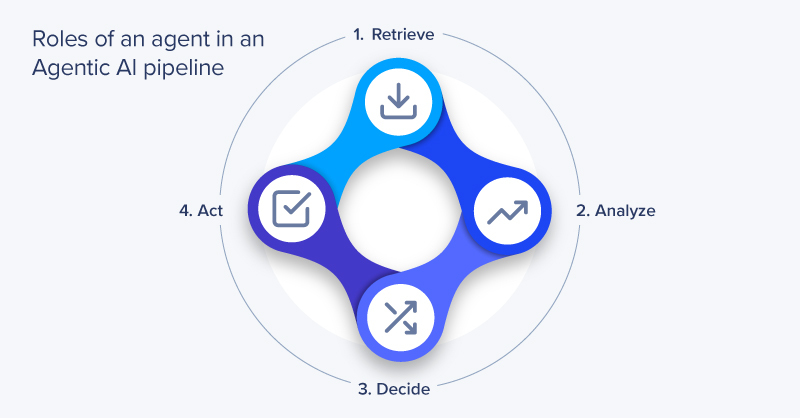
A multi-agent architecture consistently outperforms a single, monolithic AI model for complex enterprise workflows since models in each stage specialize in their task. It also enables parallel execution of tasks and allows for targeted scaling of individual components.
Deploying agentic AI pipelines on on-premises GPU clusters offers distinct advantages:
An on-premises, GPU-powered agentic AI system is typically structured into distinct layers, each with a specific function that contributes to the pipeline's overall operation.
| Layer | Function |
| GPU Servers | • Physical infrastructure consisting of servers equipped with high-performance GPUs that provide the necessary compute acceleration for agentic workloads. |
| Network Fabric | • High-throughput, low-latency east-west networking connects agents to each other, to storage, and to retrieval systems.
• Predictable tail latency matters for multi-hop workflows. |
| Data Plane (Storage + Shared State) | • Retrieval and action steps depend on a storage platform that houses model artifacts, vector embedding search, metadata, and more.
• Often the true bottleneck for throughput and responsiveness. |
| Orchestration Layer | • Responsible for scheduling agent workloads, allocating GPU resources, enforcing priorities, and managing the lifecycle of agent containers.
• Kubernetes, SLURM, and others. |
| Agent Layer | • Contains the individual, containerized AI agents.
• Each agent performs its specialized task—retrieval, analysis, decision, or action—as part of the broader workflow. |
| Operations + Governance | • Platform controls that make enterprise deployments operable and safe
• identity/access control, secrets management, audit logs, monitoring, and distributed tracing • debug latency and failures across hops. |
| Interfaces | • Provides APIs, dashboards, or integration points
• trigger workflows and interact with the agentic pipeline. |
This architecture is governed by a set of key principles designed to ensure scalability, security, and manageability:

Training, inferencing, and fine-tuning Agentic AI, LLMs, and traditional AI models on massive datasets can be accelerated exponentially with the right system. We provide the tool to propel and accelerate your research.
Configure NowHere are several methods that are proven to significantly improve the throughput, latency, and efficiency of agentic pipelines in on-premises deployments.
The economic advantages of the on-prem model become clear when analyzing factors beyond the raw cost of compute. While cloud computing can be an easy barrier to entry with low startup costs and bursty workloads, ongoing agentic AI costs can snowball very fast. On-prem hardware should be prioritized at high utilization, with additional hybrid cloud for temporary spikes in computing demand.
| Metric | On-Prem GPU Deployment | Cloud On-Demand GPUs |
| Cost per GPU-Hour | • Becomes very low after the initial capital expenditure is amortized over the hardware's lifespan. | • Remains a variable and recurring operational expense, billed hourly. |
| Egress Fees | • None. Data movement between internal systems does not incur additional charges. | • Applicable and often significant for any data transferred out of the cloud provider's network. |
| Data Duplication Costs | • Minimal. Data can be kept in a centralized, high-performance storage system accessible by all agents. | • Can be higher, as data often needs to be replicated across multiple regions or services for performance or availability. |
| Latency Costs | • Negligible. Ultra-low latency enables real-time applications that may not be feasible over the public internet. | • Potentially higher due to network hops and variability, which can impact application performance and user experience. |
| Electrical Usage | • Known facility power and cooling costs can be modeled up front as part of TCO, then optimized over time through utilization improvements. | • Indirect and bundled into hourly rates, but still paid for. • Costs are less visible, and optimization levers are limited. |
On-premises GPU clusters offer enterprises a powerful foundation for deploying agentic AI pipelines with security, performance, and cost predictability. By maintaining control over infrastructure, data, and workload optimization, organizations can build systems tailored to their specific requirements while avoiding the unpredictable costs and latency challenges of cloud-only approaches.
The architectural patterns, communication strategies, and economic considerations outlined in this guide provide a roadmap for designing scalable, efficient agentic AI deployments. While cloud resources remain valuable for handling overflow capacity and experimentation, the core of a production agentic AI system benefits from the stability and control that on-premises infrastructure provides.
Ready to scale up your computing infrastructure for agentic AI? Exxact offers custom configurable solutions from individual compute nodes to full rack scale designs. Talk to an engineer today!

Deploying full-scale AI models can be accelerated exponentially with the right computing infrastructure. Storage, head node, networking, compute - all components of your next Exxact cluster are configurable to your workload to drive and accelerate research and innovation.
Get a Quote TodayAgentic AI pipelines are computational architectures where multiple specialized AI agents collaborate to complete complex tasks. Each agent in the pipeline handles a specific function, such as retrieving data, analyzing it, making decisions, or executing actions in coordination to complete the larger goal.
In a nutshell, on-premises deployment advantages:
This article explores the advantages of on-premises GPU deployment, provides a high-level architectural view, explains orchestration and inter-agent communication, examines performance optimization patterns, evaluates economic considerations, and presents a practical starting strategy.
Agents within an agentic AI pipeline operate as distinct, specialized services, each designed to execute a specific step in a larger workflow.
A multi-agent architecture consistently outperforms a single, monolithic AI model for complex enterprise workflows since models in each stage specialize in their task. It also enables parallel execution of tasks and allows for targeted scaling of individual components.
Deploying agentic AI pipelines on on-premises GPU clusters offers distinct advantages:
An on-premises, GPU-powered agentic AI system is typically structured into distinct layers, each with a specific function that contributes to the pipeline's overall operation.
| Layer | Function |
| GPU Servers | • Physical infrastructure consisting of servers equipped with high-performance GPUs that provide the necessary compute acceleration for agentic workloads. |
| Network Fabric | • High-throughput, low-latency east-west networking connects agents to each other, to storage, and to retrieval systems.
• Predictable tail latency matters for multi-hop workflows. |
| Data Plane (Storage + Shared State) | • Retrieval and action steps depend on a storage platform that houses model artifacts, vector embedding search, metadata, and more.
• Often the true bottleneck for throughput and responsiveness. |
| Orchestration Layer | • Responsible for scheduling agent workloads, allocating GPU resources, enforcing priorities, and managing the lifecycle of agent containers.
• Kubernetes, SLURM, and others. |
| Agent Layer | • Contains the individual, containerized AI agents.
• Each agent performs its specialized task—retrieval, analysis, decision, or action—as part of the broader workflow. |
| Operations + Governance | • Platform controls that make enterprise deployments operable and safe
• identity/access control, secrets management, audit logs, monitoring, and distributed tracing • debug latency and failures across hops. |
| Interfaces | • Provides APIs, dashboards, or integration points
• trigger workflows and interact with the agentic pipeline. |
This architecture is governed by a set of key principles designed to ensure scalability, security, and manageability:
Training, inferencing, and fine-tuning Agentic AI, LLMs, and traditional AI models on massive datasets can be accelerated exponentially with the right system. We provide the tool to propel and accelerate your research.
Configure NowFor agentic pipelines, coordination overhead (network hops, serialization, and retries) can become a bigger bottleneck than raw GPU throughput. The communication and context layer should be designed for low latency, horizontal scale, and debuggability.
Here are several methods that are proven to significantly improve the throughput, latency, and efficiency of agentic pipelines in on-premises deployments.
The economic advantages of the on-prem model become clear when analyzing factors beyond the raw cost of compute. While cloud computing can be an easy barrier to entry with low startup costs and bursty workloads, ongoing agentic AI costs can snowball very fast. On-prem hardware should be prioritized at high utilization, with additional hybrid cloud for temporary spikes in computing demand.
| Metric | On-Prem GPU Deployment | Cloud On-Demand GPUs |
| Cost per GPU-Hour | • Becomes very low after the initial capital expenditure is amortized over the hardware's lifespan. | • Remains a variable and recurring operational expense, billed hourly. |
| Egress Fees | • None. Data movement between internal systems does not incur additional charges. | • Applicable and often significant for any data transferred out of the cloud provider's network. |
| Data Duplication Costs | • Minimal. Data can be kept in a centralized, high-performance storage system accessible by all agents. | • Can be higher, as data often needs to be replicated across multiple regions or services for performance or availability. |
| Latency Costs | • Negligible. Ultra-low latency enables real-time applications that may not be feasible over the public internet. | • Potentially higher due to network hops and variability, which can impact application performance and user experience. |
| Electrical Usage | • Known facility power and cooling costs can be modeled up front as part of TCO, then optimized over time through utilization improvements. | • Indirect and bundled into hourly rates, but still paid for. • Costs are less visible, and optimization levers are limited. |
On-premises GPU clusters offer enterprises a powerful foundation for deploying agentic AI pipelines with security, performance, and cost predictability. By maintaining control over infrastructure, data, and workload optimization, organizations can build systems tailored to their specific requirements while avoiding the unpredictable costs and latency challenges of cloud-only approaches.
The architectural patterns, communication strategies, and economic considerations outlined in this guide provide a roadmap for designing scalable, efficient agentic AI deployments. While cloud resources remain valuable for handling overflow capacity and experimentation, the core of a production agentic AI system benefits from the stability and control that on-premises infrastructure provides.
Ready to scale up your computing infrastructure for agentic AI? Exxact offers custom configurable solutions from individual compute nodes to full rack scale designs. Talk to an engineer today!
Deploying full-scale AI models can be accelerated exponentially with the right computing infrastructure. Storage, head node, networking, compute - all components of your next Exxact cluster are configurable to your workload to drive and accelerate research and innovation.
Get a Quote Today