HPC
Graphcore Update - Poplar SDK 2.4 and Latest Submission to MLPerf
February 2, 2022
6 min read


British semiconductor startup Graphcore develops chips and systems to accelerate AI workloads, which make it easier for innovators to harness the power of machine intelligence. Designed from the ground up with a completely different architecture to today’s CPUs (central processing units) and GPUs (graphics processing units), Graphcore’s intelligence processing unit (IPU) is a completely new kind of massively parallel, low-precision floating-point processor that supports the very specific computational requirements for AI and machine learning (ML).
The IPU delivers state of the art performance on current ML models for both training and inference. They are the brains and power of Graphcore’s IPU-POD data center compute systems.
The IPU performs the same role as a GPU in conjunction with standard machine learning frameworks, such as TensorFlow or PyTorch, but it relies on scratchpad memory for its performance rather than the traditional cache hierarchies. Also, instead of adopting a single instruction, multiple data/single instruction, multiple threads (SIMD/SIMT) architecture like a GPU, IPU uses a massively parallel and multiple instruction, multiple data (MIMD) architecture, with In-Processor Memory™-- ultra-high bandwidth memory placed adjacent to the processor cores, right on the silicon die.
The IPU was also co-designed with Poplar SDK to implement Graphcore’s graph toolchain in an easy to use and flexible software development environment. Poplar is fully integrated with standard machine learning frameworks so developers can port existing models easily and get up and running out-of-the-box with new applications in a familiar environment. Poplar moves data across its chip more efficiently, meaning less wasted processing power. It also does so at the right time, using all the processors in sequence.
Since Graphcore’s first generation Colossus MK1 IPU, there has been groundbreaking advances in compute, communication and memory in its silicon and systems architecture. The second generation Colossus MK2 GC200 IPU achieves an 8x step up in real-world performance compared to the Colossus MK1 IPU. The 7nm Colossus MK2 GC200 contains 59.4 billion transistors, 1,472 powerful processor cores, 8,832 independent parallel program threads, and 900MB In-Processor Memory™ with 250 teraFLOPS of AI compute at FP16.16 and FP16.SR (stochastic rounding), making it the world’s most complex and sophisticated processor. Thanks to Poplar software, it is also easy to deploy.
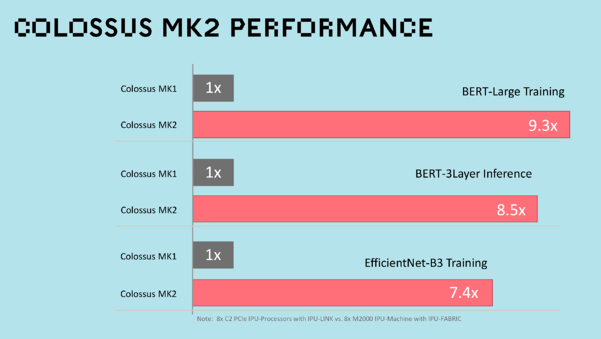
Image Source: Graphcore
Just as the IPU has seen advancements and improvements, the Poplar software stack has also gone through numerous enhancements, with the release of Poplar SDK 2.4 just recently made available. The software releases that lead up to Poplar SDK 2.4 brought optimizations and new ecosystem partnerships demonstrating continued progress, software maturity, ease-of-use, scale-out capabilities, and high-performing benchmarks. To help accelerate AI applications, Graphcore’s growing Model Garden has seen the most significant updates to provide greater model coverage across multiple ML domains, including computer vision, natural language processing (NLP), speech processing and graph neural networks (GNNs). These new models include vision transformer (ViT), UNet, generative pre-trained transformer (GPT), recurrent neural network transducer (RNN-T), FastSpeech2, temporal graph network (TGN), and more.
Additionally, in TensorFlow, the gradient accumulation count can now be specified at runtime for pipelined models, meaning that the global batch size can be define dynamically and enable more rapid experimentation when investigating or tuning the hyper-parameter. Poplar SDK 2.4 also introduces overlapping I/O and computing for Poplar advanced runtime (PopART) and PyTorch frameworks, which can boost compute efficiency and contribute to significantly accelerating programs running on the IPU hardware. PopVision analysis tools continue to provide developers with a deeper understanding of how their applications are performing, with enhanced IPU utilization reporting added for the PopVision System Analyzer with this release.
Graphcore’s current breakthrough IPU system, the IPU-M2000, is built with not one but four Colossus MK2 GC200 IPUs, delivering a whopping 1 petaFLOP of AI compute and up to 450GB Exchange-Memory™ (3.6GB In-Processor Memory + up to 448GB Streaming Memory™) in a slim 1U blade. The flexible, modular design lets users start with one and connect to a host server from one of Graphcore’s partners, such as Exxact Corp, to build an entry level IPU-POD4 system. EDU pricing is available to help get started with the IPU-POD4 and users can scale up to a total of eight IPU-M2000s connected to the one server, as needs grow.
For larger systems, users can build 16 IPU-M2000s into a standard 19-inch rack for an IPU-POD64 and scale out from there to deliver data center-scale Machine Intelligence compute. In fact, users can scale up to 64,000 IPUs across 1,024 racks, at which point the fully configured AI supercomputer can deliver an astonishing 16 exaflops of AI performance.
Interested in a Graphcore AI Solution?
Click here to learn more
Graphcore’s latest submission to MLPerf demonstrated that its IPU systems are getting bigger and more efficient, and software maturity means they are also getting faster and easier to use.
To reflect Graphcore’s commitment to deliver outstanding performance at increasing scale, it entered IPU-POD128 and IPU-POD256 straight into MLPerf’s “available” category and the time-to-train on ResNet-50 were 5.67 minutes and 3.79 minutes, respectively.
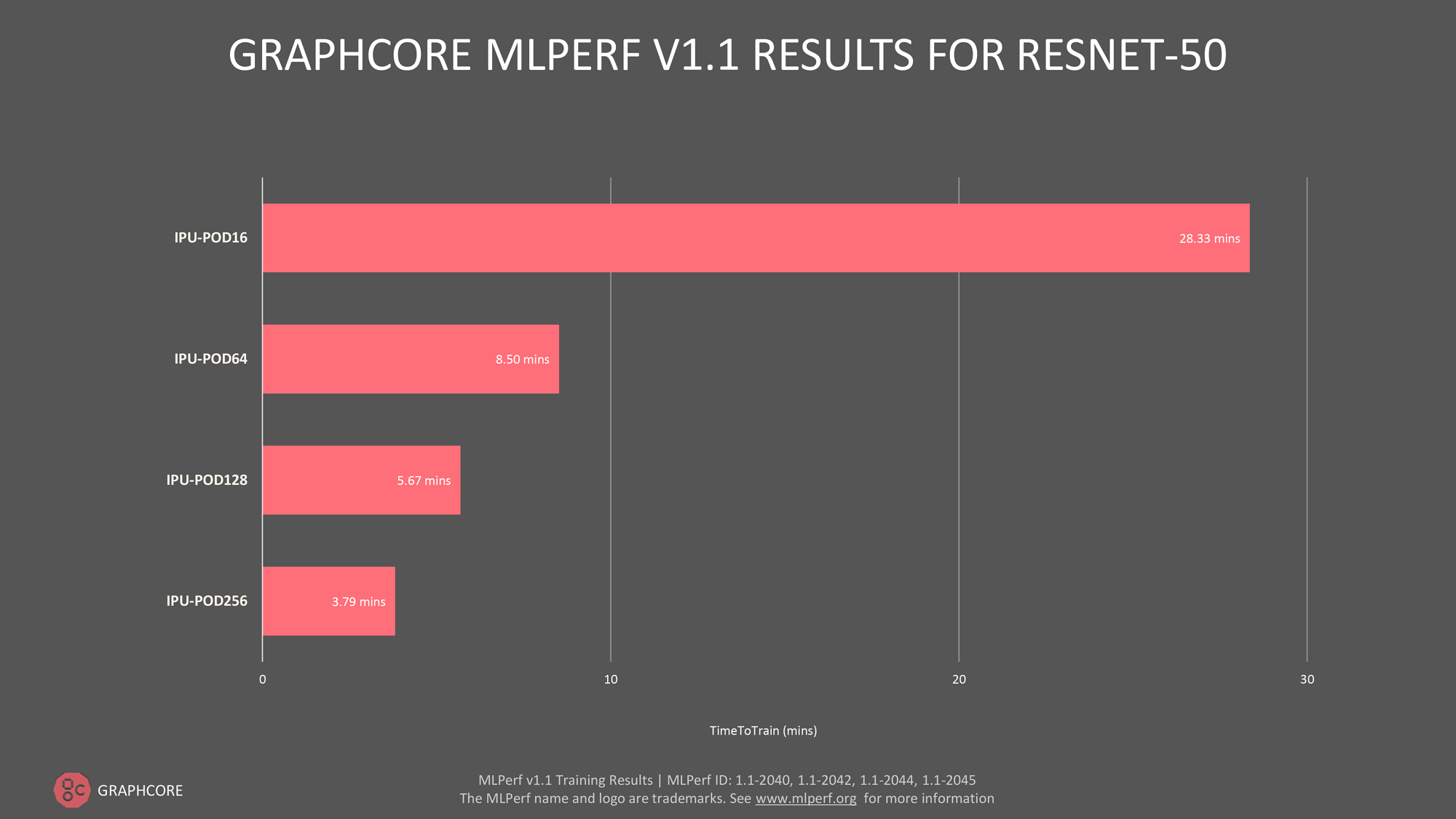
Image Source: Graphcore
For NLP model BERT (Bidirectional Encoder Representation from Transformers), IPU-POD16, IPU-POD64 and IPU-POD128 were submitted in both open and closed categories. Compared to the last MLPerf round, there were improvements of 5% for IPU-POD16 and 12% for IPU-POD64. There was no data for IPU-POD128 for the last round, but it had an impressive time-to-train of 5.78 minutes for this round in the open submission.
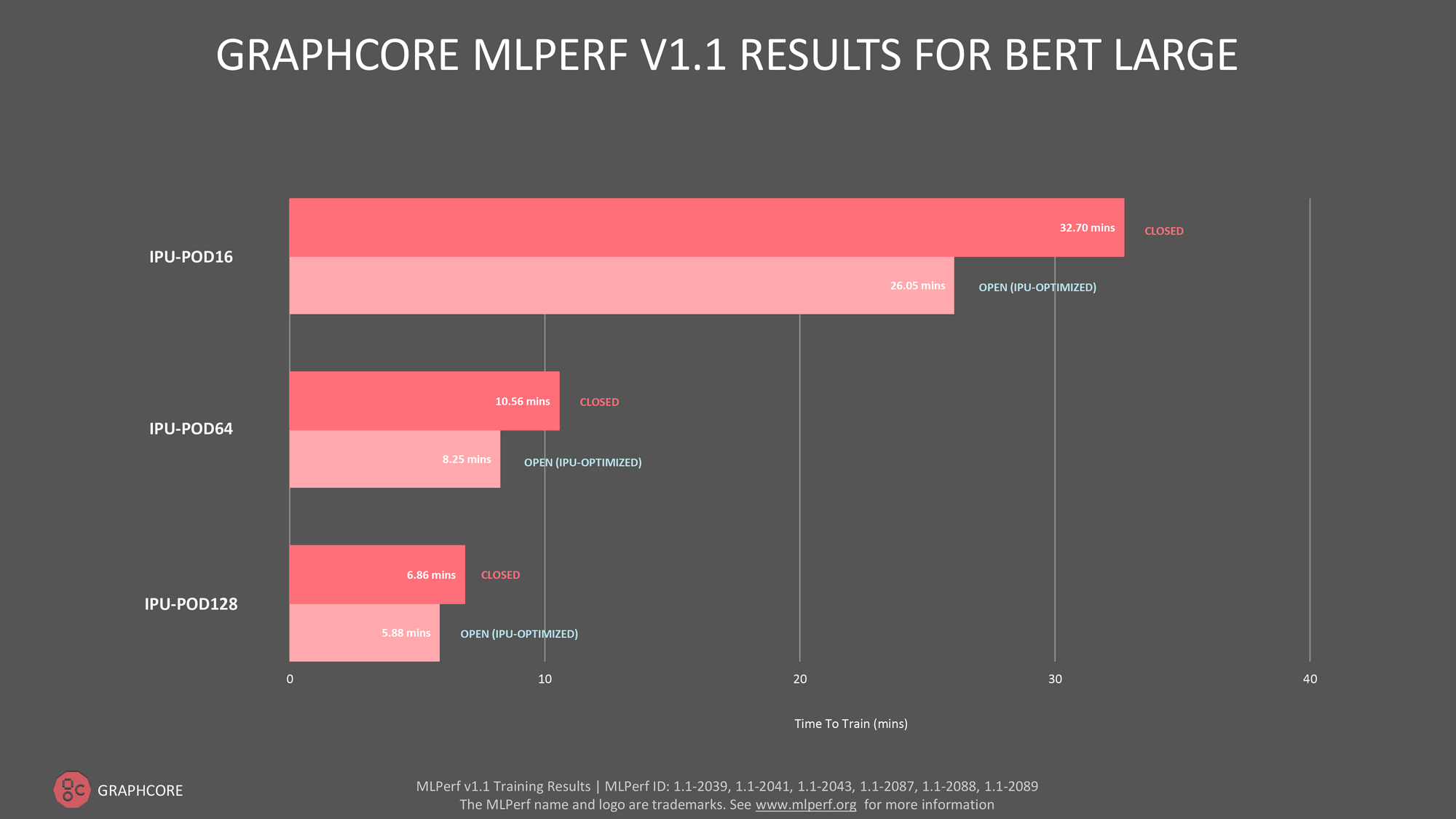
Image Source: Graphcore
The combination of continuous optimization to Poplar SDK and introduction of new IPU-POD products has enabled a dramatic increase in the AI training capability that Graphcore and Exxact are able to offer customers. With EDU pricing available, qualified researchers and developers can begin using models like ResNET and BERT to explore innovative and new models that can help deliver machine intelligence at scale.
Have any questions?
Contact Exxact Today
British semiconductor startup Graphcore develops chips and systems to accelerate AI workloads, which make it easier for innovators to harness the power of machine intelligence. Designed from the ground up with a completely different architecture to today’s CPUs (central processing units) and GPUs (graphics processing units), Graphcore’s intelligence processing unit (IPU) is a completely new kind of massively parallel, low-precision floating-point processor that supports the very specific computational requirements for AI and machine learning (ML).
The IPU delivers state of the art performance on current ML models for both training and inference. They are the brains and power of Graphcore’s IPU-POD data center compute systems.
The IPU performs the same role as a GPU in conjunction with standard machine learning frameworks, such as TensorFlow or PyTorch, but it relies on scratchpad memory for its performance rather than the traditional cache hierarchies. Also, instead of adopting a single instruction, multiple data/single instruction, multiple threads (SIMD/SIMT) architecture like a GPU, IPU uses a massively parallel and multiple instruction, multiple data (MIMD) architecture, with In-Processor Memory™-- ultra-high bandwidth memory placed adjacent to the processor cores, right on the silicon die.
The IPU was also co-designed with Poplar SDK to implement Graphcore’s graph toolchain in an easy to use and flexible software development environment. Poplar is fully integrated with standard machine learning frameworks so developers can port existing models easily and get up and running out-of-the-box with new applications in a familiar environment. Poplar moves data across its chip more efficiently, meaning less wasted processing power. It also does so at the right time, using all the processors in sequence.
Since Graphcore’s first generation Colossus MK1 IPU, there has been groundbreaking advances in compute, communication and memory in its silicon and systems architecture. The second generation Colossus MK2 GC200 IPU achieves an 8x step up in real-world performance compared to the Colossus MK1 IPU. The 7nm Colossus MK2 GC200 contains 59.4 billion transistors, 1,472 powerful processor cores, 8,832 independent parallel program threads, and 900MB In-Processor Memory™ with 250 teraFLOPS of AI compute at FP16.16 and FP16.SR (stochastic rounding), making it the world’s most complex and sophisticated processor. Thanks to Poplar software, it is also easy to deploy.
Image Source: Graphcore
Just as the IPU has seen advancements and improvements, the Poplar software stack has also gone through numerous enhancements, with the release of Poplar SDK 2.4 just recently made available. The software releases that lead up to Poplar SDK 2.4 brought optimizations and new ecosystem partnerships demonstrating continued progress, software maturity, ease-of-use, scale-out capabilities, and high-performing benchmarks. To help accelerate AI applications, Graphcore’s growing Model Garden has seen the most significant updates to provide greater model coverage across multiple ML domains, including computer vision, natural language processing (NLP), speech processing and graph neural networks (GNNs). These new models include vision transformer (ViT), UNet, generative pre-trained transformer (GPT), recurrent neural network transducer (RNN-T), FastSpeech2, temporal graph network (TGN), and more.
Additionally, in TensorFlow, the gradient accumulation count can now be specified at runtime for pipelined models, meaning that the global batch size can be define dynamically and enable more rapid experimentation when investigating or tuning the hyper-parameter. Poplar SDK 2.4 also introduces overlapping I/O and computing for Poplar advanced runtime (PopART) and PyTorch frameworks, which can boost compute efficiency and contribute to significantly accelerating programs running on the IPU hardware. PopVision analysis tools continue to provide developers with a deeper understanding of how their applications are performing, with enhanced IPU utilization reporting added for the PopVision System Analyzer with this release.
Graphcore’s current breakthrough IPU system, the IPU-M2000, is built with not one but four Colossus MK2 GC200 IPUs, delivering a whopping 1 petaFLOP of AI compute and up to 450GB Exchange-Memory™ (3.6GB In-Processor Memory + up to 448GB Streaming Memory™) in a slim 1U blade. The flexible, modular design lets users start with one and connect to a host server from one of Graphcore’s partners, such as Exxact Corp, to build an entry level IPU-POD4 system. EDU pricing is available to help get started with the IPU-POD4 and users can scale up to a total of eight IPU-M2000s connected to the one server, as needs grow.
For larger systems, users can build 16 IPU-M2000s into a standard 19-inch rack for an IPU-POD64 and scale out from there to deliver data center-scale Machine Intelligence compute. In fact, users can scale up to 64,000 IPUs across 1,024 racks, at which point the fully configured AI supercomputer can deliver an astonishing 16 exaflops of AI performance.
Interested in a Graphcore AI Solution?
Click here to learn more
Graphcore’s latest submission to MLPerf demonstrated that its IPU systems are getting bigger and more efficient, and software maturity means they are also getting faster and easier to use.
To reflect Graphcore’s commitment to deliver outstanding performance at increasing scale, it entered IPU-POD128 and IPU-POD256 straight into MLPerf’s “available” category and the time-to-train on ResNet-50 were 5.67 minutes and 3.79 minutes, respectively.
Image Source: Graphcore
For NLP model BERT (Bidirectional Encoder Representation from Transformers), IPU-POD16, IPU-POD64 and IPU-POD128 were submitted in both open and closed categories. Compared to the last MLPerf round, there were improvements of 5% for IPU-POD16 and 12% for IPU-POD64. There was no data for IPU-POD128 for the last round, but it had an impressive time-to-train of 5.78 minutes for this round in the open submission.
Image Source: Graphcore
The combination of continuous optimization to Poplar SDK and introduction of new IPU-POD products has enabled a dramatic increase in the AI training capability that Graphcore and Exxact are able to offer customers. With EDU pricing available, qualified researchers and developers can begin using models like ResNET and BERT to explore innovative and new models that can help deliver machine intelligence at scale.
Have any questions?
Contact Exxact Today
