Artificial Intelligence
Scikit-Learn & More for Synthetic Dataset Generation for Machine Learning
August 28, 2019
18 min read


It is becoming increasingly clear that the big tech giants such as Google, Facebook, and Microsoft are extremely generous with their latest machine learning algorithms and packages (they give those away freely) because the entry barrier to the world of algorithms is pretty low right now. The open source community and tools (such as Scikit Learn) have come a long way and plenty of open source initiatives are propelling the vehicles of data science, digital analytics, and machine learning. Standing in 2018 we can safely say that, algorithms, programming frameworks, and machine learning packages (or even tutorials and courses how to learn these techniques) are not the scarce resource but high-quality data is.
This often becomes a thorny issue on the side of the practitioners in data science (DS) and machine learning (ML) when it comes to tweaking and fine-tuning those algorithms. It will also be wise to point out, at the very beginning, that the current article pertains to the scarcity of data for algorithmic investigation, pedagogical learning, and model prototyping, and not for scaling and running a commercial operation. It is not a discussion about how to get quality data for the cool travel or fashion app you are working on. That kind of consumer, social, or behavioral data collection presents its own issues. However, even something as simple as having access to quality datasets for testing out the limitations and vagaries of a particular algorithmic method, often turns out, not so simple.
If you are learning from scratch, the most sound advice would be to start with simple, small-scale datasets which you can plot in two dimensions to understand the patterns visually and see for yourself the working of the ML algorithm in an intuitive fashion.
As the dimensions of the data explode, however, the visual judgement must extends to more complicated matters - concepts like learning and sample complexity, computational efficiency, class imbalance, etc.
At this point, the trade off between experimental flexibility and the nature of the dataset comes into play. You can always find yourself a real-life large dataset to practice the algorithm on. But that is still a fixed dataset, with a fixed number of samples, a fixed underlying pattern, and a fixed degree of class separation between positive and negative samples. You must also investigate,
Turns out that these are quite difficult to do with a single real-life dataset and therefore, you must be willing to work with synthetic data which are random enough to capture all the vagaries of a real-life dataset but controllable enough to help you scientifically investigate the strength and weakness of the particular ML pipeline you are building.
Although we won’t discuss the matter in this article, the potential benefit of such synthetic datasets can easily be gauged for sensitive applications - medical classifications or financial modeling, where getting hands on a high-quality labeled dataset is often expensive and prohibitive.

It is understood, at this point, that a synthetic dataset is generated programmatically, and not sourced from any kind of social or scientific experiment, business transactional data, sensor reading, or manual labeling of images. However, such dataset are definitely not completely random, and the generation and usage of synthetic data for ML must be guided by some overarching needs. In particular,
We will show, in the next section, how using some of the most popular ML libraries, and programmatic techniques, one is able to generate suitable datasets.
Scikit learn is the most popular ML library in the Python-based software stack for data science. Apart from the well-optimized ML routines and pipeline building methods, it also boasts of a solid collection of utility methods for synthetic data generation.
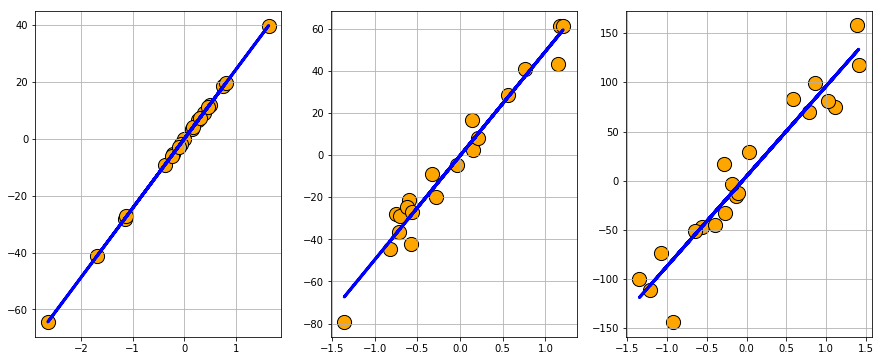
Scikit learn’s dataset.make_regression function can create random regression problem with arbitrary number of input features, output targets, and controllable degree of informative coupling between them.
Similar to the regression function above, dataset.make_classification generates a random multi-class classification problem with controllable class separation and added noise. You can also randomly flip any percentage of output signs to create a harder classification dataset if you want.
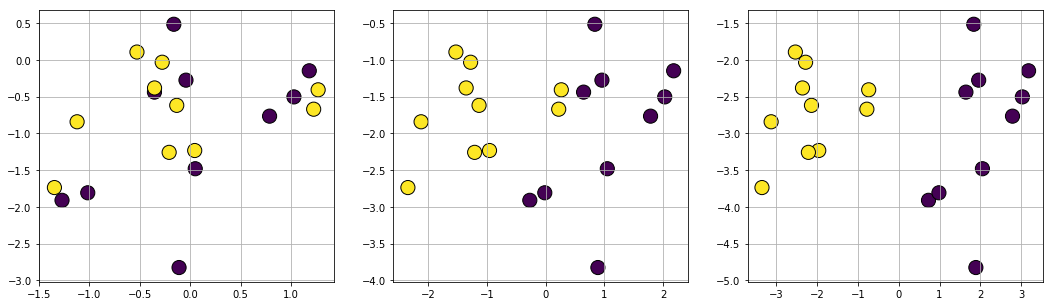
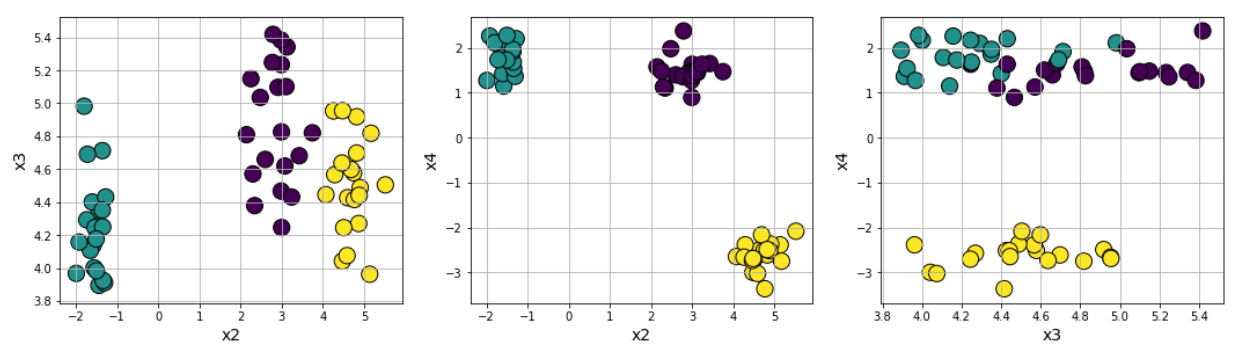
A variety of clustering problems can be generated by Scikit learn utility functions. The most straightforward is to use the datasets.make_blobs, which generates arbitrary number of clusters with controllable distance parameters.
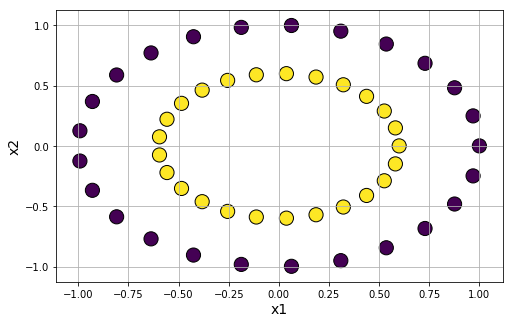
For testing affinity based clustering algorithm or Gaussian mixture models, it is useful to have clusters generated in a special shape. We can use datasets.make_circles function to accomplish that.
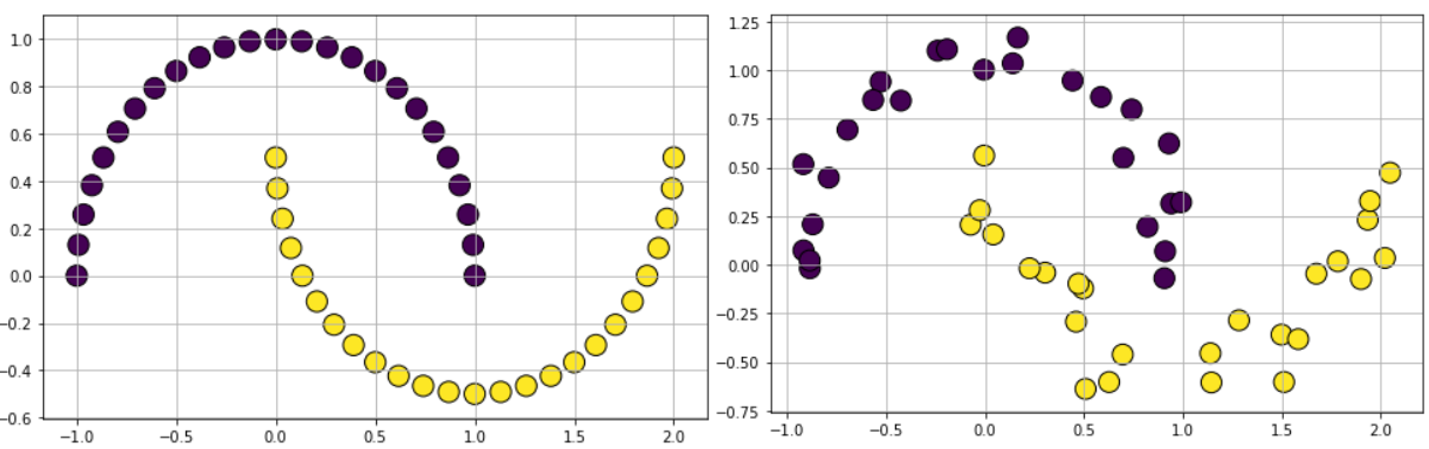
For testing non-linear kernel methods with support vector machine (SVM) algorithm, nearest-neighbor methods like k-NN, or even testing out a simple neural network, it is often advisable to experiment with certain shaped data. We can generate such data using dataset.make_moon function with controllable noise.
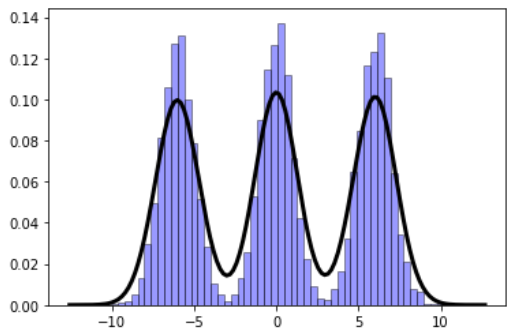
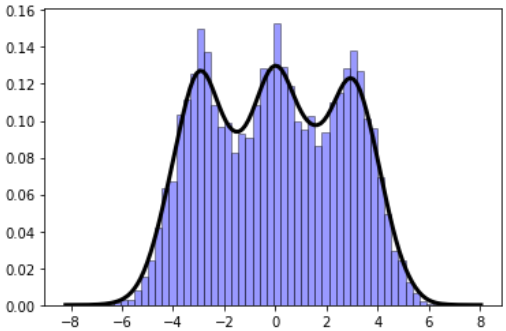
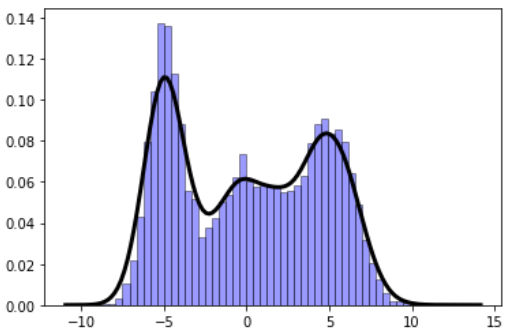
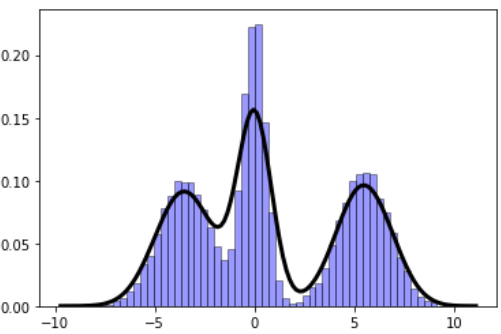
Gaussian mixture models (GMM) are fascinating objects to study for unsupervised learning and topic modeling in the text processing/NLP tasks. Here is an illustration of a simple function to show how easy it is to generate synthetic data for such a model:
import numpy as np import matplotlib.pyplot as plt import random def gen_GMM(N=1000,n_comp=3, mu=[-1,0,1],sigma=[1,1,1],mult=[1,1,1]): """ Generates a Gaussian mixture model data, from a given list of Gaussian components N: Number of total samples (data points) n_comp: Number of Gaussian components mu: List of mean values of the Gaussian components sigma: List of sigma (std. dev) values of the Gaussian components mult: (Optional) list of multiplier for the Gaussian components ) """ assert n_comp == len(mu), "The length of the list of mean values does not match number of Gaussian components" assert n_comp == len(sigma), "The length of the list of sigma values does not match number of Gaussian components" assert n_comp == len(mult), "The length of the list of multiplier values does not match number of Gaussian components" rand_samples = [] for i in range(N): pivot = random.uniform(0,n_comp) j = int(pivot) rand_samples.append(mult[j]*random.gauss(mu[j],sigma[j])) return np.array(rand_samples)
While the afore-mentioned functions may be sufficient for many problems, the data generated is truly random and user has less control on the actual mechanics of the generation process. In many situations, one may require a controllable way to generate regression or classification problems based on a well-defined analytical function (involving linear, nonlinear, rational, or even transcendental terms). The following article shows how one can combine the symbolic mathematics package SymPy and functions from SciPy to generate synthetic regression and classification problems from given symbolic expressions.
Random regression and classification problem generation with symbolic expression
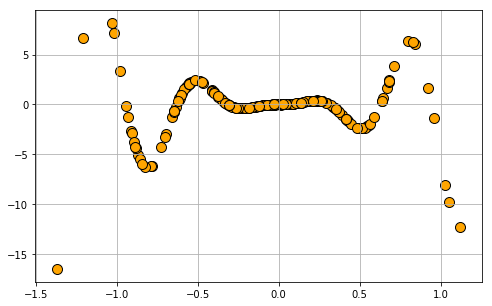
Regression dataset generated from a given symbolic expression.
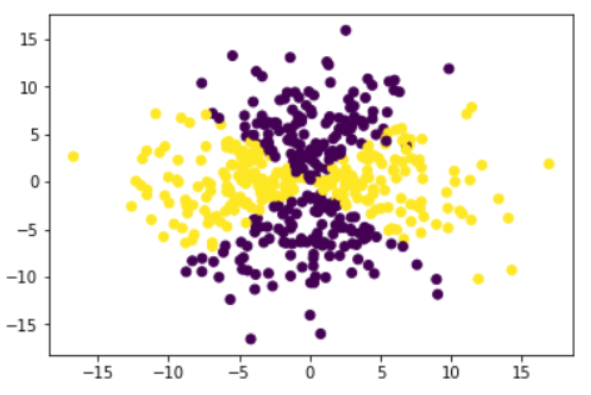
Classification dataset generated from a given symbolic expression.
Deep learning systems and algorithms are voracious consumers of data. However, to test the limitations and robustness of a deep learning algorithm, one often needs to feed the algorithm with subtle variations of similar images. Scikit image is an amazing image processing library, built on the same design principle and API pattern as that of scikit learn, offering hundreds of cool functions to accomplish this image data augmentation task.
The following article does a great job of providing a comprehensive overview of lot of these ideas:
Data Augmentation | How to use Deep Learning when you have Limited Data.
We show some chosen examples of this augmentation process, starting with a single image and creating tens of variations on the same to effectively multiply the dataset manyfold and create a synthetic dataset of gigantic size to train deep learning models in a robust manner.
Hue, Saturation, Value channels

Cropping

Random noise

Rotation

Swirl

NVIDIA offers a UE4 plugin called NDDS to empower computer vision researchers to export high-quality synthetic images with metadata. It supports images, segmentation, depth, object pose, bounding box, keypoints, and custom stencils. In addition to the exporter, the plugin includes various components enabling generation of randomized images for data augmentation and object detection algorithm training. The randomization utilities includes lighting, objects, camera position, poses, textures, and distractors. Together, these components allow deep learning engineers to easily create randomized scenes for training their CNN. Here is the Github link,
NVIDIA Deep Learning Data Synthesizer
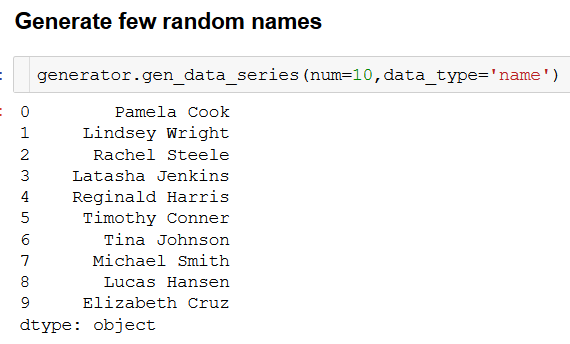
Pydbgen is a lightweight, pure-python library to generate random useful entries (e.g. name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in either Pandas dataframe object, or as a SQLite table in a database file, or in an MS Excel file. You can read the documentation here. Here is an article describing its use and utilities,
Introducing pydbgen: A random dataframe/database table generator
Here are few illustrative examples,
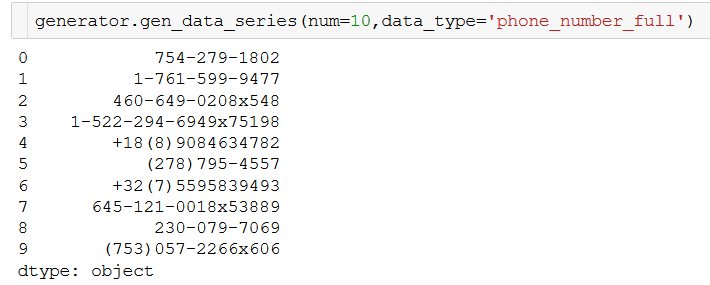
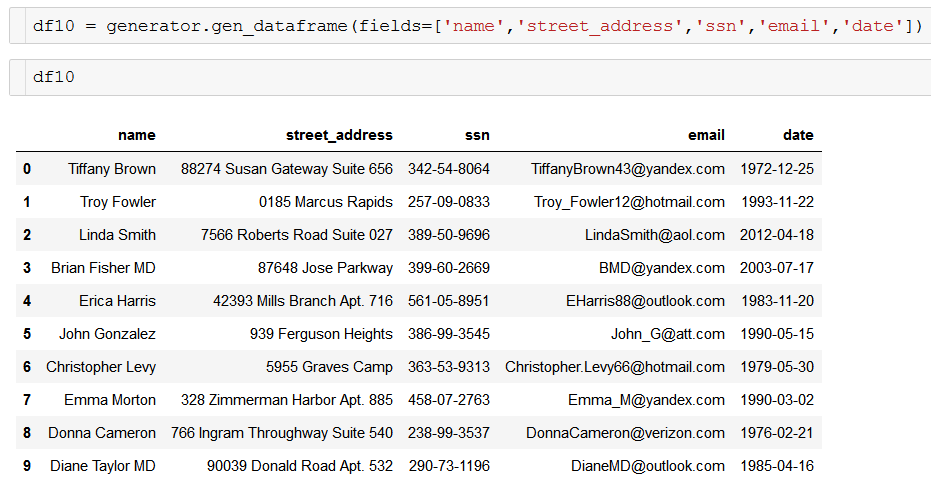
There are quite a few papers and code repositories for generating synthetic time-series data using special functions and patterns observed in real-life multivariate time series. A simple example is given in the following Github link:
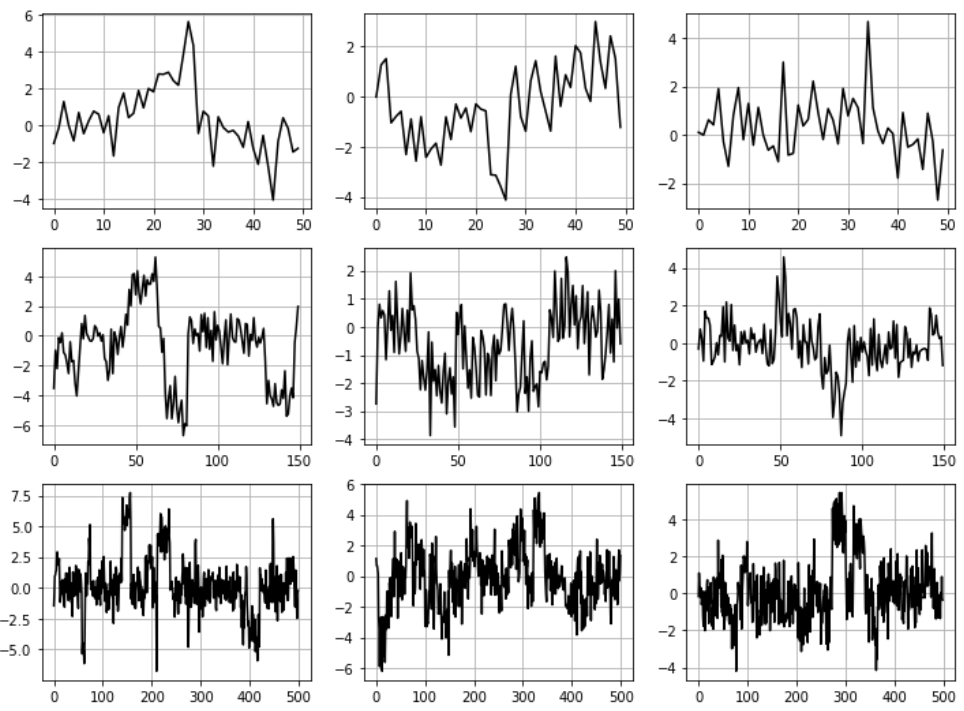
Audio/speech processing is a domain of particular interest for deep learning practitioners and ML enthusiasts. Google’s NSynth dataset is a synthetically generated (using neural autoencoders and a combination of human and heuristic labelling) library of short audio files sound made by musical instruments of various kinds. Here is the detailed description of the dataset.
The greatest repository for synthetic learning environment for reinforcement ML is OpenAI Gym. It consists of a large number of pre-programmed environments onto which users can implement their own reinforcement learning algorithms for benchmarking the performance or troubleshooting hidden weakness.
For beginners in reinforcement learning, it often helps to practice and experiment with a simple grid world where an agent must navigate through a maze to reach a terminal state with given reward/penalty for each step and the terminal states.
With few simple lines of code, one can synthesize grid world environments with arbitrary size and complexity (with user-specified distribution of terminal states and reward vectors).
Take a look at this Github repo for ideas and code examples.
https://github.com/tirthajyoti/RL_basics
In this article, we went over a few examples of synthetic data generation for machine learning. It should be clear to the reader that, by no means, these represent the exhaustive list of data generating techniques. In fact, many commercial apps other than Scikit Learn are offering the same service as the need of training your ML model with a variety of data is increasing at a fast pace. However, if, as a data scientist or ML engineer, you create your own programmatic method of synthetic data generation, it saves your organization money and resources to invest in a third-party app and also lets you plan the development of your ML pipeline in a holistic and organic fashion.
Hope you enjoyed this article and can start using some of the techniques, described here, in your own projects soon.

It is becoming increasingly clear that the big tech giants such as Google, Facebook, and Microsoft are extremely generous with their latest machine learning algorithms and packages (they give those away freely) because the entry barrier to the world of algorithms is pretty low right now. The open source community and tools (such as Scikit Learn) have come a long way and plenty of open source initiatives are propelling the vehicles of data science, digital analytics, and machine learning. Standing in 2018 we can safely say that, algorithms, programming frameworks, and machine learning packages (or even tutorials and courses how to learn these techniques) are not the scarce resource but high-quality data is.
This often becomes a thorny issue on the side of the practitioners in data science (DS) and machine learning (ML) when it comes to tweaking and fine-tuning those algorithms. It will also be wise to point out, at the very beginning, that the current article pertains to the scarcity of data for algorithmic investigation, pedagogical learning, and model prototyping, and not for scaling and running a commercial operation. It is not a discussion about how to get quality data for the cool travel or fashion app you are working on. That kind of consumer, social, or behavioral data collection presents its own issues. However, even something as simple as having access to quality datasets for testing out the limitations and vagaries of a particular algorithmic method, often turns out, not so simple.
If you are learning from scratch, the most sound advice would be to start with simple, small-scale datasets which you can plot in two dimensions to understand the patterns visually and see for yourself the working of the ML algorithm in an intuitive fashion.
As the dimensions of the data explode, however, the visual judgement must extends to more complicated matters - concepts like learning and sample complexity, computational efficiency, class imbalance, etc.
At this point, the trade off between experimental flexibility and the nature of the dataset comes into play. You can always find yourself a real-life large dataset to practice the algorithm on. But that is still a fixed dataset, with a fixed number of samples, a fixed underlying pattern, and a fixed degree of class separation between positive and negative samples. You must also investigate,
Turns out that these are quite difficult to do with a single real-life dataset and therefore, you must be willing to work with synthetic data which are random enough to capture all the vagaries of a real-life dataset but controllable enough to help you scientifically investigate the strength and weakness of the particular ML pipeline you are building.
Although we won’t discuss the matter in this article, the potential benefit of such synthetic datasets can easily be gauged for sensitive applications - medical classifications or financial modeling, where getting hands on a high-quality labeled dataset is often expensive and prohibitive.
It is understood, at this point, that a synthetic dataset is generated programmatically, and not sourced from any kind of social or scientific experiment, business transactional data, sensor reading, or manual labeling of images. However, such dataset are definitely not completely random, and the generation and usage of synthetic data for ML must be guided by some overarching needs. In particular,
We will show, in the next section, how using some of the most popular ML libraries, and programmatic techniques, one is able to generate suitable datasets.
Scikit learn is the most popular ML library in the Python-based software stack for data science. Apart from the well-optimized ML routines and pipeline building methods, it also boasts of a solid collection of utility methods for synthetic data generation.
Scikit learn’s dataset.make_regression function can create random regression problem with arbitrary number of input features, output targets, and controllable degree of informative coupling between them.
Similar to the regression function above, dataset.make_classification generates a random multi-class classification problem with controllable class separation and added noise. You can also randomly flip any percentage of output signs to create a harder classification dataset if you want.
A variety of clustering problems can be generated by Scikit learn utility functions. The most straightforward is to use the datasets.make_blobs, which generates arbitrary number of clusters with controllable distance parameters.
For testing affinity based clustering algorithm or Gaussian mixture models, it is useful to have clusters generated in a special shape. We can use datasets.make_circles function to accomplish that.
For testing non-linear kernel methods with support vector machine (SVM) algorithm, nearest-neighbor methods like k-NN, or even testing out a simple neural network, it is often advisable to experiment with certain shaped data. We can generate such data using dataset.make_moon function with controllable noise.
Gaussian mixture models (GMM) are fascinating objects to study for unsupervised learning and topic modeling in the text processing/NLP tasks. Here is an illustration of a simple function to show how easy it is to generate synthetic data for such a model:
import numpy as np import matplotlib.pyplot as plt import random def gen_GMM(N=1000,n_comp=3, mu=[-1,0,1],sigma=[1,1,1],mult=[1,1,1]): """ Generates a Gaussian mixture model data, from a given list of Gaussian components N: Number of total samples (data points) n_comp: Number of Gaussian components mu: List of mean values of the Gaussian components sigma: List of sigma (std. dev) values of the Gaussian components mult: (Optional) list of multiplier for the Gaussian components ) """ assert n_comp == len(mu), "The length of the list of mean values does not match number of Gaussian components" assert n_comp == len(sigma), "The length of the list of sigma values does not match number of Gaussian components" assert n_comp == len(mult), "The length of the list of multiplier values does not match number of Gaussian components" rand_samples = [] for i in range(N): pivot = random.uniform(0,n_comp) j = int(pivot) rand_samples.append(mult[j]*random.gauss(mu[j],sigma[j])) return np.array(rand_samples)
While the afore-mentioned functions may be sufficient for many problems, the data generated is truly random and user has less control on the actual mechanics of the generation process. In many situations, one may require a controllable way to generate regression or classification problems based on a well-defined analytical function (involving linear, nonlinear, rational, or even transcendental terms). The following article shows how one can combine the symbolic mathematics package SymPy and functions from SciPy to generate synthetic regression and classification problems from given symbolic expressions.
Random regression and classification problem generation with symbolic expression
Regression dataset generated from a given symbolic expression.
Classification dataset generated from a given symbolic expression.
Deep learning systems and algorithms are voracious consumers of data. However, to test the limitations and robustness of a deep learning algorithm, one often needs to feed the algorithm with subtle variations of similar images. Scikit image is an amazing image processing library, built on the same design principle and API pattern as that of scikit learn, offering hundreds of cool functions to accomplish this image data augmentation task.
The following article does a great job of providing a comprehensive overview of lot of these ideas:
Data Augmentation | How to use Deep Learning when you have Limited Data.
We show some chosen examples of this augmentation process, starting with a single image and creating tens of variations on the same to effectively multiply the dataset manyfold and create a synthetic dataset of gigantic size to train deep learning models in a robust manner.
Hue, Saturation, Value channels
Cropping
Random noise
Rotation
Swirl
NVIDIA offers a UE4 plugin called NDDS to empower computer vision researchers to export high-quality synthetic images with metadata. It supports images, segmentation, depth, object pose, bounding box, keypoints, and custom stencils. In addition to the exporter, the plugin includes various components enabling generation of randomized images for data augmentation and object detection algorithm training. The randomization utilities includes lighting, objects, camera position, poses, textures, and distractors. Together, these components allow deep learning engineers to easily create randomized scenes for training their CNN. Here is the Github link,
NVIDIA Deep Learning Data Synthesizer
Pydbgen is a lightweight, pure-python library to generate random useful entries (e.g. name, address, credit card number, date, time, company name, job title, license plate number, etc.) and save them in either Pandas dataframe object, or as a SQLite table in a database file, or in an MS Excel file. You can read the documentation here. Here is an article describing its use and utilities,
Introducing pydbgen: A random dataframe/database table generator
Here are few illustrative examples,
There are quite a few papers and code repositories for generating synthetic time-series data using special functions and patterns observed in real-life multivariate time series. A simple example is given in the following Github link:
Audio/speech processing is a domain of particular interest for deep learning practitioners and ML enthusiasts. Google’s NSynth dataset is a synthetically generated (using neural autoencoders and a combination of human and heuristic labelling) library of short audio files sound made by musical instruments of various kinds. Here is the detailed description of the dataset.
The greatest repository for synthetic learning environment for reinforcement ML is OpenAI Gym. It consists of a large number of pre-programmed environments onto which users can implement their own reinforcement learning algorithms for benchmarking the performance or troubleshooting hidden weakness.
For beginners in reinforcement learning, it often helps to practice and experiment with a simple grid world where an agent must navigate through a maze to reach a terminal state with given reward/penalty for each step and the terminal states.
With few simple lines of code, one can synthesize grid world environments with arbitrary size and complexity (with user-specified distribution of terminal states and reward vectors).
Take a look at this Github repo for ideas and code examples.
https://github.com/tirthajyoti/RL_basics
In this article, we went over a few examples of synthetic data generation for machine learning. It should be clear to the reader that, by no means, these represent the exhaustive list of data generating techniques. In fact, many commercial apps other than Scikit Learn are offering the same service as the need of training your ML model with a variety of data is increasing at a fast pace. However, if, as a data scientist or ML engineer, you create your own programmatic method of synthetic data generation, it saves your organization money and resources to invest in a third-party app and also lets you plan the development of your ML pipeline in a holistic and organic fashion.
Hope you enjoyed this article and can start using some of the techniques, described here, in your own projects soon.
