Artificial Intelligence
Run:ai: You've got Idle GPUs. We Guarantee It.
September 8, 2022
12 min read


It’s almost inevitable that any GPU cluster has unused hardware. In fact, many data scientists lack the understanding of GPU utilization in their clusters, many of which believe that they have 50 - 60% of their hardware being utilized at any given time.
Run:ai surveyed data scientists' GPU usage and found an overwhelming majority never having over 25% GPU utilization! Your most expensive investments are just sitting idle doing nothing, while projects continued to be back up and bottlenecked.
They posted this same command on GitHub called rntop (pronounced run top) that shows your cluster’s GPU usage across a connected infrastructure. Similar to how nvidia smi shows the GPU utilization on one bare metal solution, rntop can view all GPU nodes in a cluster.
You can find rntop here posted on GitHub by Run:ai’s team!
It hurts to hear that your precious investments in your AI Cluster are being wasted, just sitting idle while your jobs are being bottlenecked and backed up. How can your extremely fast and expensive hardware possibly be so slow?
GPU resources are static, bound to their bare metal system. I have GPUs in my workstation, you have GPUs in your workstation, and the server room has a whole bunch of GPUs in its system. However, there is no easy way to know when and where resources are not being utilized. When my workloads don’t require a GPU, my resources aren’t being used to help anybody else… selfish right?
Even in AI infrastructures where GPU resources are “shared” between jobs the allocation is static in which GPUs are assigned to jobs from start to finish. When server racks of GPUs finish jobs, they go cold until a new job is assigned to them. AI workloads are sometimes sequential, with jobs pending and constant start stops when testing, validating, building, and deploying, it becomes difficult to keep up and reach higher utilization.
For AI workloads, the amount of required computing fluctuates; our static allocation of GPUs hinders flexibility, scalability, and visibility. And when GPUs aren’t in use they should be used elsewhere to accelerate whatever is being built, trained, or deployed.

Founders Omri Geller and Dr. Ronen Dar founded Run:ai. Run:ai is a cloud-native Kubernetes-based orchestration tool that enables data scientists to accelerate, innovate, and complete AI initiatives faster. Reach peak utilization and efficiency by incorporating an AI-dedicated, high-performant super-scheduler tailored for managing NVIDIA CUDA-enable GPU resources. The platform provides IT and MLOps with visibility and control over job scheduling and dynamic GPU resource provisioning.
Kubernetes is the de facto standard for cloud-native scheduling but they are built for microservices and short instances, not multiple large sequential jobs queued together. Kubernetes lack the critical high-performance scheduling needed for AI workloads like batch scheduling, preemption (start, stop, pause, resume), and smart queuing. Because AI workloads are long formats of jobs (build, train, inference) Kubernetes need a lot more reorganization and autonomy to handle such a complex workload.
The Team at Run:ai builds upon Kubernetes to develop to ultimate AI workload orchestration by incorporating:
Run:ai creates a virtualization and acceleration layer over disaggregated GPU resources for granular scheduling, prioritization, and computing power allocation. Their orchestration tool has helped researchers consume resources to their fullest potential by dynamically optimizing hardware utilization for AI workloads. Enabling clusters to operate at peak efficiency allows data scientists to easily leverage massive amounts of GPU computing with confidence, focusing on their projects instead of hunting down GPU resources!
Run:ai’s easy-to-use interface allows IT to view and monitor resource provisions, job queues, and utilization percentages in a centralized and highly transparent UI. A transparent view of resources can also justify adding additional GPU clusters. Data scientists and IT can easily quantify their projects, their usage, and how more GPUs can improve their workflow.
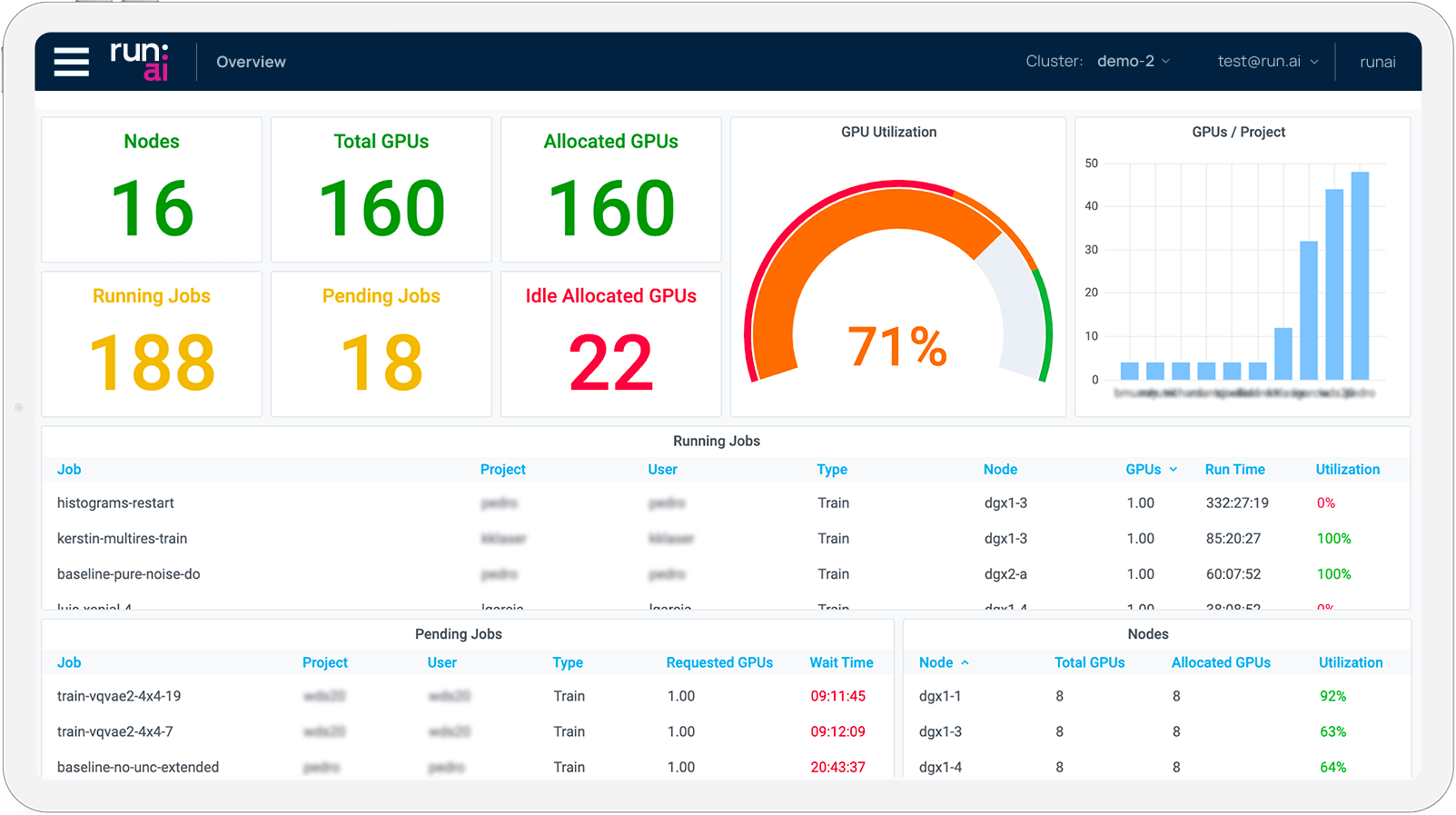
Since Run:ai is built on top of Kubernetes, popular AI frameworks and MLOps Tools are all built-in and supported from the get-go: TensorFlow, PyTorch, Jupyter, NVIDIA NGC, NVIDIA Triton, KubeFlow, and more. This makes adopting Run:ai simple.
Clusters that utilized Run:ai’s impressive scheduler and UI were able to increase their utilization from 20% to 80% within months. With such drastic improvements, the Cluster decided to increase the number of their GPUs to achieve and develop more.
Run:ai is structured into 3 Layers where GPUs can be allocated to each:
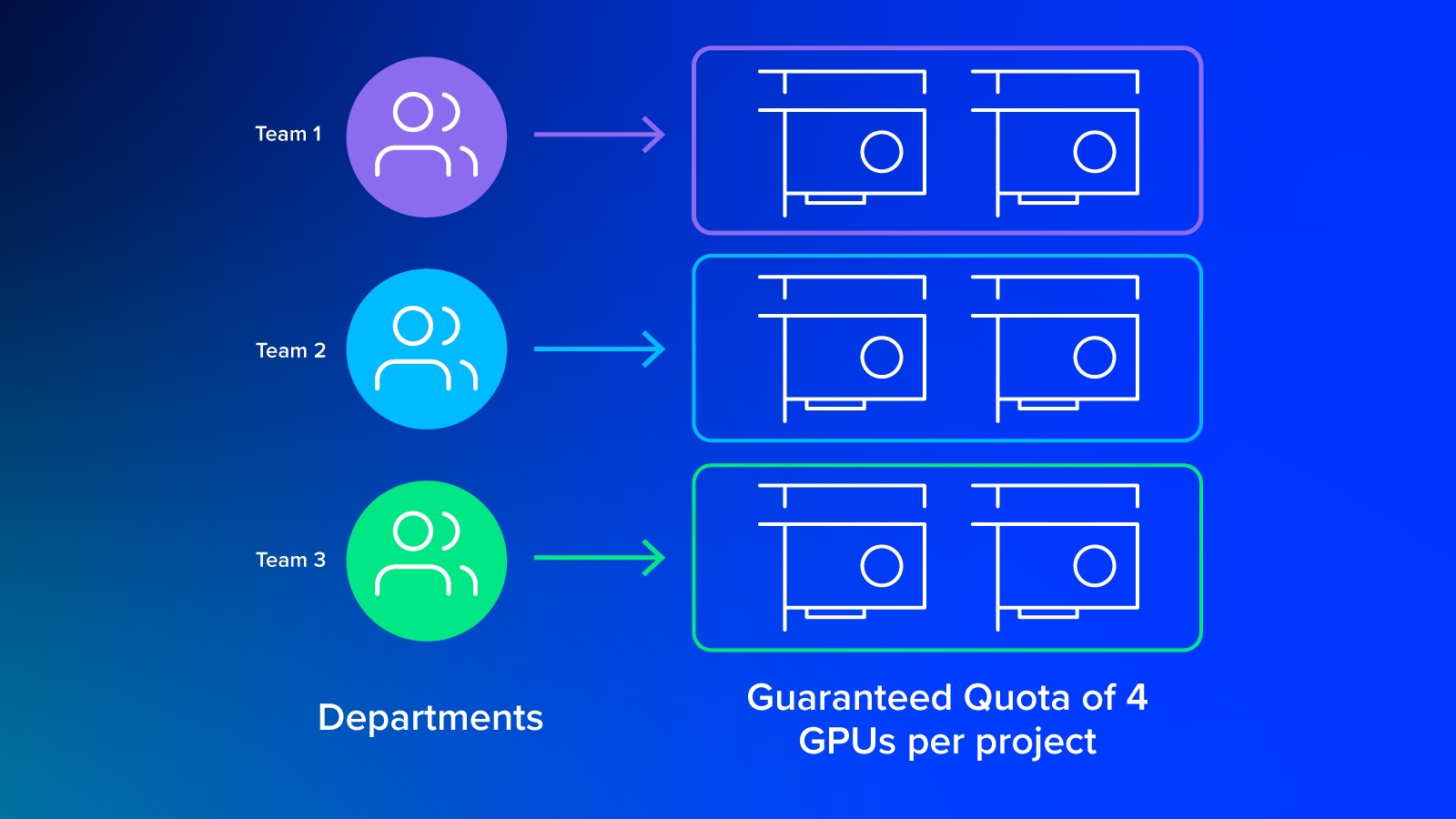
A department can have 10 GPUs allocated, from which the projects within this department can draw from. Jobs within each project can request GPUs as their quota. Over-quota GPUs aren’t tied to a department and can be allocated from other departments/projects/jobs.
When submitting a job through the UI, scientists will designate, build, train, or inference, all of which have set priorities and different start-stop properties. It also makes sure that jobs are queued sequentially. IT can define parameters for Train jobs to have precedent over inference jobs and build jobs.
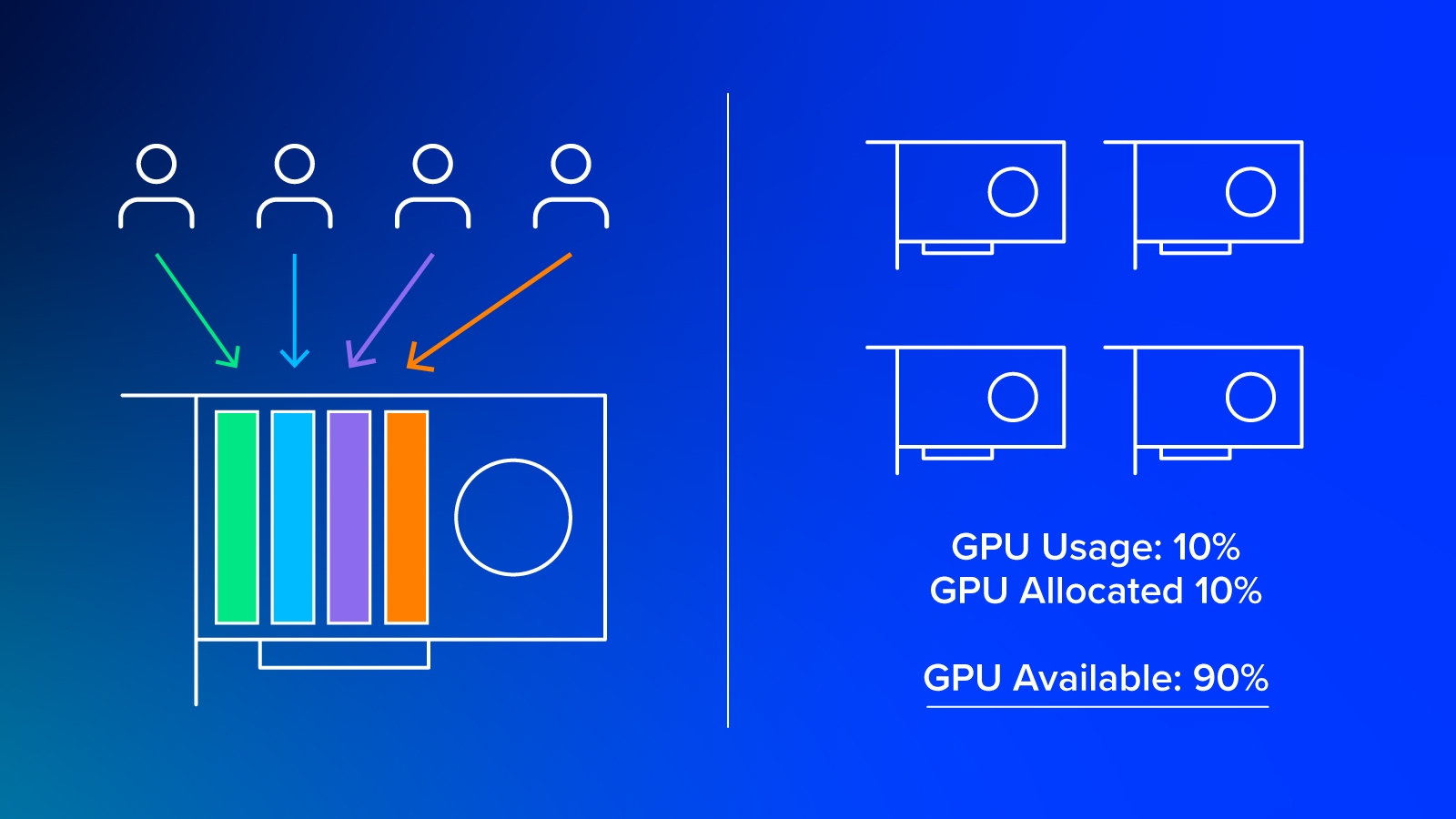
As established, static allocation is very poor for optimal utilization: if we have 10 data scientists with build jobs, we have to allocate 10 GPUs, one for each scientist. However, with Fractional GPUs, we can have all 10 data scientists on a single GPU with 9 GPUs of available resources.
Similar to NVIDIA A100’s MIG capability (multi-instance-GPU) where a GPU can be partitioned for up to 7 simultaneous users, Run:ai is also able to split a GPU among multiple uses. Since Run:ai is software-based, you are able to house an unlimited amount of users on a single GPU (with or without MIG compatible GPUs).
GPUs are expensive components, so making sure that each GPU is being used to its fullest potential makes the most sense. That means that in our 10 data science scenarios, you could save up to 10X the cost, just by utilizing fractional GPUs.
These GPUs can also be used for inferencing and deploying to edge devices such as cameras for vision models or data collection for NLPs. Multiple models can run on a single GPU to compare performance, or a completed model can utilize the same GPU for separate tasks. Instead of allocating static GPUs to each task, the operation can be modular for higher customizability and better utilization.
With all these extra resources, Run:ai’s defining feature is the dynamic fairness scheduling with their GPU Quota System.
Each submitted job allows the user to select their GPU quota. A GPU quota is the amount of guaranteed GPUs you will have as a baseline for your job. If there are more resources available that are not in use, then they will be allocated to your job (based on your workload). When different jobs requiring GPUs are started, your over-quota resources are automatically and dynamically reallocated accordingly. This means that all the GPUs in a cluster, in theory, are utilized at all times.
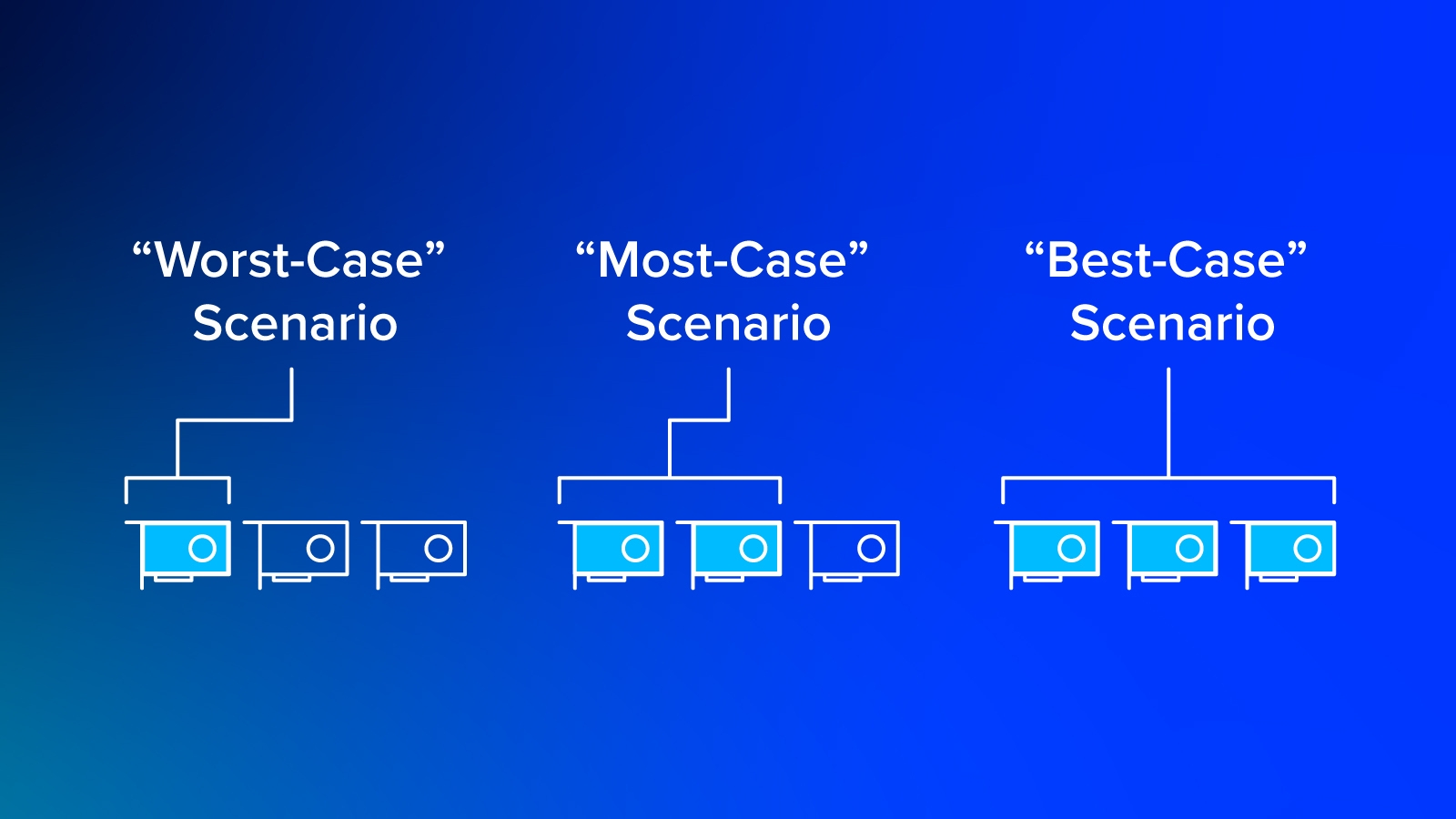
Here are the 3 scenarios that can play out when using Run:ai. This Department has 8 GPUs in total:
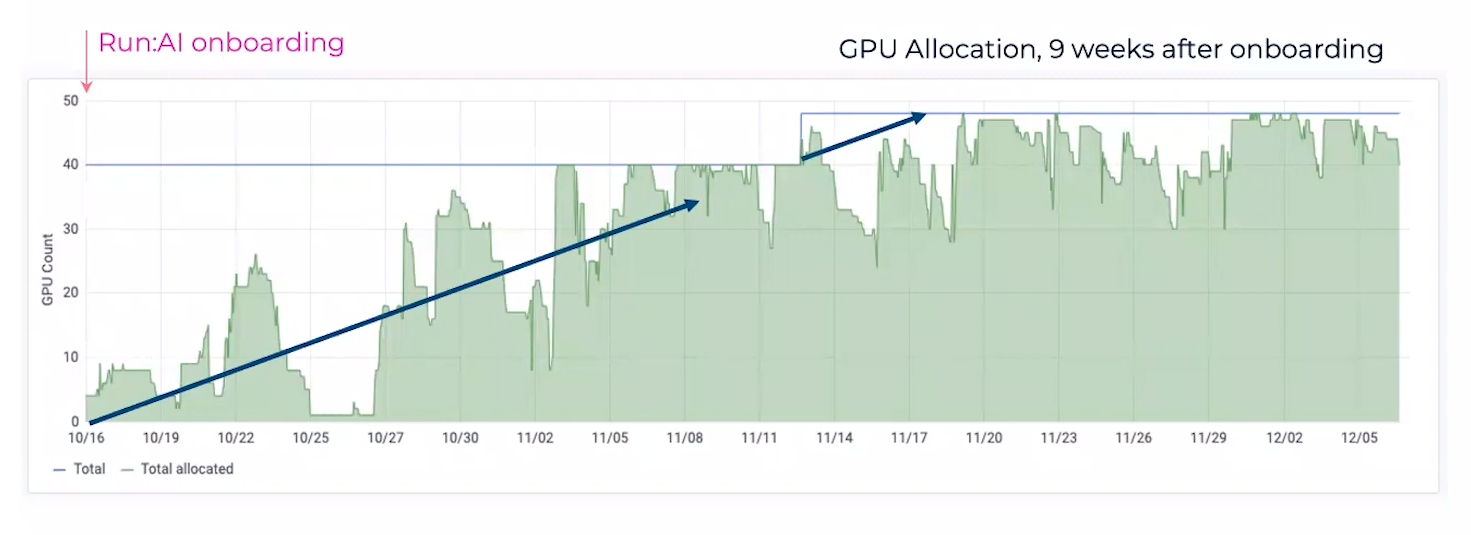
Take a look at one of Run:ai’s adopters. The blue line at the top represents their total number of GPUs; this infrastructure has 40 GPUs. Before implementation, they are averaging about 20% of their resources, never even nearing their peak at all. After about a month of using Run:ai, their utilization shot up to a near 100% optimization, massive improvements!
With Run:ai, this cluster was able to see that 100% utilization was actually some bottlenecks at the 11/06 mark… additional GPUs would be beneficial to their workloads! With a visualization chart just like this, they were able to justify a purchase of a new 8 GPU node. Their utilization now hovers the sweet spot around the 80-90% utilization mark, extremely very impressive improvements and little to no GPU resource wasted.
Data scientists can focus more on their training and development while IT can be a little more hands-free. Jobs can be queued, started, preempted, resumed, and everything else with less intervention.
Almost always you will be getting more “GPUs than you request. And you’re guaranteed to have more GPU utilization than before. With the added Run:ai promises up to 80% utilization from a cluster. That’s 4x more utilization than the average cluster. With more utilization comes faster time to innovation. With better orchestration and management, companies using Run:ai were able to cut down project completion time from 46 days to less than 2 days – a massive 3000% improvement.

Workloads don’t need to run based on capacity and resources but based on the needs of their users. If the infrastructure has it, it will be distributed automatically. As enterprises and companies move towards cloud-native applications for AI workloads, Run:ai provides the best management tool, orchestration tool, and scheduling tool. Exxact Corporation has partnered with Run:ai to provide HPC solutions compatible with their orchestration tool. We are as excited as you are, delivering HPC systems for you to develop innovative solutions to the world’s most complex problems.
Have any Questions?
Contact Exxact Today!
It’s almost inevitable that any GPU cluster has unused hardware. In fact, many data scientists lack the understanding of GPU utilization in their clusters, many of which believe that they have 50 - 60% of their hardware being utilized at any given time.
Run:ai surveyed data scientists' GPU usage and found an overwhelming majority never having over 25% GPU utilization! Your most expensive investments are just sitting idle doing nothing, while projects continued to be back up and bottlenecked.
They posted this same command on GitHub called rntop (pronounced run top) that shows your cluster’s GPU usage across a connected infrastructure. Similar to how nvidia smi shows the GPU utilization on one bare metal solution, rntop can view all GPU nodes in a cluster.
You can find rntop here posted on GitHub by Run:ai’s team!
It hurts to hear that your precious investments in your AI Cluster are being wasted, just sitting idle while your jobs are being bottlenecked and backed up. How can your extremely fast and expensive hardware possibly be so slow?
GPU resources are static, bound to their bare metal system. I have GPUs in my workstation, you have GPUs in your workstation, and the server room has a whole bunch of GPUs in its system. However, there is no easy way to know when and where resources are not being utilized. When my workloads don’t require a GPU, my resources aren’t being used to help anybody else… selfish right?
Even in AI infrastructures where GPU resources are “shared” between jobs the allocation is static in which GPUs are assigned to jobs from start to finish. When server racks of GPUs finish jobs, they go cold until a new job is assigned to them. AI workloads are sometimes sequential, with jobs pending and constant start stops when testing, validating, building, and deploying, it becomes difficult to keep up and reach higher utilization.
For AI workloads, the amount of required computing fluctuates; our static allocation of GPUs hinders flexibility, scalability, and visibility. And when GPUs aren’t in use they should be used elsewhere to accelerate whatever is being built, trained, or deployed.
Founders Omri Geller and Dr. Ronen Dar founded Run:ai. Run:ai is a cloud-native Kubernetes-based orchestration tool that enables data scientists to accelerate, innovate, and complete AI initiatives faster. Reach peak utilization and efficiency by incorporating an AI-dedicated, high-performant super-scheduler tailored for managing NVIDIA CUDA-enable GPU resources. The platform provides IT and MLOps with visibility and control over job scheduling and dynamic GPU resource provisioning.
Kubernetes is the de facto standard for cloud-native scheduling but they are built for microservices and short instances, not multiple large sequential jobs queued together. Kubernetes lack the critical high-performance scheduling needed for AI workloads like batch scheduling, preemption (start, stop, pause, resume), and smart queuing. Because AI workloads are long formats of jobs (build, train, inference) Kubernetes need a lot more reorganization and autonomy to handle such a complex workload.
The Team at Run:ai builds upon Kubernetes to develop to ultimate AI workload orchestration by incorporating:
Run:ai creates a virtualization and acceleration layer over disaggregated GPU resources for granular scheduling, prioritization, and computing power allocation. Their orchestration tool has helped researchers consume resources to their fullest potential by dynamically optimizing hardware utilization for AI workloads. Enabling clusters to operate at peak efficiency allows data scientists to easily leverage massive amounts of GPU computing with confidence, focusing on their projects instead of hunting down GPU resources!
Run:ai’s easy-to-use interface allows IT to view and monitor resource provisions, job queues, and utilization percentages in a centralized and highly transparent UI. A transparent view of resources can also justify adding additional GPU clusters. Data scientists and IT can easily quantify their projects, their usage, and how more GPUs can improve their workflow.
Since Run:ai is built on top of Kubernetes, popular AI frameworks and MLOps Tools are all built-in and supported from the get-go: TensorFlow, PyTorch, Jupyter, NVIDIA NGC, NVIDIA Triton, KubeFlow, and more. This makes adopting Run:ai simple.
Clusters that utilized Run:ai’s impressive scheduler and UI were able to increase their utilization from 20% to 80% within months. With such drastic improvements, the Cluster decided to increase the number of their GPUs to achieve and develop more.
Run:ai is structured into 3 Layers where GPUs can be allocated to each:
A department can have 10 GPUs allocated, from which the projects within this department can draw from. Jobs within each project can request GPUs as their quota. Over-quota GPUs aren’t tied to a department and can be allocated from other departments/projects/jobs.
When submitting a job through the UI, scientists will designate, build, train, or inference, all of which have set priorities and different start-stop properties. It also makes sure that jobs are queued sequentially. IT can define parameters for Train jobs to have precedent over inference jobs and build jobs.
As established, static allocation is very poor for optimal utilization: if we have 10 data scientists with build jobs, we have to allocate 10 GPUs, one for each scientist. However, with Fractional GPUs, we can have all 10 data scientists on a single GPU with 9 GPUs of available resources.
Similar to NVIDIA A100’s MIG capability (multi-instance-GPU) where a GPU can be partitioned for up to 7 simultaneous users, Run:ai is also able to split a GPU among multiple uses. Since Run:ai is software-based, you are able to house an unlimited amount of users on a single GPU (with or without MIG compatible GPUs).
GPUs are expensive components, so making sure that each GPU is being used to its fullest potential makes the most sense. That means that in our 10 data science scenarios, you could save up to 10X the cost, just by utilizing fractional GPUs.
These GPUs can also be used for inferencing and deploying to edge devices such as cameras for vision models or data collection for NLPs. Multiple models can run on a single GPU to compare performance, or a completed model can utilize the same GPU for separate tasks. Instead of allocating static GPUs to each task, the operation can be modular for higher customizability and better utilization.
With all these extra resources, Run:ai’s defining feature is the dynamic fairness scheduling with their GPU Quota System.
Each submitted job allows the user to select their GPU quota. A GPU quota is the amount of guaranteed GPUs you will have as a baseline for your job. If there are more resources available that are not in use, then they will be allocated to your job (based on your workload). When different jobs requiring GPUs are started, your over-quota resources are automatically and dynamically reallocated accordingly. This means that all the GPUs in a cluster, in theory, are utilized at all times.
Here are the 3 scenarios that can play out when using Run:ai. This Department has 8 GPUs in total:
Take a look at one of Run:ai’s adopters. The blue line at the top represents their total number of GPUs; this infrastructure has 40 GPUs. Before implementation, they are averaging about 20% of their resources, never even nearing their peak at all. After about a month of using Run:ai, their utilization shot up to a near 100% optimization, massive improvements!
With Run:ai, this cluster was able to see that 100% utilization was actually some bottlenecks at the 11/06 mark… additional GPUs would be beneficial to their workloads! With a visualization chart just like this, they were able to justify a purchase of a new 8 GPU node. Their utilization now hovers the sweet spot around the 80-90% utilization mark, extremely very impressive improvements and little to no GPU resource wasted.
Data scientists can focus more on their training and development while IT can be a little more hands-free. Jobs can be queued, started, preempted, resumed, and everything else with less intervention.
Almost always you will be getting more “GPUs than you request. And you’re guaranteed to have more GPU utilization than before. With the added Run:ai promises up to 80% utilization from a cluster. That’s 4x more utilization than the average cluster. With more utilization comes faster time to innovation. With better orchestration and management, companies using Run:ai were able to cut down project completion time from 46 days to less than 2 days – a massive 3000% improvement.
Workloads don’t need to run based on capacity and resources but based on the needs of their users. If the infrastructure has it, it will be distributed automatically. As enterprises and companies move towards cloud-native applications for AI workloads, Run:ai provides the best management tool, orchestration tool, and scheduling tool. Exxact Corporation has partnered with Run:ai to provide HPC solutions compatible with their orchestration tool. We are as excited as you are, delivering HPC systems for you to develop innovative solutions to the world’s most complex problems.
Have any Questions?
Contact Exxact Today!
