Artificial Intelligence
Megatron Unleashed: NVIDIA's NLP Model "Megatron-LM" is the Largest Transformer Ever Trained
August 13, 2019
4 min read


If you've followed the latest advancements in Natural Language Processing (NLP), you'll know that Transformer Models are all the latest craze. These language models are currently the state of the art for many tasks including article completion, question answering, and dialog systems. The two famous transformers that come to mind are BERT, and the infamous GPT-2, which demonstrated such architectures. Having said that, it was only a matter of time before NVIDIA researchers pushed the limits of the technology, enter Megatron-LM.
[caption id="attachment_4513" align="aligncenter" width="796"]
'Megatron' as depicted in the popular 80's cartoon series 'The Transformers'[/caption]
Megatron is a 8.3 billion parameter transformer language model with 8-way model parallelism and 64-way data parallelism trained on 512 GPUs (NVIDIA Tesla V100), making it the largest transformer model ever trained. Furthermore, when we look at the numbers it's 24x the size of BERT and 5.6x the size of GPT-2.
Training these massive transformer models requires massive compute and clever memory management. Single GPU memory is typically not enough to fit the model along with the necessary parameters needed for training. Large transformers such as MegatronLM yearn for model parallelism to split the parameters across multiple GPUs. While, several approaches to model parallelism do exist, they are often extremely difficult to use. NVIDIA solves this in a novel way that does not require any new compiler or code re-wiring and can be fully implemented with insertion of few simple primitives (f and g operators in the figure below).
[caption id="attachment_4498" align="aligncenter" width="968"]
(a): MLP and (b): self attention blocks of transformer. f and g are conjugate, f is an identity operator in the forward pass and all-reduce in the backward pass while g is an all-reduce in forward and identity in backward. (Source: NVIDIA).[/caption]
To train Megatron's GPT-2 model NVIDIA created a 37 GB WebText dataset downloaded from Reddit that is similar to the the original GPT-2 paper. They then proceeded with the following:
Note: 345 and 775 million parameter models are similar to the ones used in GPT-2, and use 16 attention heads.
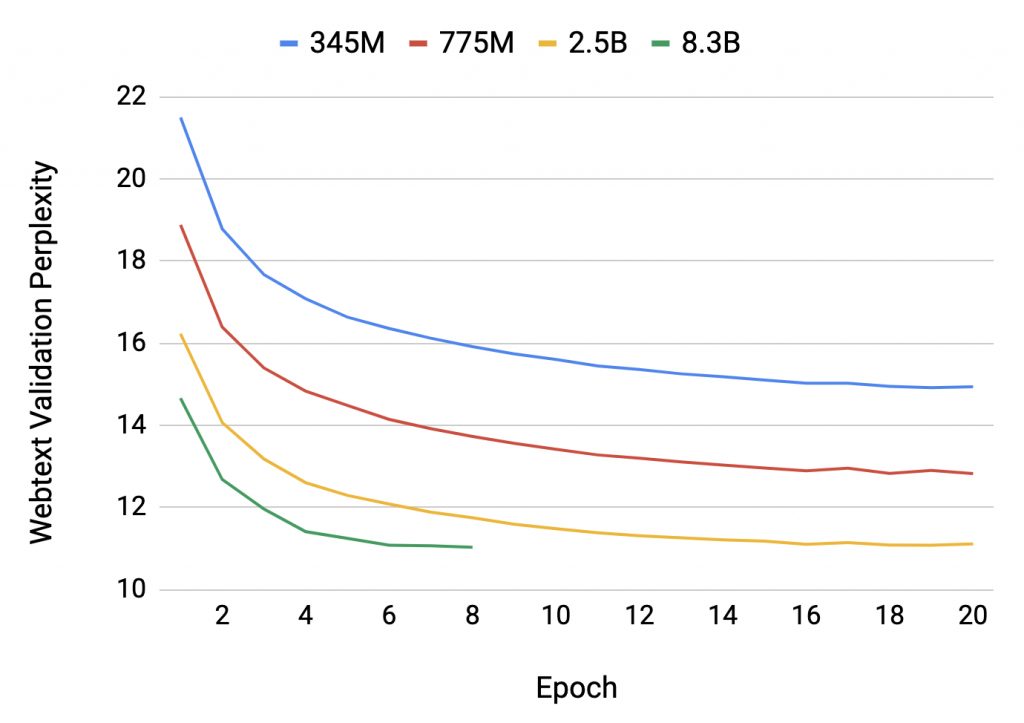
Validation perplexity over a subset of training. The 8.3B model is stopped early after overfitting on our 37GB dataset. (Source NVIDIA)
[caption id="attachment_4502" align="aligncenter" width="1024"]
Zero-shot evaluation results for wikitext perplexity (lower is better) and Lambada accuracy (higher is better). Wikitext perplexity surpasses previous state of the art results (18.3) set by transformer-xl. (Source: NVIDIA)[/caption]

If you've followed the latest advancements in Natural Language Processing (NLP), you'll know that Transformer Models are all the latest craze. These language models are currently the state of the art for many tasks including article completion, question answering, and dialog systems. The two famous transformers that come to mind are BERT, and the infamous GPT-2, which demonstrated such architectures. Having said that, it was only a matter of time before NVIDIA researchers pushed the limits of the technology, enter Megatron-LM.
[caption id="attachment_4513" align="aligncenter" width="796"]
'Megatron' as depicted in the popular 80's cartoon series 'The Transformers'[/caption]
Megatron is a 8.3 billion parameter transformer language model with 8-way model parallelism and 64-way data parallelism trained on 512 GPUs (NVIDIA Tesla V100), making it the largest transformer model ever trained. Furthermore, when we look at the numbers it's 24x the size of BERT and 5.6x the size of GPT-2.
Training these massive transformer models requires massive compute and clever memory management. Single GPU memory is typically not enough to fit the model along with the necessary parameters needed for training. Large transformers such as MegatronLM yearn for model parallelism to split the parameters across multiple GPUs. While, several approaches to model parallelism do exist, they are often extremely difficult to use. NVIDIA solves this in a novel way that does not require any new compiler or code re-wiring and can be fully implemented with insertion of few simple primitives (f and g operators in the figure below).
[caption id="attachment_4498" align="aligncenter" width="968"]
(a): MLP and (b): self attention blocks of transformer. f and g are conjugate, f is an identity operator in the forward pass and all-reduce in the backward pass while g is an all-reduce in forward and identity in backward. (Source: NVIDIA).[/caption]
To train Megatron's GPT-2 model NVIDIA created a 37 GB WebText dataset downloaded from Reddit that is similar to the the original GPT-2 paper. They then proceeded with the following:
Note: 345 and 775 million parameter models are similar to the ones used in GPT-2, and use 16 attention heads.
Validation perplexity over a subset of training. The 8.3B model is stopped early after overfitting on our 37GB dataset. (Source NVIDIA)
[caption id="attachment_4502" align="aligncenter" width="1024"]
Zero-shot evaluation results for wikitext perplexity (lower is better) and Lambada accuracy (higher is better). Wikitext perplexity surpasses previous state of the art results (18.3) set by transformer-xl. (Source: NVIDIA)[/caption]
