Artificial Intelligence
How to Create a Dataset for Machine Learning
February 15, 2022
13 min read


Something extraordinary is happening.
The entry barrier to the world of algorithms is getting lower by the day. That means anybody with the right goal and skills can find out great algorithms for Machine Learning (ML) and Artificial Intelligence (AI) tasks - computer vision, natural language processing, recommendation systems, or even autonomous driving.
Open-source computing has come a long way and plenty of open-source initiatives are propelling the vehicles of data science, digital analytics, and ML. Researchers around the universities and corporate R&D labs are creating new algorithms and ML techniques every day. We can safely say that algorithms, programming frameworks, ML packages, and even tutorials and courses on how to learn these techniques are no longer scarce resources.
But high-quality data is. Datasets - properly curated and labeled - remain a scarce resource.
Fig 1: Too many algorithms but hardly a good dataset
Interested in an AI workstation?
Accelerate your machine learning research with a purpose-built Exxact solution.
Often, it is not a discussion about how to get high-quality data for the cool AI-powered travel or fashion app you are working on. That kind of consumer, social, or behavioral data collection presents its own issues.
Every application field has its own challenge to get the suitable data that it needs for training high-performance ML models. For example, LiDAR for autonomous vehicles needs a special 3D point cloud dataset for object identification and semantic segmentation, that is extremely difficult to hand label.

Fig 2: A LiDAR 3D point cloud dataset - extremely hard to hand-label for training. Image sourced from this paper
However, even having access to quality datasets for basic ML algorithm testing and ideation is a challenge. Let's say an ML engineer is learning from scratch. The sanest advice would be to start with simple, small-scale datasets which he/she can plot in two dimensions to understand the patterns visually and see the inner workings of the ML algorithm in an intuitive fashion. As the dimensions of the data explode, however, the visual judgment must extend to more complicated matters - concepts like learning and sample complexity, computational efficiency, class imbalance, etc.
Fig 3: Data and ML model exploration begins simple - then explodes. Dataset must evolve too.
One can always find a real-life dataset or generate data points by experimenting in order to evaluate and fine-tune an ML algorithm. However, with a fixed dataset, there is a fixed number of samples, a fixed underlying pattern, and a fixed degree of class separation between positive and negative samples. There are many aspects of an ML algorithm that one cannot test or evaluate with such a fixed dataset. Here are some examples:
Synthetic datasets come to the rescue in all these situations. Synthetic data is information that's artificially manufactured rather than generated by real-world events. This type of data is best for simple validation of a model but is used to help train as well. The potential benefit of such synthetic datasets can easily be gauged for sensitive applications - medical classifications or financial modeling, where getting hands on a high-quality labeled dataset is often expensive and prohibitive.
While a synthetic dataset is generated programmatically, real-life datasets are curated from all kinds of sources - social or scientific experiments, medical treatment history, business transactional data, web browsing activities, sensor reading, or manual labeling of images taken by automated cameras or LiDAR. No matter the source, there are always some desirable features for a dataset to be valuable for ML algorithm development and performance tuning.
Here are some examples,
Scikit-learn is the most popular ML library in the Python-based software stack for data science. Apart from the well-optimized ML routines and pipeline building methods, it also boasts a solid collection of utility methods for synthetic data generation. We can create a wide variety of datasets for regular ML algorithm training and tuning.
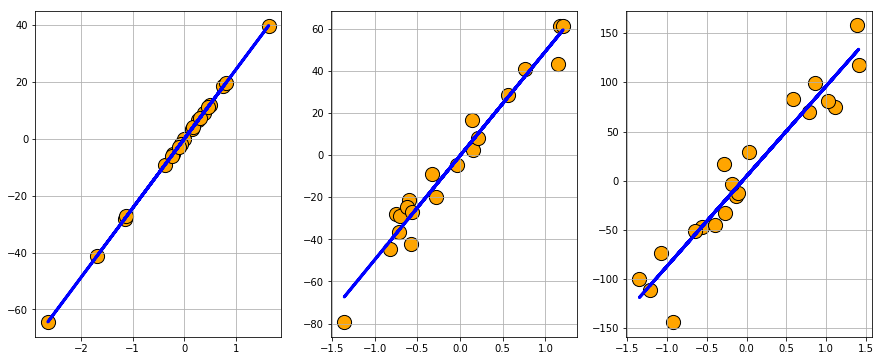
Fig 4: Regression datasets created using Scikit-learn.
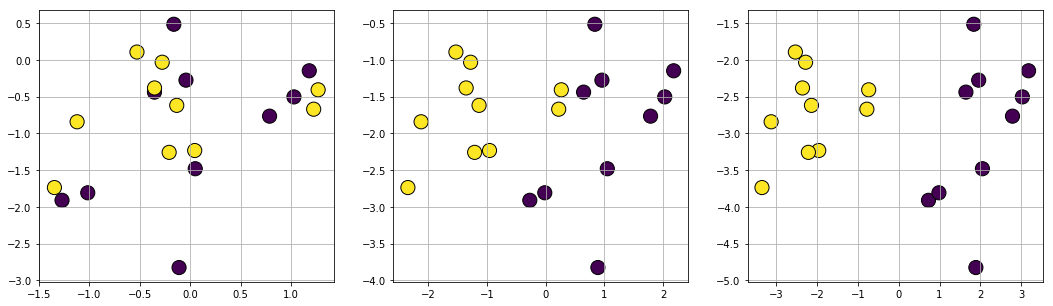
Fig 5: Classification datasets created using Scikit-learn.
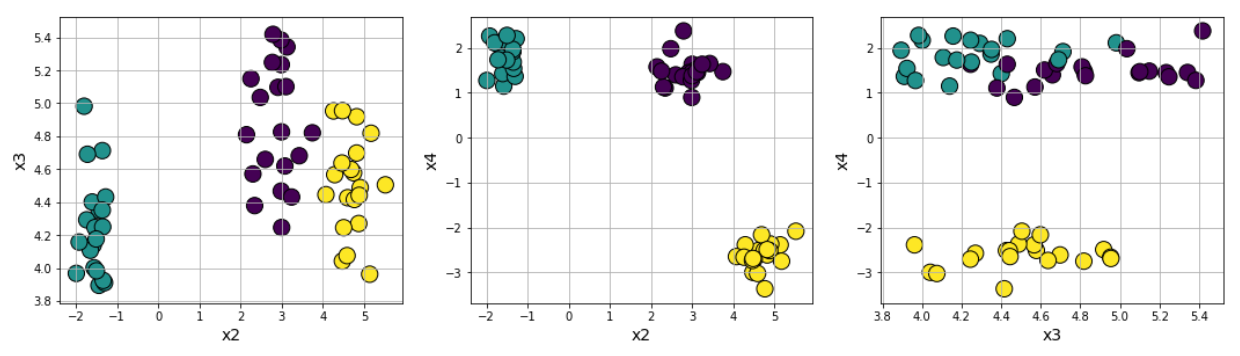
Fig 6: Clustering datasets created using Scikit-learn.
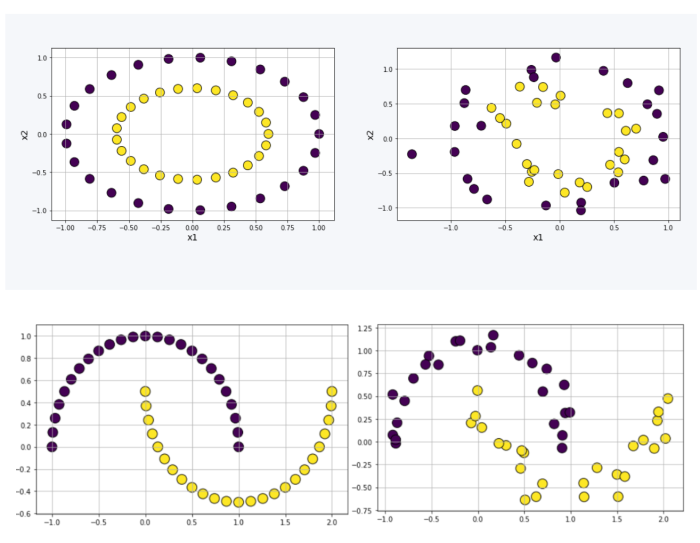
Fig 7: Non-linear datasets for testing kernel-based algorithms.
Gaussian mixture models (GMM) are fascinating objects to study. They are used heavily in the field of unsupervised learning and topic modeling for massive text processing/NLP tasks. Even autonomous driving and robotic navigation algorithms have many uses for them. With a minimal amount of code, one can create interesting datasets mimicking the GMM process of arbitrary shape and complexity.
Here are some synthetic data examples of the same:
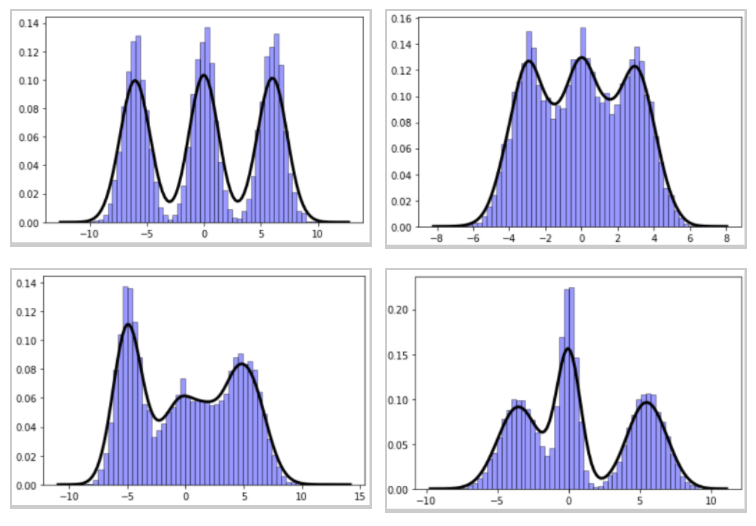
Fig 8: Gaussian mixture model datasets created synthetically.
Often, one may require a controllable way to generate ML datasets based on a well-defined function (involving linear, nonlinear, rational, or even transcendental terms).
For example, you may want to evaluate the efficacy of the various kernelized SVM classifiers on datasets with increasingly complex separators (linear to non-linear) or want to demonstrate the limitation of linear models for datasets generated by rational or transcendental functions. By mixing the power of random variate generation and symbolic expression manipulation libraries like SymPy, you can create interesting datasets corresponding to user-defined functions.
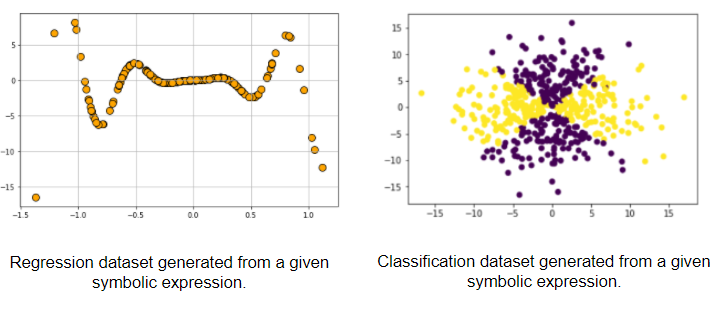
Fig 9: Symbolic function generated datasets for advanced ML algorithm testing.
Time-series analysis has many rich applications in modern industrial settings where a multitude of sensors are creating a never-ending stream of digital data from machines, factories, operators, and business processes. Such digital exhaust is the core feature of the Industry 4.0 revolution.
Anomaly detection in these data streams is the bread and butter of all modern data analytics products, services, and startups. They are employing everything from tried and tested time-series algorithms to the latest neural-network-based sequence models. However, for in-house testing of these algorithms, sometimes it is necessary to create synthetic datasets mimicking the anomalies of various natures in a time series.
This article goes deep into this idea and shows some examples: Create synthetic time-series with anomaly signatures in Python.
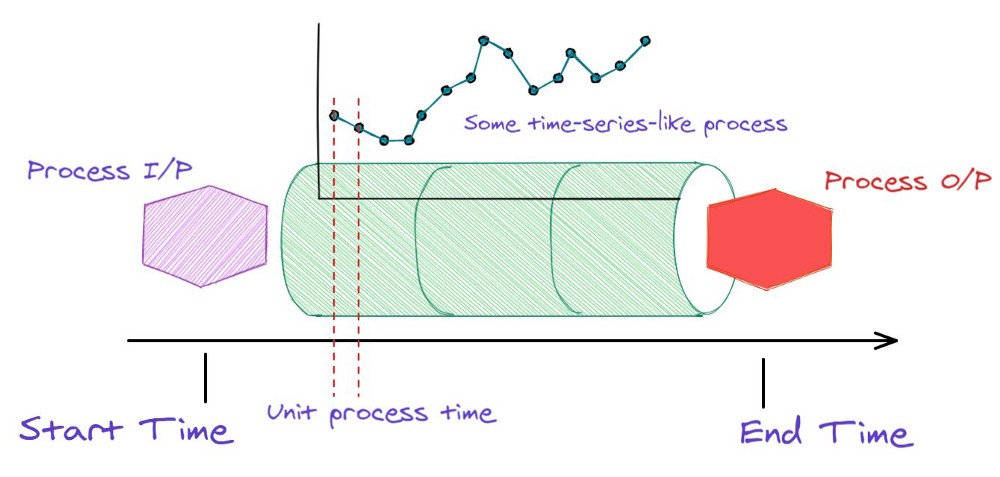
Fig 10: Core generative process for time-series datasets in industrial applications.
One can generate anomalies of various scales,
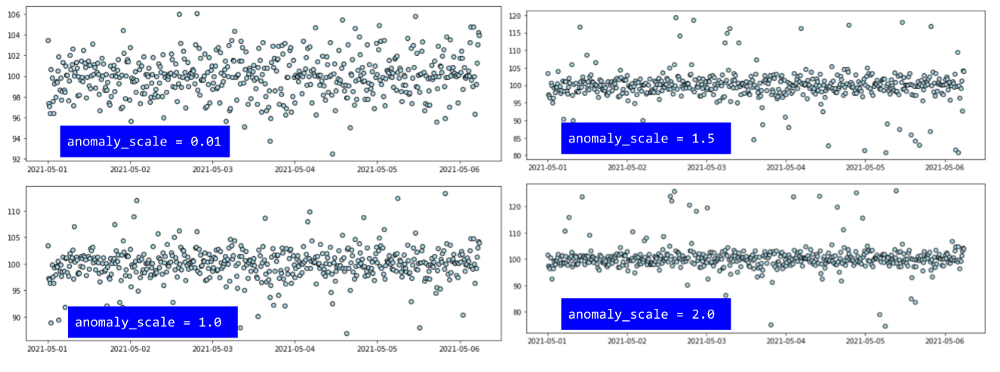
Fig 11: Time-series with anomalies of various scales.
Data drift may occur in any direction with any scale. Data may change one or more of its statistical properties - mean or variance, for example. This should also be modeled and used for dataset generation.
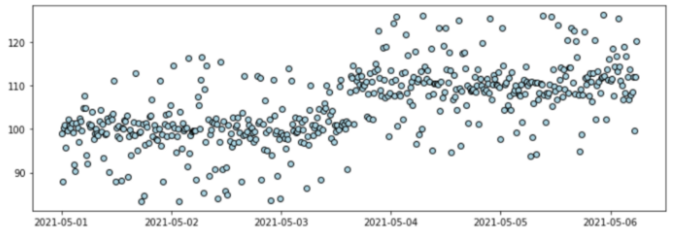
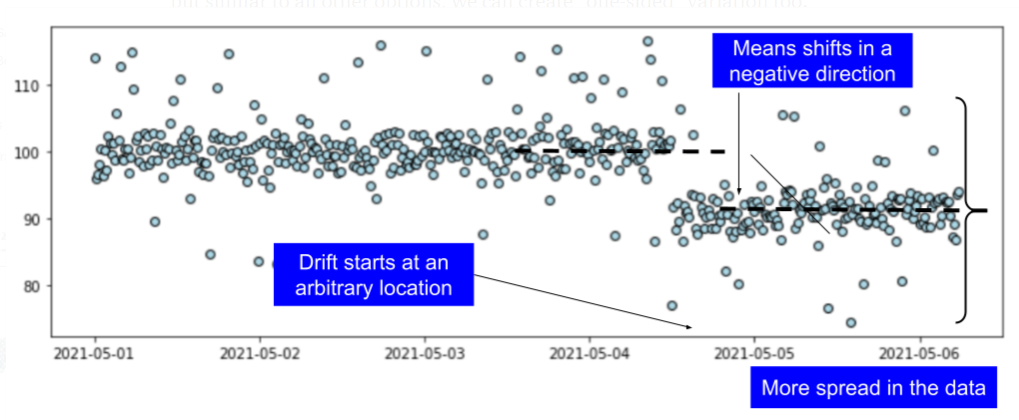
Fig 12: Time-series datasets with anomalies and data drift combined.
There are many good image datasets already for basic deep-learning model training and tuning. However, for specific tasks or application areas, ML engineers often need to start with a relatively small set of good-quality images and augment them using clever image processing techniques.
Here is a blog discussing at length the data augmentation tricks with image data as examples:
Basically, image datasets of various depths and complexity can be created from some seed, high-quality images using augmentation techniques:
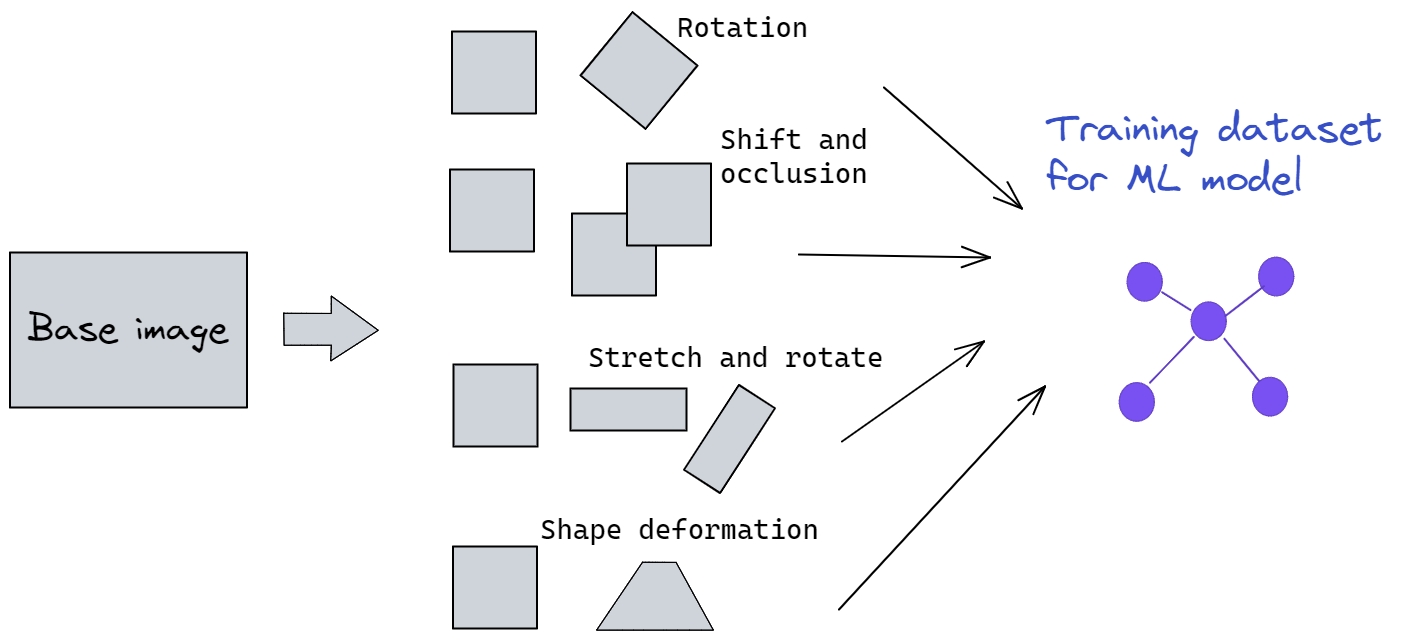
Fig 13: Image data augmentation for creating rich and robust datasets for deep learning training.
One can also experiment with various noise channel additions to augment the dataset so that the ML model performs well in noisy situations.

Fig 14: Image data augmentation with various noise channel additions.
In this article, we went over the essential motivations behind creating high-quality machine learning datasets and some desirable properties for such data. Business processes and scientific experiments, medical and social media history - these are, and, will remain the most trusted source for training ML algorithms with real-life data.
However, synthetic datasets are increasingly in demand for the power and flexibility they lend for evaluating and optimizing ML algorithms.
We briefly touched upon a lot of tools, frameworks, and techniques that are being used to generate such datasets for ML and how they can be precisely tailored to the needs of algorithm development. This field will continue to grow in importance and can aid in the development and flourishing of new and exciting ML algorithms, frameworks, and techniques.
Have any questions?
Contact Exxact Today
Something extraordinary is happening.
The entry barrier to the world of algorithms is getting lower by the day. That means anybody with the right goal and skills can find out great algorithms for Machine Learning (ML) and Artificial Intelligence (AI) tasks - computer vision, natural language processing, recommendation systems, or even autonomous driving.
Open-source computing has come a long way and plenty of open-source initiatives are propelling the vehicles of data science, digital analytics, and ML. Researchers around the universities and corporate R&D labs are creating new algorithms and ML techniques every day. We can safely say that algorithms, programming frameworks, ML packages, and even tutorials and courses on how to learn these techniques are no longer scarce resources.
But high-quality data is. Datasets - properly curated and labeled - remain a scarce resource.
Fig 1: Too many algorithms but hardly a good dataset
Interested in an AI workstation?
Accelerate your machine learning research with a purpose-built Exxact solution.
Often, it is not a discussion about how to get high-quality data for the cool AI-powered travel or fashion app you are working on. That kind of consumer, social, or behavioral data collection presents its own issues.
Every application field has its own challenge to get the suitable data that it needs for training high-performance ML models. For example, LiDAR for autonomous vehicles needs a special 3D point cloud dataset for object identification and semantic segmentation, that is extremely difficult to hand label.
Fig 2: A LiDAR 3D point cloud dataset - extremely hard to hand-label for training. Image sourced from this paper
However, even having access to quality datasets for basic ML algorithm testing and ideation is a challenge. Let's say an ML engineer is learning from scratch. The sanest advice would be to start with simple, small-scale datasets which he/she can plot in two dimensions to understand the patterns visually and see the inner workings of the ML algorithm in an intuitive fashion. As the dimensions of the data explode, however, the visual judgment must extend to more complicated matters - concepts like learning and sample complexity, computational efficiency, class imbalance, etc.
Fig 3: Data and ML model exploration begins simple - then explodes. Dataset must evolve too.
One can always find a real-life dataset or generate data points by experimenting in order to evaluate and fine-tune an ML algorithm. However, with a fixed dataset, there is a fixed number of samples, a fixed underlying pattern, and a fixed degree of class separation between positive and negative samples. There are many aspects of an ML algorithm that one cannot test or evaluate with such a fixed dataset. Here are some examples:
Synthetic datasets come to the rescue in all these situations. Synthetic data is information that's artificially manufactured rather than generated by real-world events. This type of data is best for simple validation of a model but is used to help train as well. The potential benefit of such synthetic datasets can easily be gauged for sensitive applications - medical classifications or financial modeling, where getting hands on a high-quality labeled dataset is often expensive and prohibitive.
While a synthetic dataset is generated programmatically, real-life datasets are curated from all kinds of sources - social or scientific experiments, medical treatment history, business transactional data, web browsing activities, sensor reading, or manual labeling of images taken by automated cameras or LiDAR. No matter the source, there are always some desirable features for a dataset to be valuable for ML algorithm development and performance tuning.
Here are some examples,
Scikit-learn is the most popular ML library in the Python-based software stack for data science. Apart from the well-optimized ML routines and pipeline building methods, it also boasts a solid collection of utility methods for synthetic data generation. We can create a wide variety of datasets for regular ML algorithm training and tuning.
Fig 4: Regression datasets created using Scikit-learn.
Fig 5: Classification datasets created using Scikit-learn.
Fig 6: Clustering datasets created using Scikit-learn.
Fig 7: Non-linear datasets for testing kernel-based algorithms.
Gaussian mixture models (GMM) are fascinating objects to study. They are used heavily in the field of unsupervised learning and topic modeling for massive text processing/NLP tasks. Even autonomous driving and robotic navigation algorithms have many uses for them. With a minimal amount of code, one can create interesting datasets mimicking the GMM process of arbitrary shape and complexity.
Here are some synthetic data examples of the same:
Fig 8: Gaussian mixture model datasets created synthetically.
Often, one may require a controllable way to generate ML datasets based on a well-defined function (involving linear, nonlinear, rational, or even transcendental terms).
For example, you may want to evaluate the efficacy of the various kernelized SVM classifiers on datasets with increasingly complex separators (linear to non-linear) or want to demonstrate the limitation of linear models for datasets generated by rational or transcendental functions. By mixing the power of random variate generation and symbolic expression manipulation libraries like SymPy, you can create interesting datasets corresponding to user-defined functions.
Fig 9: Symbolic function generated datasets for advanced ML algorithm testing.
Time-series analysis has many rich applications in modern industrial settings where a multitude of sensors are creating a never-ending stream of digital data from machines, factories, operators, and business processes. Such digital exhaust is the core feature of the Industry 4.0 revolution.
Anomaly detection in these data streams is the bread and butter of all modern data analytics products, services, and startups. They are employing everything from tried and tested time-series algorithms to the latest neural-network-based sequence models. However, for in-house testing of these algorithms, sometimes it is necessary to create synthetic datasets mimicking the anomalies of various natures in a time series.
This article goes deep into this idea and shows some examples: Create synthetic time-series with anomaly signatures in Python.
Fig 10: Core generative process for time-series datasets in industrial applications.
One can generate anomalies of various scales,
Fig 11: Time-series with anomalies of various scales.
Data drift may occur in any direction with any scale. Data may change one or more of its statistical properties - mean or variance, for example. This should also be modeled and used for dataset generation.
Fig 12: Time-series datasets with anomalies and data drift combined.
There are many good image datasets already for basic deep-learning model training and tuning. However, for specific tasks or application areas, ML engineers often need to start with a relatively small set of good-quality images and augment them using clever image processing techniques.
Here is a blog discussing at length the data augmentation tricks with image data as examples:
Basically, image datasets of various depths and complexity can be created from some seed, high-quality images using augmentation techniques:
Fig 13: Image data augmentation for creating rich and robust datasets for deep learning training.
One can also experiment with various noise channel additions to augment the dataset so that the ML model performs well in noisy situations.
Fig 14: Image data augmentation with various noise channel additions.
In this article, we went over the essential motivations behind creating high-quality machine learning datasets and some desirable properties for such data. Business processes and scientific experiments, medical and social media history - these are, and, will remain the most trusted source for training ML algorithms with real-life data.
However, synthetic datasets are increasingly in demand for the power and flexibility they lend for evaluating and optimizing ML algorithms.
We briefly touched upon a lot of tools, frameworks, and techniques that are being used to generate such datasets for ML and how they can be precisely tailored to the needs of algorithm development. This field will continue to grow in importance and can aid in the development and flourishing of new and exciting ML algorithms, frameworks, and techniques.
Have any questions?
Contact Exxact Today
