Deep Learning
Cloud vs. On-Premises Price Comparison for NVIDIA T4 Inference Servers
July 10, 2019
5 min read

In this post, we do a cost benefit analysis comparing an Exxact Deep Learning Inference Server with leading cloud instance from Google GCP. When deploying deep learning models at scale, using GPUs can gain efficiencies in terms of power and performance over CPUs. When selecting your infrastructure, we've seen that significant savings can be met bringing your deep learning on premises, (see our blog article here) but what about deploying inference models at scale using T4 Inference servers?
Before we go in depth with the analysis, we must look at the NVIDIA T4 GPU. This is the latest server card for deep learning, multi-precision computing for AI powers breakthrough performance from FP32 to FP16 to INT8, as well as INT4 precision. This flexibility in multi-precision performance lends the T4 to be an excellent choice for inference tasks.

Currently Google Colab is offering free access to a T4. Anyone who has a google account, can access the T4 and we'd certainly encourage experimentation with these notebooks. Aside from this obvious gateway into GCP, you should consider On Premises when it comes to price, flexibility and hardware performance.
If your application is scaling, the hardware costs of purchasing an Exxact Inference server makes sense with both performance and price.
| Exxact Deep Learning System | Google Cloud Platform T4 Instance |
|---|---|
| * 2x Intel Xeon Silver 4110 * 4x NVIDIA Tesla T4 * 256GB DDR4 Memory * 2TB SSD | * 2x vCPUs * 4x NVIDIA Tesla T4 * 7.5GB Memory * 750GB SSD |
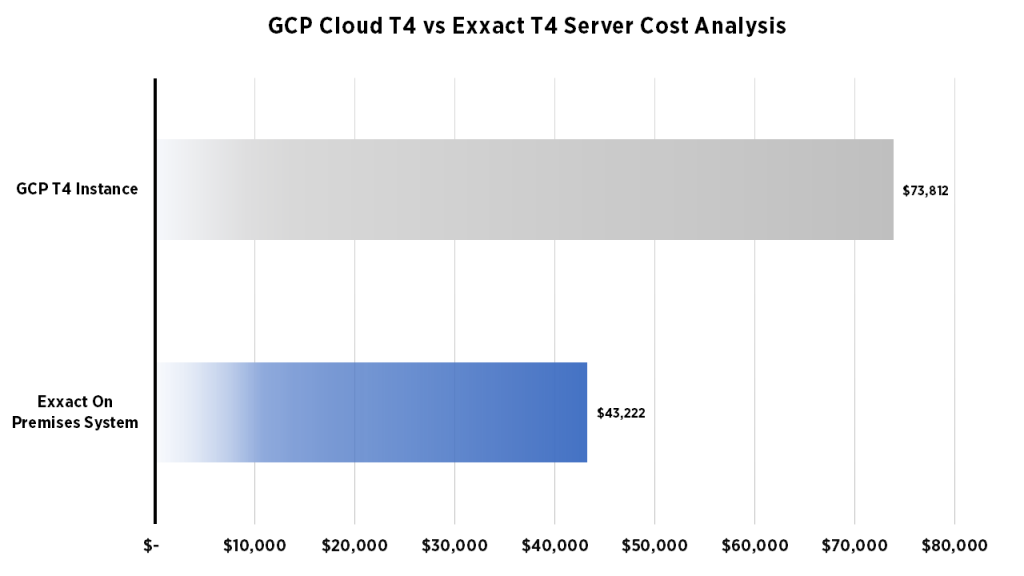
| $43,222* | $73,812** |
| *Cost of use over 3 years. Base price: $17,290. Operating cost: $8,644.50 per year. Operating cost estimated at 1/2 server cost/year. | **Additional costs for bandwidth, storage, Data egress, may vary depending on use. Price based on on-demand instances start at $0.95 per hour per GPU, with up to a 30% discount with sustained use discounts more info from GCP. |
Low Latency Inference
Exxact Deep Learning Inference Solutions boost efficiency of any project looking to scale-out servers running various deep-learning workloads that require responsiveness. Our servers excel at reducing inference latency, and thereby reduces TCO by providing power efficient computation at high performance.
Virtual Workstations
In addition, Exxact T4 powered inference servers provide virtual workstations for teams working on the toughest visualization challenges.
High Throughput Inference
Furthermore, Exxact Deep Learning T4 Inference Servers are optimized for use in image and video search, video analytics, object classification and detection, and a host of other usages.

In this post, we do a cost benefit analysis comparing an Exxact Deep Learning Inference Server with leading cloud instance from Google GCP. When deploying deep learning models at scale, using GPUs can gain efficiencies in terms of power and performance over CPUs. When selecting your infrastructure, we've seen that significant savings can be met bringing your deep learning on premises, (see our blog article here) but what about deploying inference models at scale using T4 Inference servers?
Before we go in depth with the analysis, we must look at the NVIDIA T4 GPU. This is the latest server card for deep learning, multi-precision computing for AI powers breakthrough performance from FP32 to FP16 to INT8, as well as INT4 precision. This flexibility in multi-precision performance lends the T4 to be an excellent choice for inference tasks.
Currently Google Colab is offering free access to a T4. Anyone who has a google account, can access the T4 and we'd certainly encourage experimentation with these notebooks. Aside from this obvious gateway into GCP, you should consider On Premises when it comes to price, flexibility and hardware performance.
If your application is scaling, the hardware costs of purchasing an Exxact Inference server makes sense with both performance and price.
| Exxact Deep Learning System | Google Cloud Platform T4 Instance |
|---|---|
| * 2x Intel Xeon Silver 4110 * 4x NVIDIA Tesla T4 * 256GB DDR4 Memory * 2TB SSD | * 2x vCPUs * 4x NVIDIA Tesla T4 * 7.5GB Memory * 750GB SSD |
| $43,222* | $73,812** |
| *Cost of use over 3 years. Base price: $17,290. Operating cost: $8,644.50 per year. Operating cost estimated at 1/2 server cost/year. | **Additional costs for bandwidth, storage, Data egress, may vary depending on use. Price based on on-demand instances start at $0.95 per hour per GPU, with up to a 30% discount with sustained use discounts more info from GCP. |
Low Latency Inference
Exxact Deep Learning Inference Solutions boost efficiency of any project looking to scale-out servers running various deep-learning workloads that require responsiveness. Our servers excel at reducing inference latency, and thereby reduces TCO by providing power efficient computation at high performance.
Virtual Workstations
In addition, Exxact T4 powered inference servers provide virtual workstations for teams working on the toughest visualization challenges.
High Throughput Inference
Furthermore, Exxact Deep Learning T4 Inference Servers are optimized for use in image and video search, video analytics, object classification and detection, and a host of other usages.
