Artificial Intelligence
NVIDIA CUDA in AI Deep Learning
October 5, 2022
9 min read


Deep learning and AI workloads such as building, training, and inferencing all require an ample amount of computing resources. Many of these workloads can be performed in parallel since deep learning neural networks are “embarrassingly parallel” an actual term used to describe workloads that can be broken up into smaller sub-computations and be performed all at the same time.
GPUs or Graphics Processing Units offer excellent parallelization in workloads and have only in the last decade taken interest in the AI and Deep Learning Industry. Without the incorporation of GPUs, training, building, and deploying deep learning models can span days, weeks, months even… GPUs enable much less time to fully develop an AI.
NVIDIA CUDA is a software platform API that enables parallel computing with GPU hardware making it easier for developers to build software that accelerates tasks by allowing workloads to be distributed across parallelized GPUs.
Using the NVIDIA CUDA Toolkit you can accelerate your C or C++ applications by updating computationally intense portions of your code to run on GPUs. Call functions from drop-in libraries or develop custom applications using languages including C, C++, Fortran, Python, and MATLAB.
Companies from around the world have harnessed the CUDA Toolkit; pharmaceutical companies used CUDA to discover new treatments, car companies used CUDA to augment and train autonomous vehicles, and retail stores use CUDA to analyze customer purchases to develop robust and accurate recommender systems.
CUDA Toolkit is a free resource for one or more CUDA-capable GPUs. Its use case spans from indie developers and data scientists to enterprise corporations with large deep learning and AI infrastructure.

Many frameworks rely on CUDA for GPU support such as TensorFlow, PyTorch, Keras, MXNet, and Caffe2 through cuDNN (CUDA Deep Neural Network). Training an AI model requires the use of neural networks and cuDNN supports the use of these complex tools required for deep learning.
Alongside cuDNN, CUDA includes tools like TensorRT, DeepSteream SDK, NCCL, and more. Here's a short rundown of what each tool provides:
In addition to these top-level applications and SDKs, CUDA Toolkit also includes various libraries and components for debugging, optimization, documentation, runtime, signal processing, and more.
As mentioned before, CUDA provides support to accelerate C, C++, Fortran, Python, and MATLAB. But for the sake of simplicity, we will focus on C/C++. For easy adoption, CUDA provides a simple interface similar to that of C/C++. The benefit of CUDA is the ability to write scalar programs. Its compiler uses programming abstractions to leverage parallelism built into the CUDA programming model, lowering the programming burden.
The CUDA programming mode provides three key language extensions:
Let’s take a look at some code:
__global__ void vectorAdd( float *A, float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}The code example shows the CUDA kernel that adds two vectors, A and B with an output vector, C. The kernel code executes on the GPU and is scalar in nature because it adds two vectors in such a way that it looks like adding two scalar numbers.
When this code runs on GPU, it runs in a massively parallel fashion. Each element of the vector is executed by a thread in a CUDA block and all threads run in parallel and independently. This simplifies the parallel programming overhead.
The diagram below shows how a CUDA program is scalable. The CUDA Runtime can choose how to allocate these blocks to the streaming multiprocessors (SMs).
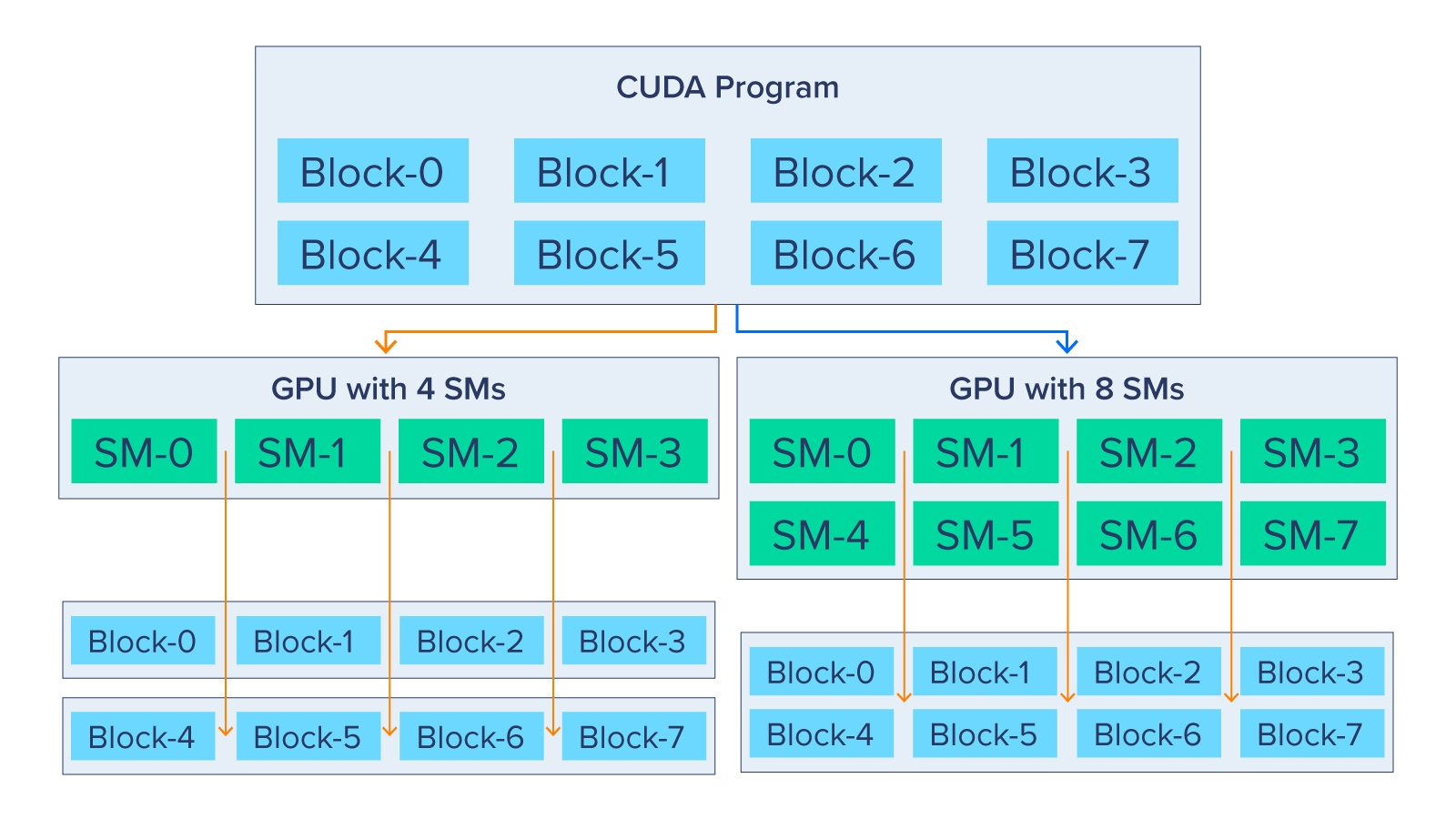
Smaller GPUs with 4 SMs get two separate CUDA blocks while large GPUs with 8 SMs will have only 1 CUDA block. The GPU with 4 SMs will have to execute thread blocks 0, 1, 2, and 3 simultaneously and then start 4, 5, 6, and 7 simultaneously. Of course, more SMs means more parallelization where thread blocks 0-7 are all executed simultaneously in the GPU with 8 SMs.
This enables performance scalability for applications with more powerful GPUs without any code changes, and precisely the reason why data center GPUs and their computing resources are so valuable.
Learn more about
Maximizing parallel execution starts with structuring the algorithm in a way that exposes as much parallelism as possible and mapped to the hardware as efficiently as possible by carefully choosing the execution configuration of each kernel launch. The application should also maximize parallel execution at a higher level by explicitly exposing concurrent execution on the device through streams, as well as maximizing concurrent execution between the host and the device.
Optimizing memory usage starts with minimizing data transfers between the host and the device. Keeping data close to the host and internally can drastically decrease the number of unnecessary data transfers to the device. Kernel access to global memory also should be minimized by maximizing the use of shared memory on the device. Though counter-intuitive, because GPUs are excellent at computation, sometimes the best optimization might even be to avoid any data transfer in the first place by simply recomputing the data whenever it is needed.
The effective bandwidth can vary depending on the access pattern for each memory type. Optimizing memory usage can be as simple as organizing memory accesses according to the optimal memory access patterns. This optimization is especially important for global memory accesses because latency of access costs hundreds of clock cycles.
As for optimizing instruction usage, the use of arithmetic instructions that have low throughput should be avoided. This suggests trading precision for speed when it does not affect the result, such as using intrinsics instead of regular functions or single precision instead of double precision.
It comes as no surprise, the NVIDIA H100 looks to be the best GPU for AI workloads using the CUDA Toolkit. As NVIDIA’s flagship GPU and Data Center AI accelerator, it's already implemented numerous best practices built into its architecture.
The complexity of NVIDIA H100 needs a new way to organize and control the locality of thread blocks. Thread block contains concurrent threads on an SM; to further organize, the hierarchical addition of thread block clusters increases the efficiency of concurrent threads over the entire SM. This grouping has also enabled distributed shared memory (DSMEM) to enable efficient data exchange using an SM-to-SM network instead of a global memory network. Thread Block Clusters and DSMEM accelerated data exchanged by about 7x.
They have also taken part in optimization instructions usage by enabling the H100 to train on a new tensor processing format FP8. FP8 supports computations requiring less dynamic range with more precision halving the storage requirement while doubling throughput compared to FP16. To increase precision dramatically, NVIDIA H100 incorporates a new Transformer Engine that uses executes using dynamic mixed precision processing on both FP8 and FP16 numerical formats to reduce usage on data usage and increase speeds while retaining precision and accuracy.

The NVIDIA H100 is getting ready to ship with OEM partners this month and the DGX H100 is shipping in Q1 2023. If you are itching to try this monster of a GPU and AI accelerator, NVIDIA is offering Test Drive via NVIDIA LaunchPad.
Here’s how to get a system ready for CUDA installation. After CUDA is installed, you can start writing parallel applications and take advantage of the massive parallelism available in GPUs.
Here are some resources to NVIDIA’s website that might help with figuring out if CUDA is right for your workload as well as some great documentation that we couldn’t go in-depth here in this blog.
For more information, see the CUDA Programming Guide.
Looking for an all-in-one solution to fuel your Deep Learning and AI workloads?
Contact Exxact Today!
Deep learning and AI workloads such as building, training, and inferencing all require an ample amount of computing resources. Many of these workloads can be performed in parallel since deep learning neural networks are “embarrassingly parallel” an actual term used to describe workloads that can be broken up into smaller sub-computations and be performed all at the same time.
GPUs or Graphics Processing Units offer excellent parallelization in workloads and have only in the last decade taken interest in the AI and Deep Learning Industry. Without the incorporation of GPUs, training, building, and deploying deep learning models can span days, weeks, months even… GPUs enable much less time to fully develop an AI.
NVIDIA CUDA is a software platform API that enables parallel computing with GPU hardware making it easier for developers to build software that accelerates tasks by allowing workloads to be distributed across parallelized GPUs.
Using the NVIDIA CUDA Toolkit you can accelerate your C or C++ applications by updating computationally intense portions of your code to run on GPUs. Call functions from drop-in libraries or develop custom applications using languages including C, C++, Fortran, Python, and MATLAB.
Companies from around the world have harnessed the CUDA Toolkit; pharmaceutical companies used CUDA to discover new treatments, car companies used CUDA to augment and train autonomous vehicles, and retail stores use CUDA to analyze customer purchases to develop robust and accurate recommender systems.
CUDA Toolkit is a free resource for one or more CUDA-capable GPUs. Its use case spans from indie developers and data scientists to enterprise corporations with large deep learning and AI infrastructure.
Many frameworks rely on CUDA for GPU support such as TensorFlow, PyTorch, Keras, MXNet, and Caffe2 through cuDNN (CUDA Deep Neural Network). Training an AI model requires the use of neural networks and cuDNN supports the use of these complex tools required for deep learning.
Alongside cuDNN, CUDA includes tools like TensorRT, DeepSteream SDK, NCCL, and more. Here's a short rundown of what each tool provides:
In addition to these top-level applications and SDKs, CUDA Toolkit also includes various libraries and components for debugging, optimization, documentation, runtime, signal processing, and more.
As mentioned before, CUDA provides support to accelerate C, C++, Fortran, Python, and MATLAB. But for the sake of simplicity, we will focus on C/C++. For easy adoption, CUDA provides a simple interface similar to that of C/C++. The benefit of CUDA is the ability to write scalar programs. Its compiler uses programming abstractions to leverage parallelism built into the CUDA programming model, lowering the programming burden.
The CUDA programming mode provides three key language extensions:
Let’s take a look at some code:
__global__ void vectorAdd( float *A, float *B, float *C, int numElements) {
int i = blockDim.x * blockIdx.x + threadIdx.x;
if (i < numElements) {
C[i] = A[i] + B[i];
}
}The code example shows the CUDA kernel that adds two vectors, A and B with an output vector, C. The kernel code executes on the GPU and is scalar in nature because it adds two vectors in such a way that it looks like adding two scalar numbers.
When this code runs on GPU, it runs in a massively parallel fashion. Each element of the vector is executed by a thread in a CUDA block and all threads run in parallel and independently. This simplifies the parallel programming overhead.
The diagram below shows how a CUDA program is scalable. The CUDA Runtime can choose how to allocate these blocks to the streaming multiprocessors (SMs).
Smaller GPUs with 4 SMs get two separate CUDA blocks while large GPUs with 8 SMs will have only 1 CUDA block. The GPU with 4 SMs will have to execute thread blocks 0, 1, 2, and 3 simultaneously and then start 4, 5, 6, and 7 simultaneously. Of course, more SMs means more parallelization where thread blocks 0-7 are all executed simultaneously in the GPU with 8 SMs.
This enables performance scalability for applications with more powerful GPUs without any code changes, and precisely the reason why data center GPUs and their computing resources are so valuable.
Learn more about
Maximizing parallel execution starts with structuring the algorithm in a way that exposes as much parallelism as possible and mapped to the hardware as efficiently as possible by carefully choosing the execution configuration of each kernel launch. The application should also maximize parallel execution at a higher level by explicitly exposing concurrent execution on the device through streams, as well as maximizing concurrent execution between the host and the device.
Optimizing memory usage starts with minimizing data transfers between the host and the device. Keeping data close to the host and internally can drastically decrease the number of unnecessary data transfers to the device. Kernel access to global memory also should be minimized by maximizing the use of shared memory on the device. Though counter-intuitive, because GPUs are excellent at computation, sometimes the best optimization might even be to avoid any data transfer in the first place by simply recomputing the data whenever it is needed.
The effective bandwidth can vary depending on the access pattern for each memory type. Optimizing memory usage can be as simple as organizing memory accesses according to the optimal memory access patterns. This optimization is especially important for global memory accesses because latency of access costs hundreds of clock cycles.
As for optimizing instruction usage, the use of arithmetic instructions that have low throughput should be avoided. This suggests trading precision for speed when it does not affect the result, such as using intrinsics instead of regular functions or single precision instead of double precision.
It comes as no surprise, the NVIDIA H100 looks to be the best GPU for AI workloads using the CUDA Toolkit. As NVIDIA’s flagship GPU and Data Center AI accelerator, it's already implemented numerous best practices built into its architecture.
The complexity of NVIDIA H100 needs a new way to organize and control the locality of thread blocks. Thread block contains concurrent threads on an SM; to further organize, the hierarchical addition of thread block clusters increases the efficiency of concurrent threads over the entire SM. This grouping has also enabled distributed shared memory (DSMEM) to enable efficient data exchange using an SM-to-SM network instead of a global memory network. Thread Block Clusters and DSMEM accelerated data exchanged by about 7x.
They have also taken part in optimization instructions usage by enabling the H100 to train on a new tensor processing format FP8. FP8 supports computations requiring less dynamic range with more precision halving the storage requirement while doubling throughput compared to FP16. To increase precision dramatically, NVIDIA H100 incorporates a new Transformer Engine that uses executes using dynamic mixed precision processing on both FP8 and FP16 numerical formats to reduce usage on data usage and increase speeds while retaining precision and accuracy.
The NVIDIA H100 is getting ready to ship with OEM partners this month and the DGX H100 is shipping in Q1 2023. If you are itching to try this monster of a GPU and AI accelerator, NVIDIA is offering Test Drive via NVIDIA LaunchPad.
Here’s how to get a system ready for CUDA installation. After CUDA is installed, you can start writing parallel applications and take advantage of the massive parallelism available in GPUs.
Here are some resources to NVIDIA’s website that might help with figuring out if CUDA is right for your workload as well as some great documentation that we couldn’t go in-depth here in this blog.
For more information, see the CUDA Programming Guide.
Looking for an all-in-one solution to fuel your Deep Learning and AI workloads?
Contact Exxact Today!
