Artificial Intelligence
The 7 Best Open Source AI Libraries You May Not Have Heard Of
April 23, 2021
23 min read


It's easy to get pulled into using popular platforms like TensorFlow and PyTorch, but there are a number of other great open source resources that can help you in your AI research.
The truth is there is so much interesting work and so many brilliant new tools being developed on a daily basis in open source artificial intelligence. It can be difficult to keep up with the ever accelerating developments in AI and deep learning.
So, we've taken the time to curate some interesting tools that you may be able to use. In this article, we’ll take a look at 7 interesting libraries for doing a wide variety of cutting edge research in artificial intelligence and related areas.
The diversity of the libraries on this list is significant, and if at least one of the libraries isn’t an exact fit for your next project (or perhaps an inspiration for one), they are all licensed under permissive open source licenses so you can contribute, fork, and modify these libraries to your heart’s content. We’ll consider libraries covering everything from quantum machine learning to encrypted computation that can train AI models on data that you never actually see.
Two of the libraries also represent the up and coming Julia language, custom-tailored for both speed and productivity. So read on to learn more about these interesting open source libraries that haven’t quite broken into the mainstream yet.
#7 DiffEqFlux.jl: Neural Differential Equations in Julia Language
#6: PennyLane: A Library That is in a Superposition of Being Great for Machine Learning and Quantum Computation Simultaneously
#5: Flux.jl: a New Way to Differentiate Automatically, Just in Time
#4: TensorFlow Probability: Sometimes Being Right Means Being Uncertain
#3: PySyft: Learning From Data You Can’t See
#2: AutoKeras: Why Tune Hyperparameters Yourself When you Can Teach the Machine to do it?
#1: JAX: A Fast New Automatic Differentiation Library with a Functional Flavor
Interested in a deep learning workstation?
Learn more about Exxact AI workstations starting at $3,700
MIT License — GitHub Stars: 481 — repo: https://github.com/SciML/DiffEqFlux.jl/
The DiffEqFlux.jl logo, from the MIT licensed documentation files.
The Julia programming language is a relatively young programming language (about 9 years old, compared to Python’s 30 years) designed specifically for scientific computing. Julia is intended to bridge the gap between high productivity languages like Python, that facilitate productive programming by operating at a very high level of abstraction, and high speed languages like C++, that achieve fast runtimes by being written at a low level of detail that is closer to the machine operations executed in hardware.
Julia language attempts to achieve both characteristics by combining just in time compilation with a dynamic programming paradigm. While that sometimes means executing something for the first time takes a little longer (to account for compilation), over time the ability to run algorithms at nearly the speed of C can be quite worthwhile.
While the language’s objectives are designed specifically for scientific computing and research, machine learning and artificial intelligence researchers are beginning to take a strong interest. With the help of packages like Flux.jl (number 5 on our list) for differentiable programming, the Julia language is developing a community and ecosystem for both fast iteration and fast inference and training times.
The DiffEqFlux.jl package is just one example of how development efforts around the Julia language are catering to cutting edge deep learning and AI research. DiffEqFlux.jl combines tools from DifferentialEquations.jl and Flux.jl to facilitate building Neural Ordinary Differential Equations, which made quite an impact at NeurIPs 2018 (including netting a best paper award).
But DiffEqFlux.jl has a number of other features that may be of interest to the combined scientific machine learning and differential equation enthusiast. In addition to neural ODEs, DiffEqFlux.jl supports stochastic differential equations, universal partial differential equations, and more. It also offers GPU support, and while the package may be too cutting edge for production systems, it seems perfect for researchers for which the prospect of discovery supersedes commercial application.
Find out more in the DiffEqFlux.jl release blog post.
Apache 2.0 — GitHub Stars: 817 — repo: https://github.com/PennyLaneAI/pennylane
Quantum computing has been promising for years to disrupt many technologies modern society has come to rely on, with public-key encryption being one area that springs readily to mind. In the midst of widespread research enthusiasm and commercial applications of AI in the last decade, the role that quantum computing might play in machine learning has gone largely unnoticed. The two camps tend to foment a technological fervor for their societal and scientific impacts completely in isolation of one other. PennyLane, a quantum machine learning library for Python developed by Xanadu.ai aims to change that.
Most mainstream quantum computing efforts from the likes of IBM, Amazon, and Google tend to focus on the manipulation of qubits, the superpositioned quantum analog to digital bits. Xanadu takes a different approach based on the manipulation of squeezed states of light with desired quantum properties, generalized as what they call “qumodes”. Qumodes can be thought of as similar to an analog version of qubits, like voltage levels in an analog circuit compared to the 1s and 0s of digital computation.
One advantage of the use of photonic qumodes is operation on photonic integrated circuits, mostly at room temperature, obviating the need for supercooled “chandelier style” quantum computers. Another advantage is the ready application of quantum circuits based on qumodes to quantum and hybrid machine learning systems.
Workers examine/pose for a photo with a “chandelier style” apparatus supporting quantum computing hardware. Image CC BY Wikipedia contributor FMNLab.
PennyLane leverages the automatic differentiation that has generated so many of the big successes in deep learning along with quantum circuit simulation. Quantum circuits can also be executed on real quantum hardware (including Xanadu’s own quantum photonic chips) with the right plugin. PennyLane originally based most of their automatic differentiation capabilities on the Autograd library, an academic project and the ancestor of up-and-coming JAX (the number 1 library on this list), but they’ve added other backends since.
PennyLane has evolved beyond relying strictly on Autograd and now supports the use of PyTorch and TensorFlow backends as well as several different quantum simulators and devices. PennyLane is principally designed for building quantum and hybrid circuits that can be trained and updated by backpropagation, but it’s a general enough library that it’s worth trying out even if you never plan to buy or use actual quantum hardware.
We also note that the coding and unit-testing style employed by the PennyLane team is top-notch, and since it’s open source (under the Apache 2.0 license) with plenty of “good first issues” on GitHub, it’s easy to make meaningful contributions while simultaneously bringing yourself up to speed with the promising domain of quantum machine learning.
MIT “Expat” License — GitHub Stars: 2.9k — repo: https://github.com/FluxML/Flux.jl
Entry number 5 is the second library on our list that supports the Julia programming language, and the second library to be licensed under the simple and permissive open source MIT License. Flux.jl is a capable library for automatic differentiation for machine learning and differentiable programming in general.
It takes a different approach than the high-level application programming interfaces of libraries like fast.ai for PyTorch or Keras in TensorFlow, instead staying true to its mathematical and scientific computing roots to support coding patterns that are very similar to the equations you might read in a scientific paper describing a new ML technique.
Flux.jl is used in many other Julia language machine learning projects, including DiffEqFlux.jl that we discussed earlier. For the interested beginner looking for an experience most similar to Autograd or JAX from Python, Zygote.jl, a Flux-based library for advanced automatic differentiation, is probably the best place to start.
Apache 2.0 — GitHub Stars: 3.3k — repo: https://github.com/tensorflow/probability
What’s the weather going to be like tomorrow? Sun, rain, or snow, it’s a well known fact of life that predicting the weather with certainty is most likely going to stay a fool’s errand. Instead we are used to hearing meteorological predictions couched alongside some numbers that indicates the probability of a certain type of weather. If the weatherperson you subscribe to is really good, they might also convey a measure of confidence that their probabilistic prediction is a good one.
Many, if not most, of the meaningful expectations we have about the world have an element of uncertainty to them, owing to the complexity of even simple-seeming systems, and in some cases stochasticity in the underlying processes themselves. TensorFlow Probability provides tools for reasoning about uncertainty, probability, and statistical analyses. These capabilities can help to build confidence about model predictions, and avoid embarrassing inference outputs for out-of-distribution input data, something that conventional deep learning models don’t do.
Let’s walk through an example from the TensorFlow Probability documentation, to get a feeling for how wrong we can be when we don’t take into account uncertainty or stochastic processes.
The following 4 plots are licensed under a Creative Commons Attribution License, with attribution going to the TensorFlow Probability team.
This example is a simple case of a regression problem with TF Probability. We’ll define and discuss the two major categories of uncertainty, aleatoric and epistemic, and see what happens when we apply either type of uncertainty and both types to the regression problem.
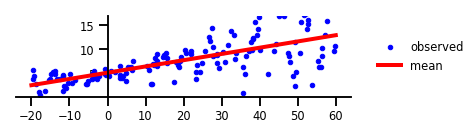
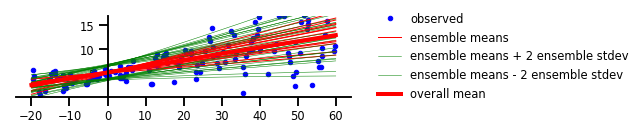
First, let’s take a look at how the data are fitted using a simple linear regression model with no uncertainty of either kind applied.
With no uncertainty, we get a line that generally follows the central trendline for all observations, and while this may tell us something about the data, it definitely looks like it’s only grasping part of the story. For some parts of the line, the residues (difference between the model’s output and the observation) are quite small, and in other sections the observed spread is increased significantly and the line doesn’t seem to explain the data very well. This seems to pivot around the point where the model output crosses the y-axis at x=0. Since it looks like the model with no uncertainty doesn’t account for the data particularly well, let’s look next at what the model can do with epistemic uncertainty applied.
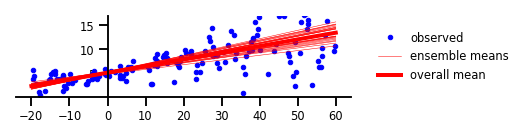
In human terms, epistemic uncertainty comes from a lack of experience. That is to say that epistemic uncertainty should decrease with increased exposure to a given type of training sample. This is an important form of uncertainty for machine learning models, since predictions based on rare sample type and edge cases can lead to dangerously erroneous errors. If a model is capable of estimating epistemic uncertainty, it can make predictions on rare data but also indicate “but you probably shouldn’t trust this prediction, and we should probably get more examples like this in the dataset,” instead of a wild guess with (assumed by default) high confidence.
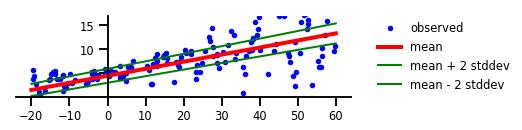
A clue to the meaning of aleatoric uncertainty can be found in its etymology, where aleator is Latin for a dice-player, aka a gambler. Aleatoric uncertainty represents the intrinsic stochasticity of an event or prediction, much like the roll of a pair of dice. No matter how many examples of a perfect dice roll we show a model (or human) it’s impossible to get any better at predicting the result than the probabilities associated with the roll itself. Aleatoric uncertainty applied to our example regression problem looks like the figure below.
In this example, aleatoric uncertainty is expressed by statistical error bounds, and we can see that while epistemic uncertainty appeared to capture a pivot-point where the data crosses the y-axis, aleatoric uncertainty yields a slow-varying error bound that only widens slightly at the more loosely packed right hand sand of the data distribution. What happens when we combine both aleatoric and epistemic uncertainty?
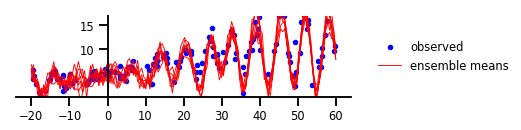
After applying both aleatoric and epistemic uncertainty methods to the example regression problem, we now have predictions that convey areas of high uncertainty that fit with our intuitive observations. The model estimates seem to capture both the interesting pivot area and some of the underlying stochasticity in the data. But TF probability has one more trick to show off in an estimate of “functional uncertainty” based on a variational Gaussian process layer with a radial basis function kernel.
We can see in the figure that this custom uncertainty model captures a previously unnoticed periodicity in the data, or at least the periodicity was far from apparent to this author on first observation. This example regression problem was pretty striking when viewing the public presentation of TF Probability at the 2019 TensorFlow Developers Summit.
TF Probability provides tools for imbuing machine learning models with an appreciation for known unknowns (aleatoric uncertainty) unknown unknowns (epistemic) and for even stranger applications of probability and statistical reasoning. With the role of AI and ML models in everyday life growing week by week, a model that knows when it doesn’t know is an unquestionably valuable thing.
Apache 2.0 — GitHub Start: 7k — repo: https://github.com/OpenMined/PySyft
When people talk about AI safety, they’re often talking about the superhuman intelligence and speed of the variety found unconstrained by physics in science fiction (and Nick Bostrom’s Superintelligence). That certainly leads to entertaining thought experiments, and while AI safety efforts focused on ontological superintelligence are not entirely a waste of time, efforts may be better spent on clear and present examples of AI and machine learning doing real harm to real people happening today and for most of the last decade.
Many of these dangers can be attributed to a lack of privacy respecting technology and policy in corporations, governments, and other institutions that either don’t know any better or have privacy intrusion as a core component of their business model. But there is a better way.
PySyft is a library built for privacy-respecting machine learning. How is this possible? You might ask. After all, if a modern institution wants to use machine learning in an effective way, they’re going to need data, much of it of a personal or private nature in one way or another. You may be surprised by what can be inferred from seemingly innocuous data. The controversial “target predicts teen pregnancy” urban legend is one example, even if it is a bit of a stretch of the truth.
Sensitive data generated by a normal modern human in their daily life may include health records, dating preferences, financial records, and more. All of these are examples of data that people in general want to be seen only for very specific purposes and only by very specific people or algorithms, and only to be used for intended purposes. One likely would appreciate their doctor having access to their medical scans and records, but would not appreciate those same data finding their way to influence advertisements from their local pharmacy (or worse, fast food delivery apps).
PySyft enables a rare breed of privacy respecting machine learning by providing tools for learning and computation on “data you do not own and cannot see.”
Apache 2.0 — GH Stars: 7.9k — repo: https://github.com/keras-team/autokeras
As deep learning has become a prominent approach to artificial intelligence (with lucrative commercial applications, besides), it’s become increasingly easy to put together a deep neural network to solve a typical problem like image segmentation, classification, or predicting preferences and behavior.
With high-level libraries like Keras (part of TensorFlow since 2.0) and fast.ai for PyTorch, it’s incredibly easy to connect a few layers together and fit them to a dataset of interest. With Keras, it’s as simple as the model.fit API. AutoKeras adds an additional layer of simplifying automation. When it works perfectly, you don’t even have to specify the model architecture.
Gone are the days of toiling over bespoke CUDA code and custom gradient checking to build a deep neural network. Even the tedious graph session programming patterns of the 1.x TensorFlow releases are no longer necessary. But there is one aspect of successful deep learning that is yet to be widely automated away in practice, and that is the careful tuning of hyperparameters to get the best possible model for a given dataset.
Although a simple grid search is one of the least-advised methods for exploring possible hyperparameter settings, it’s still probably the most common (at least if we ignore another popular method: let the intern/grad student tune the model). Unfortunately this not only tends to cause a higher energy and economic cost, but it’s also not the best way to find optimal set hyperparameters, and even random search is usually better. The downsides of manual or poorly automated hyperparameter search is the motivating factor behind a growing adoption of automated machine learning, or AutoML.
AutoKeras is an automated machine learning library that combines the facile utility of Keras with the convenience of automated hyperparameter and even architectural tuning. One of the clearest examples of this is the AutoKeras AutoModel class. This class can be used to define a “HyperModel” simply by its inputs and outputs. Similar to the way a model class is trained in normal Keras, AutoKeras AutoModels can be trained by invoking a fit() method. Not only does this automatically tune hyperparameters, but it also develops an optimized internal architecture as well.
Now this may seem like a severe case of automating away one’s job, but ultimately AutoML tools like AutoKeras are a valuable tool for conserving one of the most valuable resources a research software project has, that of developer time.
Apache 2.0 — GitHub Stars: 12.3k — repo: https://github.com/google/jax
Sure, your PyTorch game is on fire and you’ve studied the Flow of the Tensor, and maybe you’ve even used the automatic differentiation capabilities of one or both of the “big two” deep learning libraries. But if you haven’t experimented with JAX (or it’s spiritual successor, Autograd) you may still be missing out.
The inclusion of the JAX library in this list was a close decision due to it’s rapidly growing popularity, as we are ostensibly focused on lesser-known libraries. It’s entirely possible you’ve heard of JAX before, after all, Google DeepMind is one of the most well-known AI research institutes in the world, and they’ve found JAX to be enough of an enabling tool in their research to write a December 2020 blog post about adopting the language for much of their work.
DeepMind hasn’t just adopted JAX into their workflow as a functional automatic differentiation tool. Instead they’ve been quietly developing an entire JAX-centered ecosystem to support their own and others’ research. This ecosystem includes RLax for deep reinforcement learning, Haiku for combining and translating between functional and object-oriented programming paradigms, Jraph for deep learning on graphs, and many other JAX-based tools, all licensed under the open source-friendly Apache 2.0 License.
The DeepMind JAX ecosystem is not a bad place to start for researchers interested in leveraging the just in time compilation, hardware acceleration (including first-class support for modern GPUs), and pure functionality of JAX for AI research.
That concludes our list of unknown, yet awesome, open source libraries for AI research. We’ve covered a wide variety, from automatic machine learning to differentiable quantum circuits. And, there are a lot more open source resources out there to find and use. Hopefully at least a few of the ones discussed here have given you a new idea or two about how to approach your next project.
In many ways, a modern AI researcher is spoiled for choices in the number of specialized tools available. While it may no longer be necessary to start each project from scratch, knowing exactly which library is the best choice can be a challenge in itself. In any case, the entries on this list offer a rich space of capability and code to explore (and contribute to), and these libraries and their licenses are summarized in the table below.
| Name | License | Stars | Language, Flavor | Origin |
| JAX | Apache 2.0 | 12.2k | Python | Google, spiritual successor toautograd |
AutoKeras | Apache 2.0 | 7.9k | Python, TensorFlow | Texas A&MDATA Lab |
PySyft | Apache 2.0 | 7.0k | Python, PyTorch/TensorFlow | OpenMined Andrew Trask |
TensorFlow Probability | Apache 2.0 | 3.3k | Python, TensorFlow | |
Flux.jl | Mit Expat License | 2.9k | Julia language | Mike Innes, contributors |
PennyLane | Apache 2.0 | 820 | Python, autograd + multiple backends | Xanadu.ai |
DiffEqFlux.jl | MIT License | 487 | Julia language | Christopher Rackauckas and contributors |
Have any questions?
Contact Exxact Today
It's easy to get pulled into using popular platforms like TensorFlow and PyTorch, but there are a number of other great open source resources that can help you in your AI research.
The truth is there is so much interesting work and so many brilliant new tools being developed on a daily basis in open source artificial intelligence. It can be difficult to keep up with the ever accelerating developments in AI and deep learning.
So, we've taken the time to curate some interesting tools that you may be able to use. In this article, we’ll take a look at 7 interesting libraries for doing a wide variety of cutting edge research in artificial intelligence and related areas.
The diversity of the libraries on this list is significant, and if at least one of the libraries isn’t an exact fit for your next project (or perhaps an inspiration for one), they are all licensed under permissive open source licenses so you can contribute, fork, and modify these libraries to your heart’s content. We’ll consider libraries covering everything from quantum machine learning to encrypted computation that can train AI models on data that you never actually see.
Two of the libraries also represent the up and coming Julia language, custom-tailored for both speed and productivity. So read on to learn more about these interesting open source libraries that haven’t quite broken into the mainstream yet.
#7 DiffEqFlux.jl: Neural Differential Equations in Julia Language
#6: PennyLane: A Library That is in a Superposition of Being Great for Machine Learning and Quantum Computation Simultaneously
#5: Flux.jl: a New Way to Differentiate Automatically, Just in Time
#4: TensorFlow Probability: Sometimes Being Right Means Being Uncertain
#3: PySyft: Learning From Data You Can’t See
#2: AutoKeras: Why Tune Hyperparameters Yourself When you Can Teach the Machine to do it?
#1: JAX: A Fast New Automatic Differentiation Library with a Functional Flavor
Interested in a deep learning workstation?
Learn more about Exxact AI workstations starting at $3,700
MIT License — GitHub Stars: 481 — repo: https://github.com/SciML/DiffEqFlux.jl/
The DiffEqFlux.jl logo, from the MIT licensed documentation files.
The Julia programming language is a relatively young programming language (about 9 years old, compared to Python’s 30 years) designed specifically for scientific computing. Julia is intended to bridge the gap between high productivity languages like Python, that facilitate productive programming by operating at a very high level of abstraction, and high speed languages like C++, that achieve fast runtimes by being written at a low level of detail that is closer to the machine operations executed in hardware.
Julia language attempts to achieve both characteristics by combining just in time compilation with a dynamic programming paradigm. While that sometimes means executing something for the first time takes a little longer (to account for compilation), over time the ability to run algorithms at nearly the speed of C can be quite worthwhile.
While the language’s objectives are designed specifically for scientific computing and research, machine learning and artificial intelligence researchers are beginning to take a strong interest. With the help of packages like Flux.jl (number 5 on our list) for differentiable programming, the Julia language is developing a community and ecosystem for both fast iteration and fast inference and training times.
The DiffEqFlux.jl package is just one example of how development efforts around the Julia language are catering to cutting edge deep learning and AI research. DiffEqFlux.jl combines tools from DifferentialEquations.jl and Flux.jl to facilitate building Neural Ordinary Differential Equations, which made quite an impact at NeurIPs 2018 (including netting a best paper award).
But DiffEqFlux.jl has a number of other features that may be of interest to the combined scientific machine learning and differential equation enthusiast. In addition to neural ODEs, DiffEqFlux.jl supports stochastic differential equations, universal partial differential equations, and more. It also offers GPU support, and while the package may be too cutting edge for production systems, it seems perfect for researchers for which the prospect of discovery supersedes commercial application.
Find out more in the DiffEqFlux.jl release blog post.
Apache 2.0 — GitHub Stars: 817 — repo: https://github.com/PennyLaneAI/pennylane
Quantum computing has been promising for years to disrupt many technologies modern society has come to rely on, with public-key encryption being one area that springs readily to mind. In the midst of widespread research enthusiasm and commercial applications of AI in the last decade, the role that quantum computing might play in machine learning has gone largely unnoticed. The two camps tend to foment a technological fervor for their societal and scientific impacts completely in isolation of one other. PennyLane, a quantum machine learning library for Python developed by Xanadu.ai aims to change that.
Most mainstream quantum computing efforts from the likes of IBM, Amazon, and Google tend to focus on the manipulation of qubits, the superpositioned quantum analog to digital bits. Xanadu takes a different approach based on the manipulation of squeezed states of light with desired quantum properties, generalized as what they call “qumodes”. Qumodes can be thought of as similar to an analog version of qubits, like voltage levels in an analog circuit compared to the 1s and 0s of digital computation.
One advantage of the use of photonic qumodes is operation on photonic integrated circuits, mostly at room temperature, obviating the need for supercooled “chandelier style” quantum computers. Another advantage is the ready application of quantum circuits based on qumodes to quantum and hybrid machine learning systems.
Workers examine/pose for a photo with a “chandelier style” apparatus supporting quantum computing hardware. Image CC BY Wikipedia contributor FMNLab.
PennyLane leverages the automatic differentiation that has generated so many of the big successes in deep learning along with quantum circuit simulation. Quantum circuits can also be executed on real quantum hardware (including Xanadu’s own quantum photonic chips) with the right plugin. PennyLane originally based most of their automatic differentiation capabilities on the Autograd library, an academic project and the ancestor of up-and-coming JAX (the number 1 library on this list), but they’ve added other backends since.
PennyLane has evolved beyond relying strictly on Autograd and now supports the use of PyTorch and TensorFlow backends as well as several different quantum simulators and devices. PennyLane is principally designed for building quantum and hybrid circuits that can be trained and updated by backpropagation, but it’s a general enough library that it’s worth trying out even if you never plan to buy or use actual quantum hardware.
We also note that the coding and unit-testing style employed by the PennyLane team is top-notch, and since it’s open source (under the Apache 2.0 license) with plenty of “good first issues” on GitHub, it’s easy to make meaningful contributions while simultaneously bringing yourself up to speed with the promising domain of quantum machine learning.
MIT “Expat” License — GitHub Stars: 2.9k — repo: https://github.com/FluxML/Flux.jl
Entry number 5 is the second library on our list that supports the Julia programming language, and the second library to be licensed under the simple and permissive open source MIT License. Flux.jl is a capable library for automatic differentiation for machine learning and differentiable programming in general.
It takes a different approach than the high-level application programming interfaces of libraries like fast.ai for PyTorch or Keras in TensorFlow, instead staying true to its mathematical and scientific computing roots to support coding patterns that are very similar to the equations you might read in a scientific paper describing a new ML technique.
Flux.jl is used in many other Julia language machine learning projects, including DiffEqFlux.jl that we discussed earlier. For the interested beginner looking for an experience most similar to Autograd or JAX from Python, Zygote.jl, a Flux-based library for advanced automatic differentiation, is probably the best place to start.
Apache 2.0 — GitHub Stars: 3.3k — repo: https://github.com/tensorflow/probability
What’s the weather going to be like tomorrow? Sun, rain, or snow, it’s a well known fact of life that predicting the weather with certainty is most likely going to stay a fool’s errand. Instead we are used to hearing meteorological predictions couched alongside some numbers that indicates the probability of a certain type of weather. If the weatherperson you subscribe to is really good, they might also convey a measure of confidence that their probabilistic prediction is a good one.
Many, if not most, of the meaningful expectations we have about the world have an element of uncertainty to them, owing to the complexity of even simple-seeming systems, and in some cases stochasticity in the underlying processes themselves. TensorFlow Probability provides tools for reasoning about uncertainty, probability, and statistical analyses. These capabilities can help to build confidence about model predictions, and avoid embarrassing inference outputs for out-of-distribution input data, something that conventional deep learning models don’t do.
Let’s walk through an example from the TensorFlow Probability documentation, to get a feeling for how wrong we can be when we don’t take into account uncertainty or stochastic processes.
The following 4 plots are licensed under a Creative Commons Attribution License, with attribution going to the TensorFlow Probability team.
This example is a simple case of a regression problem with TF Probability. We’ll define and discuss the two major categories of uncertainty, aleatoric and epistemic, and see what happens when we apply either type of uncertainty and both types to the regression problem.
First, let’s take a look at how the data are fitted using a simple linear regression model with no uncertainty of either kind applied.
With no uncertainty, we get a line that generally follows the central trendline for all observations, and while this may tell us something about the data, it definitely looks like it’s only grasping part of the story. For some parts of the line, the residues (difference between the model’s output and the observation) are quite small, and in other sections the observed spread is increased significantly and the line doesn’t seem to explain the data very well. This seems to pivot around the point where the model output crosses the y-axis at x=0. Since it looks like the model with no uncertainty doesn’t account for the data particularly well, let’s look next at what the model can do with epistemic uncertainty applied.
In human terms, epistemic uncertainty comes from a lack of experience. That is to say that epistemic uncertainty should decrease with increased exposure to a given type of training sample. This is an important form of uncertainty for machine learning models, since predictions based on rare sample type and edge cases can lead to dangerously erroneous errors. If a model is capable of estimating epistemic uncertainty, it can make predictions on rare data but also indicate “but you probably shouldn’t trust this prediction, and we should probably get more examples like this in the dataset,” instead of a wild guess with (assumed by default) high confidence.
A clue to the meaning of aleatoric uncertainty can be found in its etymology, where aleator is Latin for a dice-player, aka a gambler. Aleatoric uncertainty represents the intrinsic stochasticity of an event or prediction, much like the roll of a pair of dice. No matter how many examples of a perfect dice roll we show a model (or human) it’s impossible to get any better at predicting the result than the probabilities associated with the roll itself. Aleatoric uncertainty applied to our example regression problem looks like the figure below.
In this example, aleatoric uncertainty is expressed by statistical error bounds, and we can see that while epistemic uncertainty appeared to capture a pivot-point where the data crosses the y-axis, aleatoric uncertainty yields a slow-varying error bound that only widens slightly at the more loosely packed right hand sand of the data distribution. What happens when we combine both aleatoric and epistemic uncertainty?
After applying both aleatoric and epistemic uncertainty methods to the example regression problem, we now have predictions that convey areas of high uncertainty that fit with our intuitive observations. The model estimates seem to capture both the interesting pivot area and some of the underlying stochasticity in the data. But TF probability has one more trick to show off in an estimate of “functional uncertainty” based on a variational Gaussian process layer with a radial basis function kernel.
We can see in the figure that this custom uncertainty model captures a previously unnoticed periodicity in the data, or at least the periodicity was far from apparent to this author on first observation. This example regression problem was pretty striking when viewing the public presentation of TF Probability at the 2019 TensorFlow Developers Summit.
TF Probability provides tools for imbuing machine learning models with an appreciation for known unknowns (aleatoric uncertainty) unknown unknowns (epistemic) and for even stranger applications of probability and statistical reasoning. With the role of AI and ML models in everyday life growing week by week, a model that knows when it doesn’t know is an unquestionably valuable thing.
Apache 2.0 — GitHub Start: 7k — repo: https://github.com/OpenMined/PySyft
When people talk about AI safety, they’re often talking about the superhuman intelligence and speed of the variety found unconstrained by physics in science fiction (and Nick Bostrom’s Superintelligence). That certainly leads to entertaining thought experiments, and while AI safety efforts focused on ontological superintelligence are not entirely a waste of time, efforts may be better spent on clear and present examples of AI and machine learning doing real harm to real people happening today and for most of the last decade.
Many of these dangers can be attributed to a lack of privacy respecting technology and policy in corporations, governments, and other institutions that either don’t know any better or have privacy intrusion as a core component of their business model. But there is a better way.
PySyft is a library built for privacy-respecting machine learning. How is this possible? You might ask. After all, if a modern institution wants to use machine learning in an effective way, they’re going to need data, much of it of a personal or private nature in one way or another. You may be surprised by what can be inferred from seemingly innocuous data. The controversial “target predicts teen pregnancy” urban legend is one example, even if it is a bit of a stretch of the truth.
Sensitive data generated by a normal modern human in their daily life may include health records, dating preferences, financial records, and more. All of these are examples of data that people in general want to be seen only for very specific purposes and only by very specific people or algorithms, and only to be used for intended purposes. One likely would appreciate their doctor having access to their medical scans and records, but would not appreciate those same data finding their way to influence advertisements from their local pharmacy (or worse, fast food delivery apps).
PySyft enables a rare breed of privacy respecting machine learning by providing tools for learning and computation on “data you do not own and cannot see.”
Apache 2.0 — GH Stars: 7.9k — repo: https://github.com/keras-team/autokeras
As deep learning has become a prominent approach to artificial intelligence (with lucrative commercial applications, besides), it’s become increasingly easy to put together a deep neural network to solve a typical problem like image segmentation, classification, or predicting preferences and behavior.
With high-level libraries like Keras (part of TensorFlow since 2.0) and fast.ai for PyTorch, it’s incredibly easy to connect a few layers together and fit them to a dataset of interest. With Keras, it’s as simple as the model.fit API. AutoKeras adds an additional layer of simplifying automation. When it works perfectly, you don’t even have to specify the model architecture.
Gone are the days of toiling over bespoke CUDA code and custom gradient checking to build a deep neural network. Even the tedious graph session programming patterns of the 1.x TensorFlow releases are no longer necessary. But there is one aspect of successful deep learning that is yet to be widely automated away in practice, and that is the careful tuning of hyperparameters to get the best possible model for a given dataset.
Although a simple grid search is one of the least-advised methods for exploring possible hyperparameter settings, it’s still probably the most common (at least if we ignore another popular method: let the intern/grad student tune the model). Unfortunately this not only tends to cause a higher energy and economic cost, but it’s also not the best way to find optimal set hyperparameters, and even random search is usually better. The downsides of manual or poorly automated hyperparameter search is the motivating factor behind a growing adoption of automated machine learning, or AutoML.
AutoKeras is an automated machine learning library that combines the facile utility of Keras with the convenience of automated hyperparameter and even architectural tuning. One of the clearest examples of this is the AutoKeras AutoModel class. This class can be used to define a “HyperModel” simply by its inputs and outputs. Similar to the way a model class is trained in normal Keras, AutoKeras AutoModels can be trained by invoking a fit() method. Not only does this automatically tune hyperparameters, but it also develops an optimized internal architecture as well.
Now this may seem like a severe case of automating away one’s job, but ultimately AutoML tools like AutoKeras are a valuable tool for conserving one of the most valuable resources a research software project has, that of developer time.
Apache 2.0 — GitHub Stars: 12.3k — repo: https://github.com/google/jax
Sure, your PyTorch game is on fire and you’ve studied the Flow of the Tensor, and maybe you’ve even used the automatic differentiation capabilities of one or both of the “big two” deep learning libraries. But if you haven’t experimented with JAX (or it’s spiritual successor, Autograd) you may still be missing out.
The inclusion of the JAX library in this list was a close decision due to it’s rapidly growing popularity, as we are ostensibly focused on lesser-known libraries. It’s entirely possible you’ve heard of JAX before, after all, Google DeepMind is one of the most well-known AI research institutes in the world, and they’ve found JAX to be enough of an enabling tool in their research to write a December 2020 blog post about adopting the language for much of their work.
DeepMind hasn’t just adopted JAX into their workflow as a functional automatic differentiation tool. Instead they’ve been quietly developing an entire JAX-centered ecosystem to support their own and others’ research. This ecosystem includes RLax for deep reinforcement learning, Haiku for combining and translating between functional and object-oriented programming paradigms, Jraph for deep learning on graphs, and many other JAX-based tools, all licensed under the open source-friendly Apache 2.0 License.
The DeepMind JAX ecosystem is not a bad place to start for researchers interested in leveraging the just in time compilation, hardware acceleration (including first-class support for modern GPUs), and pure functionality of JAX for AI research.
That concludes our list of unknown, yet awesome, open source libraries for AI research. We’ve covered a wide variety, from automatic machine learning to differentiable quantum circuits. And, there are a lot more open source resources out there to find and use. Hopefully at least a few of the ones discussed here have given you a new idea or two about how to approach your next project.
In many ways, a modern AI researcher is spoiled for choices in the number of specialized tools available. While it may no longer be necessary to start each project from scratch, knowing exactly which library is the best choice can be a challenge in itself. In any case, the entries on this list offer a rich space of capability and code to explore (and contribute to), and these libraries and their licenses are summarized in the table below.
| Name | License | Stars | Language, Flavor | Origin |
| JAX | Apache 2.0 | 12.2k | Python | Google, spiritual successor toautograd |
AutoKeras | Apache 2.0 | 7.9k | Python, TensorFlow | Texas A&MDATA Lab |
PySyft | Apache 2.0 | 7.0k | Python, PyTorch/TensorFlow | OpenMined Andrew Trask |
TensorFlow Probability | Apache 2.0 | 3.3k | Python, TensorFlow | |
Flux.jl | Mit Expat License | 2.9k | Julia language | Mike Innes, contributors |
PennyLane | Apache 2.0 | 820 | Python, autograd + multiple backends | Xanadu.ai |
DiffEqFlux.jl | MIT License | 487 | Julia language | Christopher Rackauckas and contributors |
Have any questions?
Contact Exxact Today


{kind=link}