Artificial Intelligence
5 Applications of Computer Vision for Deep Learning
July 30, 2019
13 min read


An introduction to Computer Vision and how Deep Learning has helped it advance.
Computer Vision refers to the entire process of emulating human vision in a non-biological apparatus. This includes the initial capturing of images, the detection and identification of objects, recognizing the temporal context between scenes, and developing a high-level understanding of what is happening for the relevant time period.
This technology has long been commonplace in science fiction, and as such, is often taken for granted. In reality, a system to provide reliable, accurate, and real-time computer vision is a challenging problem that has yet to be fully developed.
As these systems mature, there will be countless applications that rely on computer vision as a key component. Examples of this are self-driving cars, autonomous robots, unmanned aerial vehicles, intelligent medical imaging devices that assist with surgery, and surgical implants that restore human sight.
While computer vision holds great promise for the future, it carries an inherent complexity that has always been challenging for a computer. Part of the complexity is borne of the fact that computer vision is not a single task. Rather, it is a series of not-so-simple tasks that each demands the use of intricate algorithms and enough computing power to operate in real time.
From a high level, the sub-tasks that comprise computer vision are object detection and segmentation, image classification, object tracking, labeling images with meaningful descriptions (i.e. image captioning), and finally, understanding the meaning of the entire scene.

Traditional computer vision systems are an amalgamation of algorithms that work together in an attempt to solve the aforementioned tasks. The main goal is to extract features from the image, which involves sub-tasks such as edge detection, corner detection, and segmentation based on coloring. The accuracy of the algorithms used for feature extraction depends on the design and flexibility of each.
Examples of traditional feature extraction algorithms are Scale-invariant feature transform (SIFT), Speeded up robust features (SURF), and Binary Robust Independent Elementary Features (BRIEF). Different algorithms perform with varying degrees of success, depending on the type and quality of the images being used as input. Ultimately, the accuracy of the entire system depends on the methods used to extract features. Once the features have been extracted, the analysis is taken over by traditional Machine Learning methods.
The main problem with this approach is that the system needs to be told which features to look for in the image. Essentially, given that the algorithm operates as defined by the algorithm designer, the extracted features are human-engineered. In such implementations, the poor performance of an algorithm can be addressed through fine-tuning, such as by tweaking parameters, or code-level modifications to adjust the behavior. Changes such as this, however, need to be done manually and are hardcoded, or fixed, for a specific application.
While there are still significant obstacles in the path of human-quality computer vision, Deep Learning systems have made significant progress in dealing with some of the relevant sub-tasks. The reason for this success is partly based on the additional responsibility assigned to deep learning systems.
It is reasonable to say that the biggest difference with deep learning systems is that they no longer need to be programmed to specifically look for features. Rather than searching for specific features by way of a carefully programmed algorithm, the neural networks inside deep learning systems are trained. For example, if cars in an image keep being misclassified as motorcycles then you don’t fine-tune parameters or re-write the algorithm. Instead, you continue training until the system gets it right.
With the increased computational power offered by modern-day deep learning systems, there is steady and noticeable progress towards the point where a computer will be able to recognize and react to everything that it sees.
Classification is the process of predicting a specific class, or label, for something that is defined by a set of data points. Machine learning systems build predictive models that have enormous, yet often unseen benefits for people. For example, the reliable classification of spam email means that the average inbox is less burdened and more manageable. While the average end-user is likely unaware of the complexity of the problem and the vast amount of processing required to mitigate it, the benefits are clear.
Image classification is a subset of the classification problem, where an entire image is assigned a label. Perhaps a picture will be classified as a daytime or nighttime shot. Or, in a similar way, images of cars and motorcycles will be automatically placed into their own groups.
There are countless categories, or classes, in which a specific image can be classified. Consider a manual process where images are compared and similar ones are grouped according to like-characteristics, but without necessarily knowing in advance what you are looking for. Obviously, this is an onerous task. To make it even more so, assume that the set of images numbers in the hundreds of thousands. It becomes readily apparent that an automatic system is needed in order to do this quickly and efficiently.
The deep learning architecture for image classification generally includes convolutional layers, making it a convolutional neural network (CNN). Several hyperparameters, such that the number of convolutional layers and the activation function for each layer, will have to be set. This is a non-trivial part of the process that it outside of the scope of this discussion. However, as a starting point, one can usually select these values based on existing research.
On such system is AlexNet, which is a CNN that gained attention when it won the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Another well-studied model is the Residual Neural Network (ResNet), which later won the same challenge, as well as the Microsoft Common Objects in Context (MS COCO) competition, in 2015.
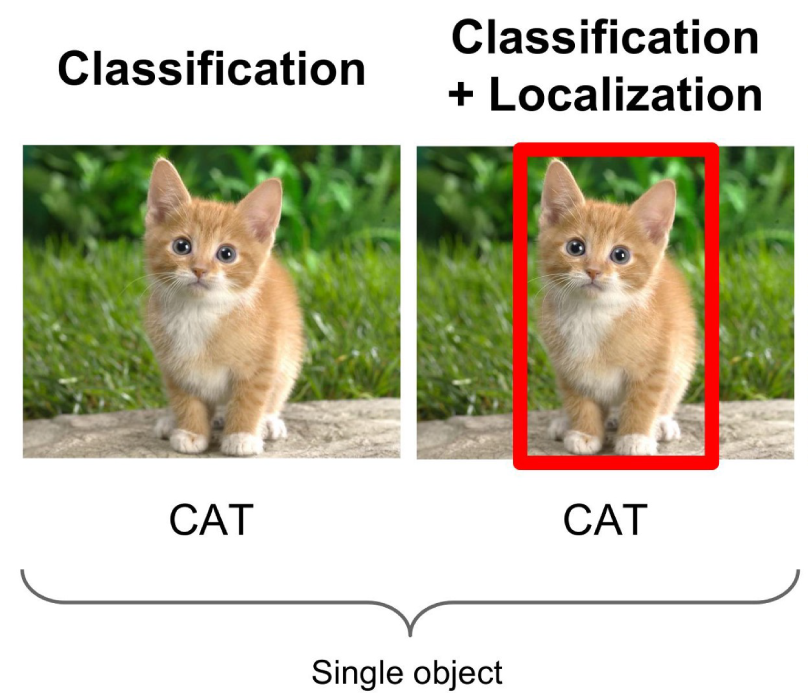
The second application of deep learning for computer vision is Image Classification with Localization. This problem is a specialization of image classification, with the additional requirement that the object within the picture is first located, and then a bounding box is drawn around it.
This is a more difficult problem than image classification, and it begins with determining whether there is only a single object depicted. If so, or if the number of objects is known, then the goal is to locate each object and identify the four corners of the corresponding bounding box.
This process would be a necessary step in a system responsible for vehicle identification. Consider an automated system that browses pictures of cars, and it is guaranteed that there is a single vehicle contained within the scene. Once the vehicle has been located, properties such as the make, model, and color can be identified.
This task can be accomplished by using a popular deep learning model, such as AlexNet or ResNet, and modifying the fully connected layer to create the bounding box. As mentioned previously, there may be some fine-tuning to do in terms of setting hyperparameters or modifying the architecture for efficiency in a particular domain, but in practice, the basic architectures perform well. It will be necessary to have sufficient training data that includes examples with both the object description and the bounding box clearly defined, although sample datasets are available for this purpose.
The difficulty with this task comes about when there is an unknown number of objects in the picture. In the majority of images, especially those taken in public areas, there will be many possibilities such as different people, vehicles, trees, and animals. For this kind of environment, the problem becomes one of object detection.
Source: CS231n (Stanford Lecture Slides)
Object Detection is image classification with localization, but in pictures that may contain multiple objects. This is an active and important area of research because the computer vision systems that will be used in robotics and self-driving vehicles will be subjected to very complex images. Locating and identifying every object will undoubtedly be a critical part of their autonomy.
The architecture required for object detection differs in an important way. Namely, the size of the output vector is not fixed. If there is a single object in the picture, for example, then there will be four coordinates that define the bounding box. This static and predefined value works using the previously mentioned architectures. However, as the number of objects increases, the number of coordinates increases as well. Especially given that the number of objects is not known in advance, this requires adjustments in the makeup of the neural network.
One such modified architecture is the R-CNN: Regions with CNN features. This approach involves generating regions of interest that are scaled to a fixed size and then forwarding these regions into a model such as AlexNet. While this system produces good results, it is computationally expensive, and too slow for a real-time computer vision system.
With the goal of speeding up R-CNN, there have been various adjustments made to the architecture. The first is Fast R-CNN, which contains optimizations and other innovations that improve both speed and detection accuracy. Taking it one step further, the next generation, Faster R-CNN model, includes an additional CNN named the Region Proposal Network (RPN).
The RPN is trained to generate high-quality regions that are submitted to the Fast R-CNN model. The combination of these algorithms leads to an impressive increase in speed and is truly on the path towards real-time object detection in computer vision systems.

(Source: Image Reconstruction and Colorization. Source: NVIDIA and blog.floydhub.com)
To this point, the tasks have been focused on operations that can work with a single, still image. A vital goal in computer vision, however, is to have the ability to recognize an event that is occurring over a period of time. With a single picture to visually describe the events at one instant in time, it requires a series of pictures to gain a greater understanding of the whole.
Object Tracking is one such example, where the goal is to keep track of a specific object in a sequence of images, or a video. The snapshot that begins the sequence contains the object with a bounding box, and the tracking algorithm outputs a bounding box for all of the subsequent frames. Ideally, the bounding box will perfectly encapsulate the same object for as long as it is visible. Moreover, if the object should become obscured and then re-appear, the tracking should be maintained. For the purpose of this discussion, we can assume that the input to an object tracking algorithm is the output from an object detection algorithm.
Object tracking is important for virtually every computer vision system that contains multiple images. In self-driving cars, for example, pedestrians and other vehicles generally have to be avoided at a very high priority. Tracking objects as they move will not only help to avoid collisions through the use of split-second maneuvers, but also, the model can supply relevant information to other systems that will attempt to predict their next move.
The Open Source Computer Vision Library, OpenCV, contains an object tracking API. There are several algorithms available, each of which performs differently depending on the characteristics of the video, as well as the object itself. For example, some algorithms perform better when the object being tracked becomes momentarily obstructed. OpenCV contains both classic and state-of-the-art algorithms to handle many tasks in computer vision, and is a useful resource for developing such systems.
![]()
(Source: neurohive.io)
Computer vision is an interesting and important field that has a variety of applications across domains. Their effective use is not simply relevant, but rather, required and critical for further developing applications such as autonomous robots and vehicles.
Traditional computer vision systems are not only slow but rather inflexible. They require a great deal of input from the developer and do not easily adjust to new environments. Deep learning systems, on the other hand, handle computer vision tasks end-to-end and do not require external information or coaching to the same degree.
Advancements in deep learning systems and computing power have helped to improve the speed, accuracy, and overall reliability of computer vision systems. As deep learning models improve and computing power becomes more readily available, we will continue to make steady progress towards autonomous systems that can truly interpret and react to what they perceive.
An introduction to Computer Vision and how Deep Learning has helped it advance.
Computer Vision refers to the entire process of emulating human vision in a non-biological apparatus. This includes the initial capturing of images, the detection and identification of objects, recognizing the temporal context between scenes, and developing a high-level understanding of what is happening for the relevant time period.
This technology has long been commonplace in science fiction, and as such, is often taken for granted. In reality, a system to provide reliable, accurate, and real-time computer vision is a challenging problem that has yet to be fully developed.
As these systems mature, there will be countless applications that rely on computer vision as a key component. Examples of this are self-driving cars, autonomous robots, unmanned aerial vehicles, intelligent medical imaging devices that assist with surgery, and surgical implants that restore human sight.
While computer vision holds great promise for the future, it carries an inherent complexity that has always been challenging for a computer. Part of the complexity is borne of the fact that computer vision is not a single task. Rather, it is a series of not-so-simple tasks that each demands the use of intricate algorithms and enough computing power to operate in real time.
From a high level, the sub-tasks that comprise computer vision are object detection and segmentation, image classification, object tracking, labeling images with meaningful descriptions (i.e. image captioning), and finally, understanding the meaning of the entire scene.
Traditional computer vision systems are an amalgamation of algorithms that work together in an attempt to solve the aforementioned tasks. The main goal is to extract features from the image, which involves sub-tasks such as edge detection, corner detection, and segmentation based on coloring. The accuracy of the algorithms used for feature extraction depends on the design and flexibility of each.
Examples of traditional feature extraction algorithms are Scale-invariant feature transform (SIFT), Speeded up robust features (SURF), and Binary Robust Independent Elementary Features (BRIEF). Different algorithms perform with varying degrees of success, depending on the type and quality of the images being used as input. Ultimately, the accuracy of the entire system depends on the methods used to extract features. Once the features have been extracted, the analysis is taken over by traditional Machine Learning methods.
The main problem with this approach is that the system needs to be told which features to look for in the image. Essentially, given that the algorithm operates as defined by the algorithm designer, the extracted features are human-engineered. In such implementations, the poor performance of an algorithm can be addressed through fine-tuning, such as by tweaking parameters, or code-level modifications to adjust the behavior. Changes such as this, however, need to be done manually and are hardcoded, or fixed, for a specific application.
While there are still significant obstacles in the path of human-quality computer vision, Deep Learning systems have made significant progress in dealing with some of the relevant sub-tasks. The reason for this success is partly based on the additional responsibility assigned to deep learning systems.
It is reasonable to say that the biggest difference with deep learning systems is that they no longer need to be programmed to specifically look for features. Rather than searching for specific features by way of a carefully programmed algorithm, the neural networks inside deep learning systems are trained. For example, if cars in an image keep being misclassified as motorcycles then you don’t fine-tune parameters or re-write the algorithm. Instead, you continue training until the system gets it right.
With the increased computational power offered by modern-day deep learning systems, there is steady and noticeable progress towards the point where a computer will be able to recognize and react to everything that it sees.
Classification is the process of predicting a specific class, or label, for something that is defined by a set of data points. Machine learning systems build predictive models that have enormous, yet often unseen benefits for people. For example, the reliable classification of spam email means that the average inbox is less burdened and more manageable. While the average end-user is likely unaware of the complexity of the problem and the vast amount of processing required to mitigate it, the benefits are clear.
Image classification is a subset of the classification problem, where an entire image is assigned a label. Perhaps a picture will be classified as a daytime or nighttime shot. Or, in a similar way, images of cars and motorcycles will be automatically placed into their own groups.
There are countless categories, or classes, in which a specific image can be classified. Consider a manual process where images are compared and similar ones are grouped according to like-characteristics, but without necessarily knowing in advance what you are looking for. Obviously, this is an onerous task. To make it even more so, assume that the set of images numbers in the hundreds of thousands. It becomes readily apparent that an automatic system is needed in order to do this quickly and efficiently.
The deep learning architecture for image classification generally includes convolutional layers, making it a convolutional neural network (CNN). Several hyperparameters, such that the number of convolutional layers and the activation function for each layer, will have to be set. This is a non-trivial part of the process that it outside of the scope of this discussion. However, as a starting point, one can usually select these values based on existing research.
On such system is AlexNet, which is a CNN that gained attention when it won the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Another well-studied model is the Residual Neural Network (ResNet), which later won the same challenge, as well as the Microsoft Common Objects in Context (MS COCO) competition, in 2015.
The second application of deep learning for computer vision is Image Classification with Localization. This problem is a specialization of image classification, with the additional requirement that the object within the picture is first located, and then a bounding box is drawn around it.
This is a more difficult problem than image classification, and it begins with determining whether there is only a single object depicted. If so, or if the number of objects is known, then the goal is to locate each object and identify the four corners of the corresponding bounding box.
This process would be a necessary step in a system responsible for vehicle identification. Consider an automated system that browses pictures of cars, and it is guaranteed that there is a single vehicle contained within the scene. Once the vehicle has been located, properties such as the make, model, and color can be identified.
This task can be accomplished by using a popular deep learning model, such as AlexNet or ResNet, and modifying the fully connected layer to create the bounding box. As mentioned previously, there may be some fine-tuning to do in terms of setting hyperparameters or modifying the architecture for efficiency in a particular domain, but in practice, the basic architectures perform well. It will be necessary to have sufficient training data that includes examples with both the object description and the bounding box clearly defined, although sample datasets are available for this purpose.
The difficulty with this task comes about when there is an unknown number of objects in the picture. In the majority of images, especially those taken in public areas, there will be many possibilities such as different people, vehicles, trees, and animals. For this kind of environment, the problem becomes one of object detection.
Source: CS231n (Stanford Lecture Slides)
Object Detection is image classification with localization, but in pictures that may contain multiple objects. This is an active and important area of research because the computer vision systems that will be used in robotics and self-driving vehicles will be subjected to very complex images. Locating and identifying every object will undoubtedly be a critical part of their autonomy.
The architecture required for object detection differs in an important way. Namely, the size of the output vector is not fixed. If there is a single object in the picture, for example, then there will be four coordinates that define the bounding box. This static and predefined value works using the previously mentioned architectures. However, as the number of objects increases, the number of coordinates increases as well. Especially given that the number of objects is not known in advance, this requires adjustments in the makeup of the neural network.
One such modified architecture is the R-CNN: Regions with CNN features. This approach involves generating regions of interest that are scaled to a fixed size and then forwarding these regions into a model such as AlexNet. While this system produces good results, it is computationally expensive, and too slow for a real-time computer vision system.
With the goal of speeding up R-CNN, there have been various adjustments made to the architecture. The first is Fast R-CNN, which contains optimizations and other innovations that improve both speed and detection accuracy. Taking it one step further, the next generation, Faster R-CNN model, includes an additional CNN named the Region Proposal Network (RPN).
The RPN is trained to generate high-quality regions that are submitted to the Fast R-CNN model. The combination of these algorithms leads to an impressive increase in speed and is truly on the path towards real-time object detection in computer vision systems.
(Source: Image Reconstruction and Colorization. Source: NVIDIA and blog.floydhub.com)
To this point, the tasks have been focused on operations that can work with a single, still image. A vital goal in computer vision, however, is to have the ability to recognize an event that is occurring over a period of time. With a single picture to visually describe the events at one instant in time, it requires a series of pictures to gain a greater understanding of the whole.
Object Tracking is one such example, where the goal is to keep track of a specific object in a sequence of images, or a video. The snapshot that begins the sequence contains the object with a bounding box, and the tracking algorithm outputs a bounding box for all of the subsequent frames. Ideally, the bounding box will perfectly encapsulate the same object for as long as it is visible. Moreover, if the object should become obscured and then re-appear, the tracking should be maintained. For the purpose of this discussion, we can assume that the input to an object tracking algorithm is the output from an object detection algorithm.
Object tracking is important for virtually every computer vision system that contains multiple images. In self-driving cars, for example, pedestrians and other vehicles generally have to be avoided at a very high priority. Tracking objects as they move will not only help to avoid collisions through the use of split-second maneuvers, but also, the model can supply relevant information to other systems that will attempt to predict their next move.
The Open Source Computer Vision Library, OpenCV, contains an object tracking API. There are several algorithms available, each of which performs differently depending on the characteristics of the video, as well as the object itself. For example, some algorithms perform better when the object being tracked becomes momentarily obstructed. OpenCV contains both classic and state-of-the-art algorithms to handle many tasks in computer vision, and is a useful resource for developing such systems.
![]()
(Source: neurohive.io)
Computer vision is an interesting and important field that has a variety of applications across domains. Their effective use is not simply relevant, but rather, required and critical for further developing applications such as autonomous robots and vehicles.
Traditional computer vision systems are not only slow but rather inflexible. They require a great deal of input from the developer and do not easily adjust to new environments. Deep learning systems, on the other hand, handle computer vision tasks end-to-end and do not require external information or coaching to the same degree.
Advancements in deep learning systems and computing power have helped to improve the speed, accuracy, and overall reliability of computer vision systems. As deep learning models improve and computing power becomes more readily available, we will continue to make steady progress towards autonomous systems that can truly interpret and react to what they perceive.
