HPC
Defining Low Precision Floating Point - What is FP8, FP6, FP4?
January 15, 2026
9 min read


Floating point precision is a method of representing numbers in binary format. Computers interpret numbers as binary sequences of 1s and 0s. We went over floating point Half Precision (FP16), Single Precision (FP32), and Double Precision (FP64) in a previous blog. This blog focuses on less common, lower-precision formats: FP8, FP6, and FP4 that are more geared towards neural networks and AI.
In floating point representation, the first binary digit indicates whether the number is positive or negative (the sign bit). The next group of digits forms the exponent, which uses base 2 to represent the magnitude of the number. The final group of digits is the mantissa (also called the significand), which represents the fractional part of the number. In these lower precision formats, the goal isn't to preserve mathematical accuracy but to save every little bit of compute, memory, and bandwidth all in favor of AI responsiveness and performance.
First, we should explain why floating precision became less precise. Modern neural networks are not limited by math — they are limited by data movement.
Moving weights and activations through memory costs far more time and energy than multiplying them. As models scale, especially large language models, performance becomes dominated by memory bandwidth, cache capacity, and power, not floating-point throughput. Lowering numerical precision is one of the most effective ways to relieve these bottlenecks.
This is why the industry moved from FP32 to FP16 and BF16 — and why that still wasn’t enough.
Reducing precision:
AI neural network training can tolerate approximation. They are purposely trained with noise, optimized with stochastic methods, and evaluated on aggregate behavior rather than exact numerical correctness. Precision, therefore, becomes a budget to be spent carefully, not a fixed requirement.
Instead of “what precision should be used?” it became “where does precision matter?”
FP8 refers to a family of 8-bit floating-point formats, not a single standard. Like larger IEEE floating-point types, FP8 values has two versions: E4M3 and E5M2 (which make them quite self-explanatory).
At 8 bits, a single format cannot adequately cover both range and precision. Modern hardware and frameworks, therefore, mix FP8 variants:
In practice, FP8 values are rarely used in isolation. Computation is typically performed in FP8, while accumulation happens in FP16 or FP32, preserving stability despite the aggressive reduction in storage and compute precision.
FP8’s adoption in many AI accelerators is due to its ability fit into mixed-precision workloads.
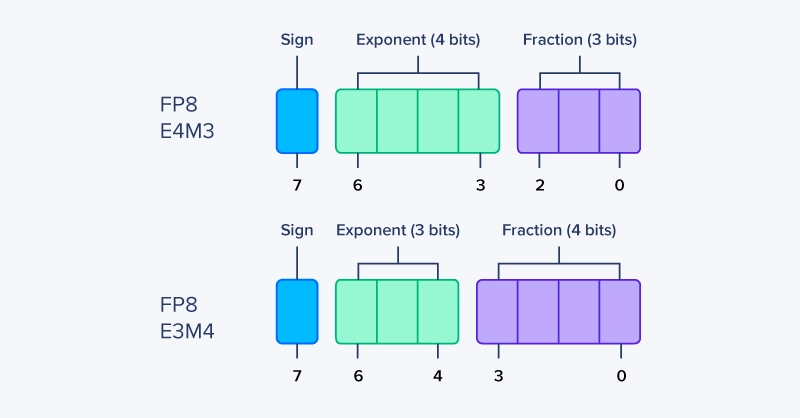
FP8 E4M3 prioritizes precision over range. With more mantissa bits, it represents values near zero more accurately, making it well-suited for activations and gradients with relatively tight distributions. It uses:
FP8 E5M2 shifts bits from the mantissa to the exponent, increasing representable range at the cost of precision. This makes it more robust to outliers and large dynamic ranges, which are common in weights and intermediate results. It uses:

Empower your hardware with a purpose-built HPC platform validated by NVIDIA. NVIDIA MGX is a reference design platform by NVIDIA built to propel and accelerate your research in HPC and AI, built to extract the best performance out of NVIDIA hardware.
Get a Quote TodayFP6 is not a single, standardized format, but a class of 6-bit floating-point representations. Like FP8, FP6 values are composed of a sign, exponent, and mantissa — but with only six total bits, the gains and tradeoffs are exaggerated.
While implementations vary, most FP6 proposals follow this general pattern:
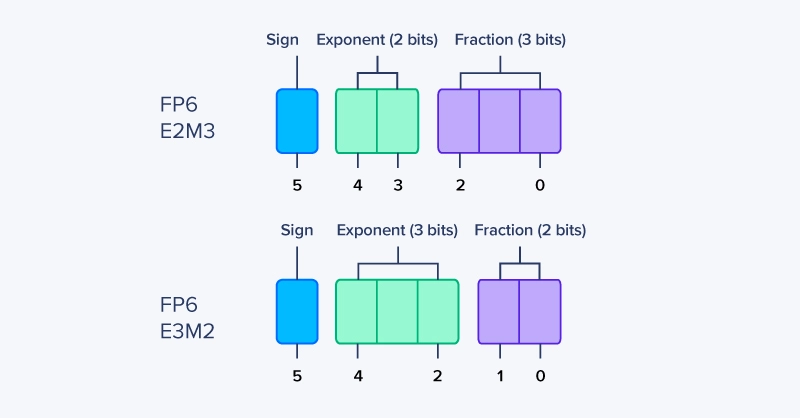
Different exponent/mantissa splits target different use cases, but all FP6 formats suffer from extremely limited range or precision — often both. Unlike FP8, there is little room to balance range and precision within a single format. As a result, FP6 almost always requires aggressive scaling and careful value distribution control.
The efficiency gains over FP8 are modest, while the complexity cost is high. In many cases, FP8 captures most of the available performance and memory benefits without pushing numerical stability to the breaking point.
FP6 is primarily viable when:
FP4 is the most aggressive floating-point format in practical discussion today. With only 4 total bits, FP4 pushes floating point to its absolute limits and exists almost entirely to satisfy hardware throughput and density goals. So far, only NVIDIA Blackwell Generation GPUs have native FP4 support.
There is no single FP4 standard, but typical designs use:
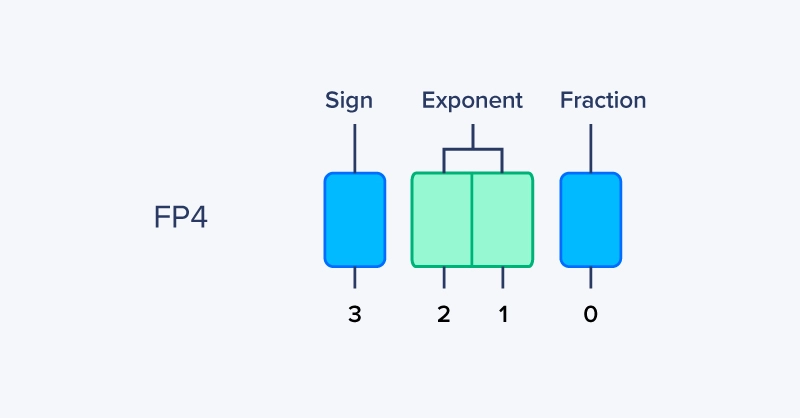
Some variants alter the exponent bias or remove special values entirely. Regardless of the exact layout, FP4 is extremely limited in range with almost no precision. FP4 is for maximizing Tensor Core throughput and minimizing memory bandwidth by enabling extremely high calculation density.
From a numerical perspective, FP4 is not intended to stand alone. It is a compute format, not a storage or accumulation format. When FP4 appears in hardware specifications:
This mirrors the broader trend: ever-lower precision for compute, paired with higher precision where error accumulation matters.
As a result, FP4 is best viewed as a hardware capability, not a generally usable numerical format. Its inclusion in NVIDIA's GPU specifications signals where their GPUs push performance, not where most models can operate today. Reduced bit length during calculations result in less complexity and faster completion that compound over trillions of calculations a GPU has to make during AI training and inference.
Modern AI systems do not run at a single precision. They deliberately mix precisions across storage, compute, and accumulation, placing higher precision only where numerical error would otherwise compound.
This is why extremely low-precision formats are viable at all:
The effectiveness of a precision format depends less on its bit width and more on where it is used in the pipeline.
Lower precision is not about sacrificing correctness everywhere. It is about spending precision where it matters and reclaiming efficiency everywhere else.
Neural networks are inherently tolerant to noise. As long as accumulation and scaling are handled correctly, small numerical errors introduced during low-precision compute do not significantly affect final outputs.
Floating-point formats preserve dynamic range, which is critical for activations and gradients. Integer formats require explicit calibration and struggle with rapidly changing value distributions.
Errors compound during accumulation. Using FP16 or FP32 for accumulation prevents small rounding errors from dominating the result, even when inputs are extremely low precision.
FP4 has extremely limited range and precision. Without strict scaling and tightly controlled distributions, numerical error grows too large for most models to tolerate.
Use FP8 for most low-precision compute, FP6 only for specialized or experimental setups, and treat FP4 as a hardware optimization rather than a general-purpose numerical format.
Low-precision floating-point formats shine wherever throughput, latency, or power dominate:
The common thread is not the application domain, but the constraint: when moving data costs more than computing on it, low-precision formats deliver outsized gains.
As hardware and software continue to co-evolve, the future of numerical formats will be defined less by IEEE standards and more by how effectively precision is spent.

With access to the highest-performing hardware, Exxact offers customizable platforms for AMBER, GROMACS, NAMD, and more. Every Exxact system is optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Configure your Ideal GPU System for Life Science ResearchFloating point precision is a method of representing numbers in binary format. Computers interpret numbers as binary sequences of 1s and 0s. We went over floating point Half Precision (FP16), Single Precision (FP32), and Double Precision (FP64) in a previous blog. This blog focuses on less common, lower-precision formats: FP8, FP6, and FP4 that are more geared towards neural networks and AI.
In floating point representation, the first binary digit indicates whether the number is positive or negative (the sign bit). The next group of digits forms the exponent, which uses base 2 to represent the magnitude of the number. The final group of digits is the mantissa (also called the significand), which represents the fractional part of the number. In these lower precision formats, the goal isn't to preserve mathematical accuracy but to save every little bit of compute, memory, and bandwidth all in favor of AI responsiveness and performance.
First, we should explain why floating precision became less precise. Modern neural networks are not limited by math — they are limited by data movement.
Moving weights and activations through memory costs far more time and energy than multiplying them. As models scale, especially large language models, performance becomes dominated by memory bandwidth, cache capacity, and power, not floating-point throughput. Lowering numerical precision is one of the most effective ways to relieve these bottlenecks.
This is why the industry moved from FP32 to FP16 and BF16 — and why that still wasn’t enough.
Reducing precision:
AI neural network training can tolerate approximation. They are purposely trained with noise, optimized with stochastic methods, and evaluated on aggregate behavior rather than exact numerical correctness. Precision, therefore, becomes a budget to be spent carefully, not a fixed requirement.
Instead of “what precision should be used?” it became “where does precision matter?”
FP8 refers to a family of 8-bit floating-point formats, not a single standard. Like larger IEEE floating-point types, FP8 values has two versions: E4M3 and E5M2 (which make them quite self-explanatory).
At 8 bits, a single format cannot adequately cover both range and precision. Modern hardware and frameworks, therefore, mix FP8 variants:
In practice, FP8 values are rarely used in isolation. Computation is typically performed in FP8, while accumulation happens in FP16 or FP32, preserving stability despite the aggressive reduction in storage and compute precision.
FP8’s adoption in many AI accelerators is due to its ability fit into mixed-precision workloads.
FP8 E4M3 prioritizes precision over range. With more mantissa bits, it represents values near zero more accurately, making it well-suited for activations and gradients with relatively tight distributions. It uses:
FP8 E5M2 shifts bits from the mantissa to the exponent, increasing representable range at the cost of precision. This makes it more robust to outliers and large dynamic ranges, which are common in weights and intermediate results. It uses:
Empower your hardware with a purpose-built HPC platform validated by NVIDIA. NVIDIA MGX is a reference design platform by NVIDIA built to propel and accelerate your research in HPC and AI, built to extract the best performance out of NVIDIA hardware.
Get a Quote TodayFP6 is not a single, standardized format, but a class of 6-bit floating-point representations. Like FP8, FP6 values are composed of a sign, exponent, and mantissa — but with only six total bits, the gains and tradeoffs are exaggerated.
While implementations vary, most FP6 proposals follow this general pattern:
Different exponent/mantissa splits target different use cases, but all FP6 formats suffer from extremely limited range or precision — often both. Unlike FP8, there is little room to balance range and precision within a single format. As a result, FP6 almost always requires aggressive scaling and careful value distribution control.
The efficiency gains over FP8 are modest, while the complexity cost is high. In many cases, FP8 captures most of the available performance and memory benefits without pushing numerical stability to the breaking point.
FP6 is primarily viable when:
FP4 is the most aggressive floating-point format in practical discussion today. With only 4 total bits, FP4 pushes floating point to its absolute limits and exists almost entirely to satisfy hardware throughput and density goals. So far, only NVIDIA Blackwell Generation GPUs have native FP4 support.
There is no single FP4 standard, but typical designs use:
Some variants alter the exponent bias or remove special values entirely. Regardless of the exact layout, FP4 is extremely limited in range with almost no precision. FP4 is for maximizing Tensor Core throughput and minimizing memory bandwidth by enabling extremely high calculation density.
From a numerical perspective, FP4 is not intended to stand alone. It is a compute format, not a storage or accumulation format. When FP4 appears in hardware specifications:
This mirrors the broader trend: ever-lower precision for compute, paired with higher precision where error accumulation matters.
As a result, FP4 is best viewed as a hardware capability, not a generally usable numerical format. Its inclusion in NVIDIA's GPU specifications signals where their GPUs push performance, not where most models can operate today. Reduced bit length during calculations result in less complexity and faster completion that compound over trillions of calculations a GPU has to make during AI training and inference.
Modern AI systems do not run at a single precision. They deliberately mix precisions across storage, compute, and accumulation, placing higher precision only where numerical error would otherwise compound.
This is why extremely low-precision formats are viable at all:
The effectiveness of a precision format depends less on its bit width and more on where it is used in the pipeline.
Lower precision is not about sacrificing correctness everywhere. It is about spending precision where it matters and reclaiming efficiency everywhere else.
Neural networks are inherently tolerant to noise. As long as accumulation and scaling are handled correctly, small numerical errors introduced during low-precision compute do not significantly affect final outputs.
Floating-point formats preserve dynamic range, which is critical for activations and gradients. Integer formats require explicit calibration and struggle with rapidly changing value distributions.
Errors compound during accumulation. Using FP16 or FP32 for accumulation prevents small rounding errors from dominating the result, even when inputs are extremely low precision.
FP4 has extremely limited range and precision. Without strict scaling and tightly controlled distributions, numerical error grows too large for most models to tolerate.
Use FP8 for most low-precision compute, FP6 only for specialized or experimental setups, and treat FP4 as a hardware optimization rather than a general-purpose numerical format.
Low-precision floating-point formats shine wherever throughput, latency, or power dominate:
The common thread is not the application domain, but the constraint: when moving data costs more than computing on it, low-precision formats deliver outsized gains.
As hardware and software continue to co-evolve, the future of numerical formats will be defined less by IEEE standards and more by how effectively precision is spent.
With access to the highest-performing hardware, Exxact offers customizable platforms for AMBER, GROMACS, NAMD, and more. Every Exxact system is optimized for your deployment, budget, and desired performance so you can make an impact with your research!
Configure your Ideal GPU System for Life Science Research