HPC
Comparing NVIDIA Tensor Core GPUs - NVIDIA B300, B200, H200, H100, A100
November 14, 2025
6 min read


Formally under the Tesla family moniker, NVIDIA Tensor Core GPUs are the gold standard GPU for AI computations due to its unique architecture designed specifically to execute the calculations found in AI and neural networks.
Tensors are AI's most fundamental data type and are a multidimensional array of defined weights. To calculate these arrays, matrix multiplication is run extensively to update weights and enable neural networks to learn.
Tensor Cores were first introduced in the Tesla V100. Still, to improve the marketing behind their flagship GPUs, in the next GPU generation Ampere, NVIDIA ditched the Tesla name in favor of the Tensor Core GPU naming convention. The NVIDIA A100 Tensor Core GPU was a revolutionary high-performance GPU dedicated to accelerating AI computations.
It’s 2025, nearing 2026, and NVIDIA’s lineup of Tensor Core GPUs has expanded. We want to offer a full-scale comparison of the specifications of the GPUs and comprehensive recommendations for deploying the world’s most powerful GPU for AI. For reference, we will be focusing on the SXM variants of each GPU, which can be found in the NVIDIA DGX or the NVIDIA HGX platforms.
Read this blog to learn more about the various NVIDIA Blackwell Deployments.
Before we get into the details, it is worth noting that A100 is EOL, and the H100 has been supplanted by the H200. Existing stock of H100 may still be available; the H200 will supersede any new orders. The NVIDIA B300 and B200 are now available in 2025. For those who need FP64, B200. For those who need more memory and increased FP4 Dense, choose the NVIDIA B300.
Although some GPUs are EOL, for those who have existing deployments, we include the legacy NVIDIA A100 and NVIDIA H100 for easy comparison.
| Architecture | Blackwell Ultra | Blackwell | Hopper | Hopper | Ampere |
| GPU Name | NVIDIA B300 | NVIDIA B200 | NVIDIA H200 | NVIDIA H100 | NVIDIA A100 |
| FP64 | 1.2 teraFLOPS | 37 teraFLOPS | 34 teraFLOPS | 34 teraFLOPS | 9.7 teraFLOPS |
| FP64 Tensor Core | 1.2 teraFLOPS | 37 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 | 75 teraFLOPS | 75 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 Tensor Core | 2.2 petaFLOPS | 2.2 petaFLOPS | 989 teraFLOPS | 989 teraFLOPS | 312 teraFLOPS |
| FP16/BF16 Tensor Core | 4.5 petaFLOPS | 4.5 petaFLOPS | 2 peraFLOPS | 2 peraFLOPS | 624 teraFLOPS |
| INT8 Tensor Core | 9 petaOPs | 9 petaOPs | 4 petaOPs | 4 petaOPs | 1248 teraOPs |
| FP8/FP6 Tensor Core | 9 petaFLOPS | 9 petaFLOPS | 4 petaFLOPS | 4 petaFLOPS | - |
| FP4 Tensor Core (Sparse | Dense) | 18 | 14 petaFLOPS | 18 | 9 petaFLOPS | - | - | - |
| GPU Memory | 270GB HBM3e | 192GB HBM3e | 141GB HBM3e | 80GB HBM3 | 80GB HBM2e |
| NVIDIA HGX 8x GPU Memory | 2.1TB Total | 1.4TB Total | 1.1TB Total | 640GB Total | 640GB Total |
| Memory Bandwidth | Up to 7.7TB/s | Up to 7.7TB/s | 4.8TB/s | 3.2TB/s | 2TB/s |
| Decoders | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 5 NVDEC 5 JPEG |
| Multi-Instance GPUs | Up to 7 MIGs @23GB | Up to 7 MIGs @23GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @ 10GB |
| Interconnect | NVLink 1.8TB/s | NVLink 1.8TB/s | NVLink 900GB/s | NVLink 900GB/s | NVLink 600GB/s |
| NVIDIA AI Enterprise | Yes | Yes | Yes | Yes | EOL |
Looking at the raw performance defined by the number of floating-point operations performed per second at a given precision, the NVIDIA Blackwell GPUs sacrifice FP64 Tensor Core performance in favor of heavily increased Tensor Core performance in FP32 and below. The NVIDIA B300 doubles down and has extremely low FP64 performance in favor for additional FP4 performance.
Training AI doesn’t require the high 64-bit precision for calculating weights and parameters. By sacrificing FP64 Tensor Core performance, NVIDIA squeezes more juice out when calculating on the more standard 32-bit, 16-bit, FP8/FP6, and FP4 precision formats.
The NVIDIA B300 and B200 throughput is over 2x in TF32, FP16, and FP8 than the last generation H200. It also features a new transformer engine that supports FP4. These lower-precision floating-point formats won’t be used in entire calculations, but, when incorporated into Mixed Precision workloads, the performance gains realized are unparalleled.
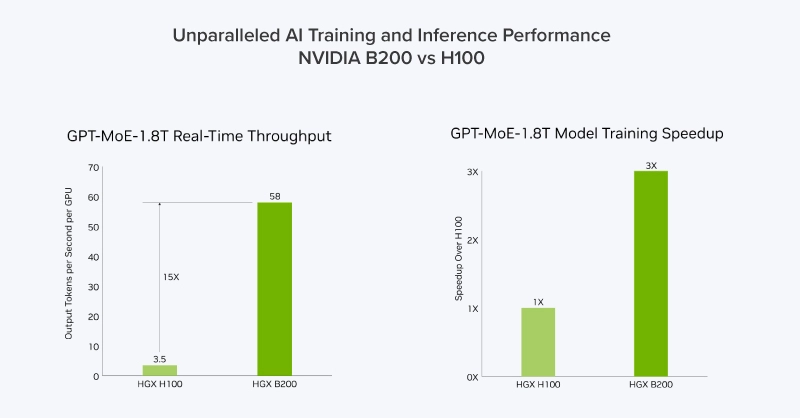
“Newer is always better,” is often true in computer hardware. Upgrading to the latest NVIDIA Tensor Core GPU platform is a strategic decision that depends on your organization’s compute needs, workload type, and long-term infrastructure goals for scalability. While new architectures deliver clear performance gains, the value of upgrading comes from aligning hardware with workload priorities.
While NVIDIA continues to innovate, you can slowly transition towards newer hardware. Be mindful of the return on investment when deploying these machines. Large-scale infrastructures take a long time to develop and need time to realize their value. Even if there is a new generation of Tensor Core GPUs, the past generation of hardware can still deliver exceptional performance.
As elite partners, NVIDIA and Exxact have dedicated experts to get you to your computing infrastructure goals. If you have any questions on how you can better utilize or scale up your NVIDIA hardware, contact Exxact today.

Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote TodayFormally under the Tesla family moniker, NVIDIA Tensor Core GPUs are the gold standard GPU for AI computations due to its unique architecture designed specifically to execute the calculations found in AI and neural networks.
Tensors are AI's most fundamental data type and are a multidimensional array of defined weights. To calculate these arrays, matrix multiplication is run extensively to update weights and enable neural networks to learn.
Tensor Cores were first introduced in the Tesla V100. Still, to improve the marketing behind their flagship GPUs, in the next GPU generation Ampere, NVIDIA ditched the Tesla name in favor of the Tensor Core GPU naming convention. The NVIDIA A100 Tensor Core GPU was a revolutionary high-performance GPU dedicated to accelerating AI computations.
It’s 2025, nearing 2026, and NVIDIA’s lineup of Tensor Core GPUs has expanded. We want to offer a full-scale comparison of the specifications of the GPUs and comprehensive recommendations for deploying the world’s most powerful GPU for AI. For reference, we will be focusing on the SXM variants of each GPU, which can be found in the NVIDIA DGX or the NVIDIA HGX platforms.
Read this blog to learn more about the various NVIDIA Blackwell Deployments.
Before we get into the details, it is worth noting that A100 is EOL, and the H100 has been supplanted by the H200. Existing stock of H100 may still be available; the H200 will supersede any new orders. The NVIDIA B300 and B200 are now available in 2025. For those who need FP64, B200. For those who need more memory and increased FP4 Dense, choose the NVIDIA B300.
Although some GPUs are EOL, for those who have existing deployments, we include the legacy NVIDIA A100 and NVIDIA H100 for easy comparison.
| Architecture | Blackwell Ultra | Blackwell | Hopper | Hopper | Ampere |
| GPU Name | NVIDIA B300 | NVIDIA B200 | NVIDIA H200 | NVIDIA H100 | NVIDIA A100 |
| FP64 | 1.2 teraFLOPS | 37 teraFLOPS | 34 teraFLOPS | 34 teraFLOPS | 9.7 teraFLOPS |
| FP64 Tensor Core | 1.2 teraFLOPS | 37 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 | 75 teraFLOPS | 75 teraFLOPS | 67 teraFLOPS | 67 teraFLOPS | 19.5 teraFLOPS |
| FP32 Tensor Core | 2.2 petaFLOPS | 2.2 petaFLOPS | 989 teraFLOPS | 989 teraFLOPS | 312 teraFLOPS |
| FP16/BF16 Tensor Core | 4.5 petaFLOPS | 4.5 petaFLOPS | 2 peraFLOPS | 2 peraFLOPS | 624 teraFLOPS |
| INT8 Tensor Core | 9 petaOPs | 9 petaOPs | 4 petaOPs | 4 petaOPs | 1248 teraOPs |
| FP8/FP6 Tensor Core | 9 petaFLOPS | 9 petaFLOPS | 4 petaFLOPS | 4 petaFLOPS | - |
| FP4 Tensor Core (Sparse | Dense) | 18 | 14 petaFLOPS | 18 | 9 petaFLOPS | - | - | - |
| GPU Memory | 270GB HBM3e | 192GB HBM3e | 141GB HBM3e | 80GB HBM3 | 80GB HBM2e |
| NVIDIA HGX 8x GPU Memory | 2.1TB Total | 1.4TB Total | 1.1TB Total | 640GB Total | 640GB Total |
| Memory Bandwidth | Up to 7.7TB/s | Up to 7.7TB/s | 4.8TB/s | 3.2TB/s | 2TB/s |
| Decoders | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 7 NVDEC 7 JPEG | 5 NVDEC 5 JPEG |
| Multi-Instance GPUs | Up to 7 MIGs @23GB | Up to 7 MIGs @23GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @16.5GB | Up to 7 MIGs @ 10GB |
| Interconnect | NVLink 1.8TB/s | NVLink 1.8TB/s | NVLink 900GB/s | NVLink 900GB/s | NVLink 600GB/s |
| NVIDIA AI Enterprise | Yes | Yes | Yes | Yes | EOL |
Looking at the raw performance defined by the number of floating-point operations performed per second at a given precision, the NVIDIA Blackwell GPUs sacrifice FP64 Tensor Core performance in favor of heavily increased Tensor Core performance in FP32 and below. The NVIDIA B300 doubles down and has extremely low FP64 performance in favor for additional FP4 performance.
Training AI doesn’t require the high 64-bit precision for calculating weights and parameters. By sacrificing FP64 Tensor Core performance, NVIDIA squeezes more juice out when calculating on the more standard 32-bit, 16-bit, FP8/FP6, and FP4 precision formats.
The NVIDIA B300 and B200 throughput is over 2x in TF32, FP16, and FP8 than the last generation H200. It also features a new transformer engine that supports FP4. These lower-precision floating-point formats won’t be used in entire calculations, but, when incorporated into Mixed Precision workloads, the performance gains realized are unparalleled.
“Newer is always better,” is often true in computer hardware. Upgrading to the latest NVIDIA Tensor Core GPU platform is a strategic decision that depends on your organization’s compute needs, workload type, and long-term infrastructure goals for scalability. While new architectures deliver clear performance gains, the value of upgrading comes from aligning hardware with workload priorities.
While NVIDIA continues to innovate, you can slowly transition towards newer hardware. Be mindful of the return on investment when deploying these machines. Large-scale infrastructures take a long time to develop and need time to realize their value. Even if there is a new generation of Tensor Core GPUs, the past generation of hardware can still deliver exceptional performance.
As elite partners, NVIDIA and Exxact have dedicated experts to get you to your computing infrastructure goals. If you have any questions on how you can better utilize or scale up your NVIDIA hardware, contact Exxact today.
Training AI models on massive datasets can be accelerated exponentially with the right system. It's not just a high-performance computer, but a tool to propel and accelerate your research. Deploy multiple NVIDIA DGX nodes for increased scalability. DGX B200 and DGX B300 is available today!
Get a Quote Today