News
NVIDIA Announces Tesla P4 and P40 GPU Accelerators for Neural Network Inferencing
September 22, 2016
5 min read

.jpg?format=webp)
Last week at China GTC 2016, NVIDIA unveiled its latest additions to the Pascal architecture-based deep learning platform: the NVIDIA Tesla P4 and P40 GPU Accelerators. The two cards are the direct successors to the current gen Tesla M4 and M40 GPUs and are set to deliver massive performance improvements in growing fields such as artificial intelligence.
The Tesla P4 and P40 cards were specifically designed to increase speed and efficiency for AI inferencing production workloads as current CPU technology cannot deliver the real-time responsiveness required for modern services. These services may include everyday tools such as email spam filters or voice-activated assistance systems, which are becoming more intricate every year and have begun requiring up to 10x more computing power when compared to neural networks from a year ago. To address this, NVIDIA claims that the Tesla P4 and P40 GPUs are capable of delivering 45x faster response times than current gen CPUs and 4x performance improvements over GPU solutions less than a year old.
Let's take a look at the Tesla P4 and P40 GPU specifications:
Specifications | Tesla P4 | Tesla P40 | Tesla M4 | Tesla M40 |
|---|---|---|---|---|
| Single Precision FLOPS (With Boost Clock) | 5.5 TFLOPS | 12 TFLOPS | 2.2 TFLOPS | 7 TFLOPS |
| INT8 TOPS (Tera-Operations Per Second) | 22 TOPS | 47 TOPS | N/A | N/A |
| Base Clock | 810MHz | 1303MHz | 872MHz | 948MHz |
| Boost Clock | 1063MHz | 1531MHz | 1072MHz | 1114MHz |
| CUDA Cores | 2560 | 3840 | 1024 | 3072 |
| VRAM | 8GB | 24GB | 4GB | 12/24GB |
| Memory Bus Width | 256-bit | 384-bit | 128-bit | 384-bit |
| Power | 50W-75W | 250W | 50W-75W | 250W |
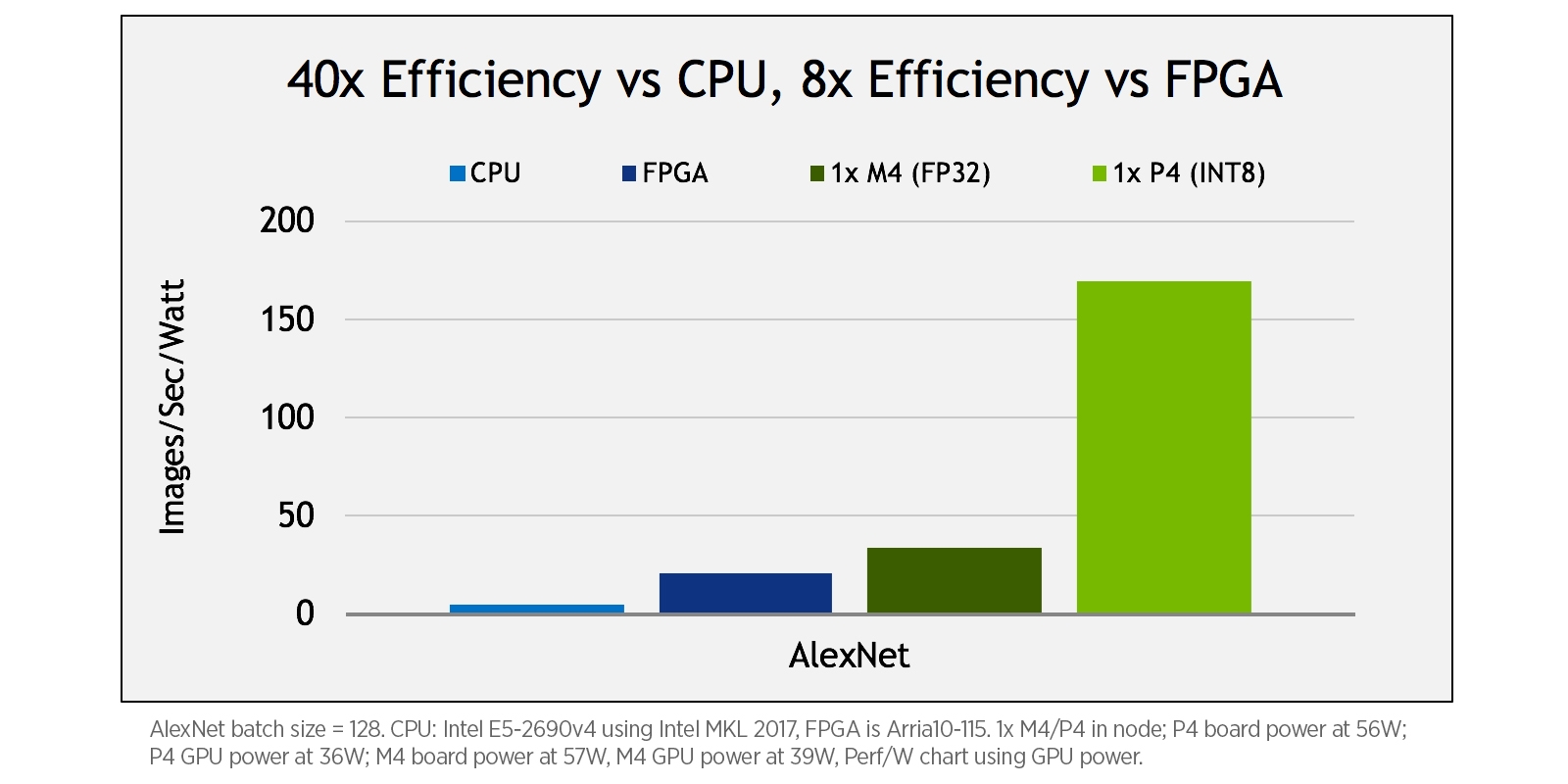
If you're looking for energy efficiency, then the Tesla P4 would be the prime choice. Like the Tesla M4 before it, the P4 comes in a 50 watt, small form factor power design capable of delivering high energy efficiency for data centers. Its low wattage requirements make it 40x more energy efficient than CPUs for inferencing production workloads. NVIDIA has stated that a single server with a single Tesla P4 can replace 13 CPU-only servers for video inferencing workloads which means it saves over 8x in terms of total cost of ownership, including server and power costs. With FP32 performance at 5.5 TFLOPS and INT8 performance at 22 TOPS, the P4 offers a significant increase in performance compared to the M4. The new 8-bit integer (INT8) vector instructions featured in the Tesla P4 provide large efficiency gains for deep learning inference when compared to CPUs and FPGAs, as the figure below shows.
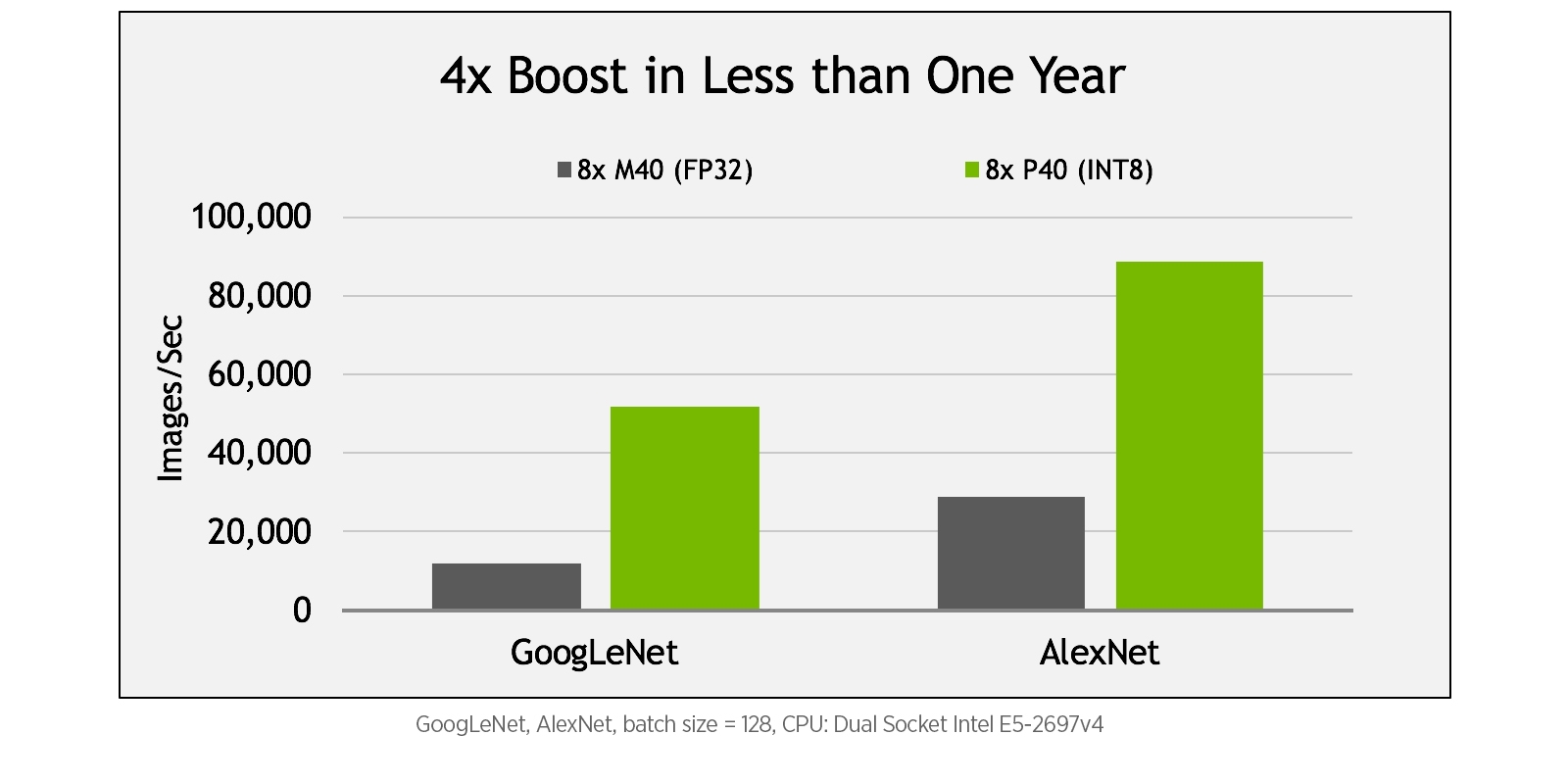
On the other hand, the Tesla P40 is a full performance, 250W GPU designed for high performance servers. It is a fully enabled GP102 GPU, meaning all 3840 CUDA are activated and fully operational. With Peak FP32 performance at 12 TFLOPS and INT8 performance at 47 TOPS, the results are a considerable improvement from the Tesla M40, which only offered 7 TFLOPS at FP32 and no INT8 support. Touting 24GB of GDDR5 memory and the new Pascal architecture, the P40 offers a dramatic performance boost over its predecessor. The Tesla P40 provides speed increases on deep learning inferencing performance up to 4x compared to the M40. The below figure correlates deep learning inference with GoogLeNet and AlexNet on 8x Tesla P40 GPUs (featuring INT8 computation) compared to 8x Tesla M40 GPUs. The P40 clearly shows a performance increase with up to 4x higher throughput.
In addition to the hardware announcements, NVIDIA also announced new software tools to complement the Tesla P4 and P40. With faster inferencing in mind, NVIDIA introduced the NVIDIA TensorRT and the NVIDIA DeepStream SDK to accelerate AI inferencing
• TensorRT: An inference engine library created for optimizing deep learning models for production deployment that delivers instant responsiveness for the most complex networks. It maximizes throughput and efficiency of deep learning applications by taking trained neural nets -- defined with 32-bit or 16-bit operations -- and optimizing them for reduced precision INT8 operations. TensorRT uses INT8 optimized precision to deliver 3x more throughput, using 61% less memory on applications that rely on high accuracy inference.
• NVIDIA DeepStream SDK: A video processing library that taps into the power of a Pascal server to simultaneously decode and analyze up to 93 HD video streams in real time. Developers can use the SDK to rapidly integrate advanced video inference capabilities including optimized precision and GPU-accelerated transcoding to deliver faster, more responsive AI-powered services such as real-time video categorization.
The NVIDIA Tesla P40 GPUs will be available in Exxact servers in October. Meanwhile the Tesla P4 will be available a month later, in November. For preorders or more information, please contact sales here.
Last week at China GTC 2016, NVIDIA unveiled its latest additions to the Pascal architecture-based deep learning platform: the NVIDIA Tesla P4 and P40 GPU Accelerators. The two cards are the direct successors to the current gen Tesla M4 and M40 GPUs and are set to deliver massive performance improvements in growing fields such as artificial intelligence.
The Tesla P4 and P40 cards were specifically designed to increase speed and efficiency for AI inferencing production workloads as current CPU technology cannot deliver the real-time responsiveness required for modern services. These services may include everyday tools such as email spam filters or voice-activated assistance systems, which are becoming more intricate every year and have begun requiring up to 10x more computing power when compared to neural networks from a year ago. To address this, NVIDIA claims that the Tesla P4 and P40 GPUs are capable of delivering 45x faster response times than current gen CPUs and 4x performance improvements over GPU solutions less than a year old.
Let's take a look at the Tesla P4 and P40 GPU specifications:
Specifications | Tesla P4 | Tesla P40 | Tesla M4 | Tesla M40 |
|---|---|---|---|---|
| Single Precision FLOPS (With Boost Clock) | 5.5 TFLOPS | 12 TFLOPS | 2.2 TFLOPS | 7 TFLOPS |
| INT8 TOPS (Tera-Operations Per Second) | 22 TOPS | 47 TOPS | N/A | N/A |
| Base Clock | 810MHz | 1303MHz | 872MHz | 948MHz |
| Boost Clock | 1063MHz | 1531MHz | 1072MHz | 1114MHz |
| CUDA Cores | 2560 | 3840 | 1024 | 3072 |
| VRAM | 8GB | 24GB | 4GB | 12/24GB |
| Memory Bus Width | 256-bit | 384-bit | 128-bit | 384-bit |
| Power | 50W-75W | 250W | 50W-75W | 250W |
If you're looking for energy efficiency, then the Tesla P4 would be the prime choice. Like the Tesla M4 before it, the P4 comes in a 50 watt, small form factor power design capable of delivering high energy efficiency for data centers. Its low wattage requirements make it 40x more energy efficient than CPUs for inferencing production workloads. NVIDIA has stated that a single server with a single Tesla P4 can replace 13 CPU-only servers for video inferencing workloads which means it saves over 8x in terms of total cost of ownership, including server and power costs. With FP32 performance at 5.5 TFLOPS and INT8 performance at 22 TOPS, the P4 offers a significant increase in performance compared to the M4. The new 8-bit integer (INT8) vector instructions featured in the Tesla P4 provide large efficiency gains for deep learning inference when compared to CPUs and FPGAs, as the figure below shows.
On the other hand, the Tesla P40 is a full performance, 250W GPU designed for high performance servers. It is a fully enabled GP102 GPU, meaning all 3840 CUDA are activated and fully operational. With Peak FP32 performance at 12 TFLOPS and INT8 performance at 47 TOPS, the results are a considerable improvement from the Tesla M40, which only offered 7 TFLOPS at FP32 and no INT8 support. Touting 24GB of GDDR5 memory and the new Pascal architecture, the P40 offers a dramatic performance boost over its predecessor. The Tesla P40 provides speed increases on deep learning inferencing performance up to 4x compared to the M40. The below figure correlates deep learning inference with GoogLeNet and AlexNet on 8x Tesla P40 GPUs (featuring INT8 computation) compared to 8x Tesla M40 GPUs. The P40 clearly shows a performance increase with up to 4x higher throughput.
In addition to the hardware announcements, NVIDIA also announced new software tools to complement the Tesla P4 and P40. With faster inferencing in mind, NVIDIA introduced the NVIDIA TensorRT and the NVIDIA DeepStream SDK to accelerate AI inferencing
• TensorRT: An inference engine library created for optimizing deep learning models for production deployment that delivers instant responsiveness for the most complex networks. It maximizes throughput and efficiency of deep learning applications by taking trained neural nets -- defined with 32-bit or 16-bit operations -- and optimizing them for reduced precision INT8 operations. TensorRT uses INT8 optimized precision to deliver 3x more throughput, using 61% less memory on applications that rely on high accuracy inference.
• NVIDIA DeepStream SDK: A video processing library that taps into the power of a Pascal server to simultaneously decode and analyze up to 93 HD video streams in real time. Developers can use the SDK to rapidly integrate advanced video inference capabilities including optimized precision and GPU-accelerated transcoding to deliver faster, more responsive AI-powered services such as real-time video categorization.
The NVIDIA Tesla P40 GPUs will be available in Exxact servers in October. Meanwhile the Tesla P4 will be available a month later, in November. For preorders or more information, please contact sales here.
